Blog Archives
Network Theory and Network Effects
Complexity theory needs to be coupled with network theory to get a more comprehensive grasp of the underlying paradigms that govern the outcomes and morphology of emergent systems. In order for us to understand the concept of network effects which is commonly used to understand platform economics or ecosystem value due to positive network externalities, we would like to take a few steps back and appreciate the fundamental theory of networks. This understanding will not only help us to understand complexity and its emergent properties at a low level but also inform us of the impact of this knowledge on how network effects can be shaped to impact outcomes in an intentional manner.

There are first-order conditions that must be met to gauge whether the subject of the observation is a network. Firstly, networks are all about connectivity within and between systems. Understanding the components that bind the system would be helpful. However, do keep in mind that complexity systems (CPS and CAS) might have emergent properties due to the association and connectivity of the network that might not be fully explained by network theory. All the same, understanding networking theory is a building block to understanding emergent systems and the outcome of its structure on addressing niche and macro challenges in society.
Networks operates spatially in a different space and that has been intentionally done to allow some simplification and subsequent generalization of principles. The geometry of network is called network topology. It is a 2D perspective of connectivity.
Networks are subject to constraints (physical resources, governance constraint, temporal constraints, channel capacity, absorption and diffusion of information, distribution constraint) that might be internal (originated by the system) or external (originated in the environment that the network operates in).
Finally, there is an inherent non-linearity impact in networks. As nodes increase linearly, connections will increase exponentially but might be subject to constraints. The constraints might define how the network structure might morph and how information and signals might be processed differently.
Graph theory is the most widely used tool to study networks. It consists of four parts: vertices which represent an element in the network, edges refer to relationship between nodes which we call links, directionality which refers to how the information is passed ( is it random and bi-directional or follows specific rules and unidirectional), channels that refer to bandwidth that carry information, and finally the boundary which establishes specificity around network operations. A graph can be weighted – namely, a number can be assigned to each length to reflect the degree of interaction or the strength of resources or the proximity of the nodes or the ordering of discernible clusters.
The central concept of network theory thus revolves around connectivity between nodes and how non-linear emergence occurs. A node can have multiple connections with other node/nodes and we can weight the node accordingly. In addition, the purpose of networks is to pass information in the most efficient manner possible which relays into the concept of a geodesic which is either the shortest path between two nodes that must work together to achieve a purpose or the least number of leaps through links that information must negotiate between the nodes in the network.
Technically, you look for the longest path in the network and that constitutes the diameter while you calculate the average path length by examining the shortest path between nodes, adding all of those paths up and then dividing by the number of pairs. Significance of understanding the geodesic allows an understanding of the size of the network and throughput power that the network is capable of.
Nodes are the atomic elements in the network. It is presumed that its degree of significance is related to greater number of connections. There are other factors that are important considerations: how adjacent or close are the nodes to one another, does some nodes have authority or remarkable influence on others, are nodes positioned to be a connector between other nodes, and how capable are the nodes in absorbing, processing and diffusing the information across the links or channels. How difficult is it for the agents or nodes in the network to make connections? It is presumed that if the density of the network is increased, then we create a propensity in the overall network system to increase the potential for increased connectivity.

As discussed previously, our understanding of the network is deeper once we understand the elements well. The structure or network topology is represented by the graph and then we must understand size of network and the patterns that are manifested in the visual depiction of the network. Patterns, for our purposes, might refer to clusters of nodes that are tribal or share geographical proximity that self-organize and thus influence the structure of the network. We will introduce a new term homophily where agents connect with those like themselves. This attribute presumably allows less resources needed to process information and diffuse outcomes within the cluster. Most networks have a cluster bias: in other words, there are areas where there is increased activity or increased homogeneity in attributes or some form of metric that enshrines a group of agents under one specific set of values or activities. Understanding the distribution of cluster and the cluster bias makes it easier to influence how to propagate or even dismantle the network. This leads to an interesting question: Can a network that emerges spontaneously from the informal connectedness between agents be subjected to some high dominance coefficient – namely, could there be nodes or links that might exercise significant weight on the network?
The network has to align to its environment. The environment can place constraints on the network. In some instances, the agents have to figure out how to overcome or optimize their purpose in the context of the presence of the environmental constraints. There is literature that suggests the existence of random networks which might be an initial state, but it is widely agreed that these random networks self-organize around their purpose and their interaction with its environment. Network theory assigns a number to the degree of distribution which means that all or most nodes have an equivalent degree of connectivity and there is no skewed influence being weighed on the network by a node or a cluster. Low numbers assigned to the degree of distribution suggest a network that is very democratic versus high number that suggests centralization. To get a more practical sense, a mid-range number assigned to a network constitutes a decentralized network which has close affinities and not fully random. We have heard of the six degrees of separation and that linkage or affinity is most closely tied to a mid-number assignment to the network.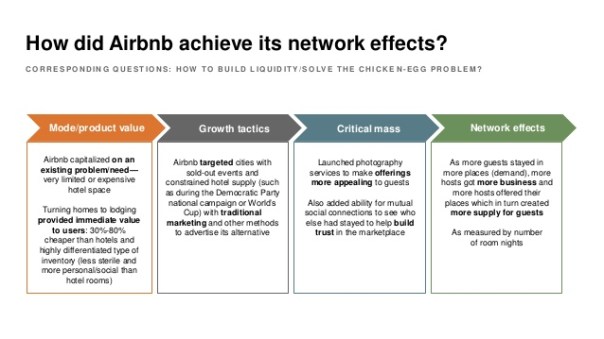
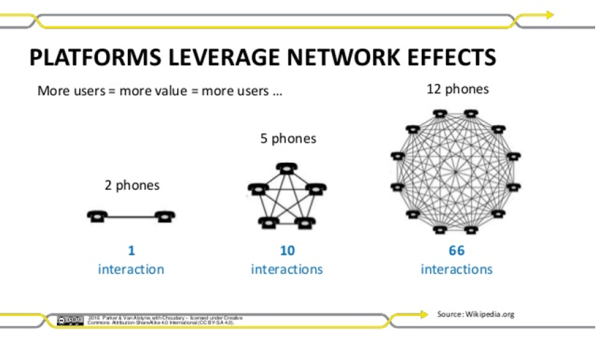
We are now getting into discussions on scale and binding this with network theory. Metcalfe’s law states that the value of a network grows as a square of the number of the nodes in the network. More people join the network, the more valuable the network. Essentially, there is a feedback loop that is created, and this feedback loop can kindle a network to grow exponentially. There are two other topics – Contagion and Resilience. Contagion refers to the ability of the agents to diffuse information. This information can grow the network or dismantle it. Resilience refers to how the network is organized to preserve its structure. As you can imagine, they have huge implications that we see. How do certain ideas proliferate over others, how does it cluster and create sub-networks which might grow to become large independent networks and how it creates natural defense mechanisms against self-immolation and destruction?
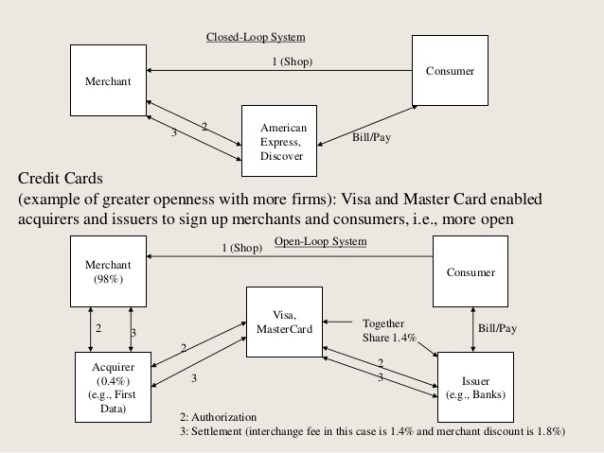
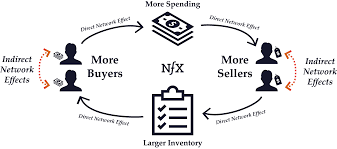
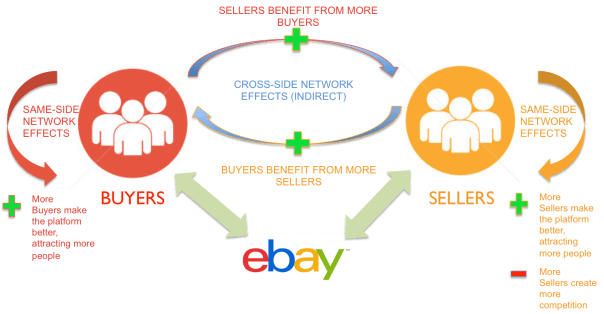
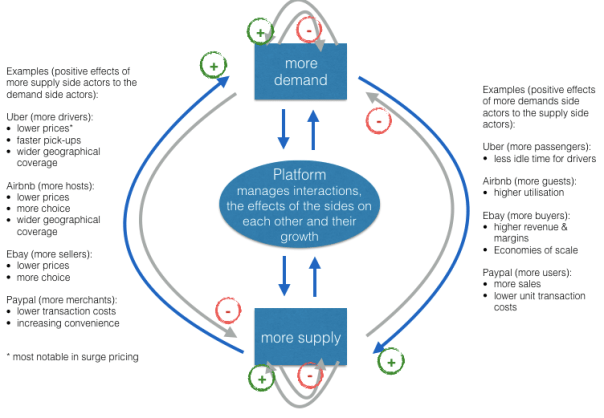
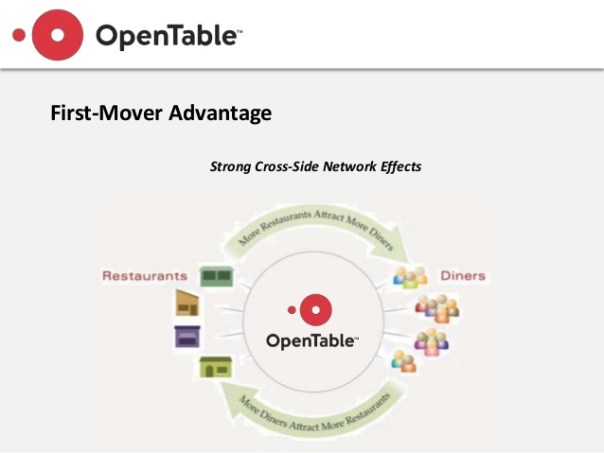
Network effect is commonly known as externalities in economics. It is an effect that is external to the transaction but influences the transaction. It is the incremental benefit gained by an existing user for each new user that joins the network. There are two types of network effects: Direct network effects and Indirect network effect. Direct network effects are same side effects. The value of a service goes up as the number of users goes up. For example, if more people have phones, it is useful for you to have a phone. The entire value proposition is one-sided. Indirect networks effects are multi-sided. It lends itself to our current thinking around platforms and why smart platforms can exponentially increase the network. The value of the service increases for one user group when a new user group joins the network. Take for example the relationship between credit card banks, merchants and consumers. There are three user groups, and each gather different value from the network of agents that have different roles. If more consumers use credit cards to buy, more merchants will sign up for the credit cards, and as more merchants sign up – more consumers will sign up with the bank to get more credit cards. This would be an example of a multi-sided platform that inherently has multi-sided network effects. The platform inherently gains significant power such that it becomes more valuable for participants in the system to join the network despite the incremental costs associated with joining the network. Platforms that are built upon effective multi-sided network effects grow quickly and are generally sustainable. Having said that, it could be just as easy that a few dominant bad actors in the network can dismantle and unravel the network completely. We often hear of the tipping point: namely, that once the platform reaches a critical mass of users, it would be difficult to dismantle it. That would certainly be true if the agents and services are, in the aggregate, distributed fairly across the network: but it is also possible that new networks creating even more multi-sided network effects could displace an entrenched network. Hence, it is critical that platform owners manage the quality of content and users and continue to look for more opportunities to introduce more user groups to entrench and yet exponentially grow the network.
Winner Take All Strategy
Being the first to cross the finish line makes you a winner in only one phase of life. It’s what you do after you cross the line that really counts.
– Ralph Boston
Does winner-take-all strategy apply outside the boundaries of a complex system? Let us put it another way. If one were to pursue a winner-take-all strategy, then does this willful strategic move not bind them to the constraints of complexity theory? Will the net gains accumulate at a pace over time far greater than the corresponding entropy that might be a by-product of such a strategy? Does natural selection exhibit a winner-take-all strategy over time and ought we then to regard that winning combination to spur our decisions around crafting such strategies? Are we fated in the long run to arrive at a world where there will be a very few winners in all niches and what would that mean? How does that surmise with our good intentions of creating equal opportunities and a fair distribution of access to resources to a wider swath of the population? In other words, is a winner take all a deterministic fact and does all our trivial actions to counter that constitute love’s labor lost?

Natural selection is a mechanism for evolution. It explains how populations or species evolve or modify over time in such a manner that it becomes better suited to their environments. Recall the discussion on managing scale in the earlier chapter where we discussed briefly about aligning internal complexity to external complexity. Natural selection is how it plays out at a biological level. Essentially natural selection posits that living organisms have inherited traits that help them to survive and procreate. These organisms will largely leave more offspring than their peers since the presumption is that these organisms will carry key traits that will survive the vagaries of external complexity and environment (predators, resource scarcity, climate change, etc.) Since these traits are passed on to the next generate, these traits will become more common until such time that the traits are dominant over generations, if the environment has not been punctuated with massive changes. These organisms with these dominant traits will have adapted to their environment. Natural selection does not necessarily suggest that what is good for one is good for the collective species.
An example that was shared by Robert Frank in his book “The Darwin Economy” was the case of large antlers of the bull elk. These antlers developed as an instrument for attracting mates rather than warding off predators. Big antlers would suggest a greater likelihood of the bull elk to marginalize the elks with smaller antlers. Over time, the bull elks with small antlers would die off since they would not be able to produce offspring and pass their traits. Thus, the bull elks would largely comprise of those elks with large antlers. However, the flip side is that large antlers compromise mobility and thus are more likely to be attacked by predators. Although the individual elk with large antler might succeed to stay around over time, it is also true that the compromised mobility associated with large antlers would overall hurt the propagation of the species as a collective group. We will return to this very important concept later. The interests of individual animals were often profoundly in conflict with the broader interests of their own species. Corresponding to the development of the natural selection mechanism is the introduction of the concept of the “survival of the fittest” which was introduced by Herbert Spencer. One often uses natural selection and survival of the fittest interchangeable and that is plain wrong. Natural selection never claims that the species that will emerge is the strongest, the fastest, the largest, etc.: it simply claims that the species will be the fittest, namely it will evolve in a manner best suited for the environment in which it resides. Put it another way: survival of the most sympathetic is perhaps more applicable. Organisms that are more sympathetic and caring and work in harmony with the exigencies of an environment that is largely outside of their control would likely succeed and thrive.

We will digress into the world of business. A common conception that is widely discussed is that businesses must position toward a winner-take-all strategy – especially, in industries that have very high entry costs. Once these businesses entrench themselves in the space, the next immediate initiative would be to literally launch a full-frontal assault involving huge investments to capture the mind and the wallet of the customer. Peter Thiel says – Competition is for losers. If you want to create and capture lasting value, look to build a monopoly.” Once that is built, it would be hard to displace!
Scaling the organization intentionally is key to long-term success. There are a number of factors that contribute toward developing scale and thus establishing a strong footing in the particular markets. We are listing some of the key factors below:
- Barriers to entry: Some organizations have natural cost prohibitive barriers to entry like utility companies or automobile plants. They require large investments. On the other hand, organizations can themselves influence and erect huge barriers to entry even though the barriers did not exist. Organizations would massively invest in infrastructure, distribution, customer acquisition and retention, brand and public relations. Organizations that are able to rapidly do this at a massive scale would be the ones that is expected to exercise their leverage over a big consumption base well into the future.
- Multi-sided platform impacts: The value of information across multiple subsystems: company, supplier, customer, government increases disproportionately as it expands. We had earlier noted that if cities expand by 100%, then there is increasing innovating and goods that generate 115% -the concept of super-linear scaling. As more nodes are introduced into the system and a better infrastructure is created to support communication and exchange between the nodes, the more entrenched the business becomes. And interestingly, the business grows at a sub-linear scale – namely, it consumes less and less resources in proportion to its growth. Hence, we see the large unicorn valuation among companies where investors and market makers place calculated bets on investments of colossal magnitudes. The magnitude of such investments is relatively a recent event, and this is largely driven by the advances in technology that connect all stakeholders.
- Investment in learning: To manage scale is to also be selective of information that a system receives and how the information is processed internally. In addition, how is this information relayed to the external system or environment. This requires massive investment in areas like machine learning, artificial intelligence, big data, enabling increased computational power, development of new learning algorithms, etc. This means that organizations have to align infrastructure and capability while also working with external environments through public relations, lobbying groups and policymakers to chaperone a comprehensive and a very complex hard-to-replicate learning organism.
- Investment in brand: Brand personifies the value attributes of an organization. One connects brand to customer experience and perception of the organization’s product. To manage scale and grow, organizations must invest in brand: to capture increased mindshare of the consumer. In complexity science terms, the internal systems are shaped to emit powerful signals to the external environment and urge a response. Brand and learning work together to allow a harmonic growth of an internal system in the context of its immediate environment.
However, one must revert to the science of complexity to understand the long-term challenges of a winner-take-all mechanism. We have already seen the example that what is good for the individual bull-elk might not be the best for the species in the long-term. We see that super-linear scaling systems also emits significant negative by-products. Thus, the question that we need to ask is whether the organizations are paradoxically cultivating their own seeds of destruction in their ambitions of pursuing scale and market entrenchment.
Model Thinking
| Model Framework |
The fundamental tenet of theory is the concept of “empiria“. Empiria refers to our observations. Based on observations, scientists and researchers posit a theory – it is part of scientific realism.
A scientific model is a causal explanation of how variables interact to produce a phenomenon, usually linearly organized. A model is a simplified map consisting of a few, primary variables that is gauged to have the most explanatory powers for the phenomenon being observed. We discussed Complex Physical Systems and Complex Adaptive Systems early on this chapter. It is relatively easier to map CPS to models than CAS, largely because models become very unwieldy as it starts to internalize more variables and if those variables have volumes of interaction between them. A simple analogy would be the use of multiple regression models: when you have a number of independent variables that interact strongly between each other, autocorrelation errors occur, and the model is not stable or does not have predictive value.

Research projects generally tend to either look at a case study or alternatively, they might describe a number of similar cases that are logically grouped together. Constructing a simple model that can be general and applied to many instances is difficult, if not impossible. Variables are subject to a researcher’s lack of understanding of the variable or the volatility of the variable. What further accentuates the problem is that the researcher misses on the interaction of how the variables play against one another and the resultant impact on the system. Thus, our understanding of our system can be done through some sort of model mechanics but, yet we share the common belief that the task of building out a model to provide all of the explanatory answers are difficult, if not impossible. Despite our understanding of our limitations of modeling, we still develop frameworks and artifact models because we sense in it a tool or set of indispensable tools to transmit the results of research to practical use cases. We boldly generalize our findings from empiria into general models that we hope will explain empiria best. And let us be mindful that it is possible – more so in the CAS systems than CPS that we might have multiple models that would fight over their explanatory powers simply because of the vagaries of uncertainty and stochastic variations.
Popper says: “Science does not rest upon rock-bottom. The bold structure of its theories rises, as it were, above a swamp. It is like a building erected on piles. The piles are driven down from above into the swamp, but not down to any natural or ‘given’ base; and when we cease our attempts to drive our piles into a deeper layer, it is not because we have reached firm ground. We simply stop when we are satisfied that they are firm enough to carry the structure, at least for the time being”. This leads to the satisficing solution: if a model can choose the least number of variables to explain the greatest amount of variations, the model is relatively better than other models that would select more variables to explain the same. In addition, there is always a cost-benefit analysis to be taken into consideration: if we add x number of variables to explain variation in the outcome but it is not meaningfully different than variables less than x, then one would want to fall back on the less-variable model because it is less costly to maintain.
Researchers must address three key elements in the model: time, variation and uncertainty. How do we craft a model which reflects the impact of time on the variables and the outcome? How to present variations in the model? Different variables might vary differently independent of one another. How do we present the deviation of the data in a parlance that allows us to make meaningful conclusions regarding the impact of the variations on the outcome? Finally, does the data that is being considered are actual or proxy data? Are the observations approximate? How do we thus draw the model to incorporate the fuzziness: would confidence intervals on the findings be good enough?
Two other equally other concepts in model design is important: Descriptive Modeling and Normative Modeling.
Descriptive models aim to explain the phenomenon. It is bounded by that goal and that goal only.
There are certain types of explanations that they fall back on: explain by looking at data from the past and attempting to draw a cause and effect relationship. If the researcher is able to draw a complete cause and effect relationship that meets the test of time and independent tests to replicate the results, then the causality turns into law for the limited use-case or the phenomenon being explained. Another explanation method is to draw upon context: explaining a phenomenon by looking at the function that the activity fulfills in its context. For example, a dog barks at a stranger to secure its territory and protect the home. The third and more interesting type of explanation is generally called intentional explanation: the variables work together to serve a specific purpose and the researcher determines that purpose and thus, reverse engineers the understanding of the phenomenon by understanding the purpose and how the variables conform to achieve that purpose.
This last element also leads us to thinking through the other method of modeling – namely, normative modeling. Normative modeling differs from descriptive modeling because the target is not to simply just gather facts to explain a phenomenon, but rather to figure out how to improve or change the phenomenon toward a desirable state. The challenge, as you might have already perceived, is that the subjective shadow looms high and long and the ultimate finding in what would be a normative model could essentially be a teleological representation or self-fulfilling prophecy of the researcher in action. While this is relatively more welcome in a descriptive world since subjectivism is diffused among a larger group that yields one solution, it is not the best in a normative world since variation of opinions that reflect biases can pose a problem.
How do we create a representative model of a phenomenon? First, we weigh if the phenomenon is to be understood as a mere explanation or to extend it to incorporate our normative spin on the phenomenon itself. It is often the case that we might have to craft different models and then weigh one against the other that best represents how the model can be explained. Some of the methods are fairly simple as in bringing diverse opinions to a table and then agreeing upon one specific model. The advantage of such an approach is that it provides a degree of objectivism in the model – at least in so far as it removes the divergent subjectivity that weaves into the various models. Other alternative is to do value analysis which is a mathematical method where the selection of the model is carried out in stages. You define the criteria of the selection and then the importance of the goal (if that be a normative model). Once all of the participants have a general agreement, then you have the makings of a model. The final method is to incorporate all all of the outliers and the data points in the phenomenon that the model seeks to explain and then offer a shared belief into those salient features in the model that would be best to apply to gain information of the phenomenon in a predictable manner.

There are various languages that are used for modeling:
Written Language refers to the natural language description of the model. If price of butter goes up, the quantity demanded of the butter will go down. Written language models can be used effectively to inform all of the other types of models that follow below. It often goes by the name of “qualitative” research, although we find that a bit limiting. Just a simple statement like – This model approximately reflects the behavior of people living in a dense environment …” could qualify as a written language model that seeks to shed light on the object being studied.
Icon Models refer to a pictorial representation and probably the earliest form of model making. It seeks to only qualify those contours or shapes or colors that are most interesting and relevant to the object being studied. The idea of icon models is to pictorially abstract the main elements to provide a working understanding of the object being studied.
Topological Models refer to how the variables are placed with respect to one another and thus helps in creating a classification or taxonomy of the model. Once can have logical trees, class trees, Venn diagrams, and other imaginative pictorial representation of fields to further shed light on the object being studied. In fact, pictorial representations must abide by constant scale, direction and placements. In other words, if the variables are placed on a different scale on different maps, it would be hard to draw logical conclusions by sight alone. In addition, if the placements are at different axis in different maps or have different vectors, it is hard to make comparisons and arrive at a shared consensus and a logical end result.
Arithmetic Models are what we generally fall back on most. The data is measured with an arithmetic scale. It is done via tables, equations or flow diagrams. The nice thing about arithmetic models is that you can show multiple dimensions which is not possible with other modeling languages. Hence, the robustness and the general applicability of such models are huge and thus is widely used as a key language to modeling.
Analogous Models refer to crafting explanations using the power of analogy. For example, when we talk about waves – we could be talking of light waves, radio waves, historical waves, etc. These metaphoric representations can be used to explain phenomenon, but at best, the explanatory power is nebulous, and it would be difficult to explain the variations and uncertainties between two analogous models. However, it still is used to transmit information quickly through verbal expressions like – “Similarly”, “Equivalently”, “Looks like ..” etc. In fact, extrapolation is a widely used method in modeling and we would ascertain this as part of the analogous model to a great extent. That is because we time-box the variables in the analogous model to one instance and the extrapolated model to another instance and we tie them up with mathematical equations.
The Law of Unintended Consequences
The Law of Unintended Consequence is that the actions of a central body that might claim omniscient, omnipotent and omnivalent intelligence might, in fact, lead to consequences that are not anticipated or unintended.
The concept of the Invisible Hand as introduced by Adam Smith argued that it is the self-interest of all the market agents that ultimately create a system that maximizes the good for the greatest amount of people.
Robert Merton, a sociologist, studied the law of unintended consequence. In an influential article titled “The Unanticipated Consequences of Purposive Social Action,” Merton identified five sources of unanticipated consequences.
Ignorance makes it difficult and impossible to anticipate the behavior of every element or the system which leads to incomplete analysis.
Errors that might occur when someone uses historical data and applies the context of history into the future. Linear thinking is a great example of an error that we are wrestling with right now – we understand that there are systems, looking back, that emerge exponentially but it is hard to decipher the outcome unless one were to take a leap of faith.
Biases work its way into the study as well. We study a system under the weight of our biases, intentional or unintentional. It is hard to strip that away even if there are different bodies of thought that regard a particular system and how a certain action upon the system would impact it.
Weaved with the element of bias is the element of basic values that may require or prohibit certain actions even if the long-term impact is unfavorable. A good example would be the toll gates established by the FDA to allow drugs to be commercialized. In its aim to provide a safe drug, the policy might be such that the latency of the release of drugs for experiments and commercial purposes are so slow that many patients who might otherwise benefit from the release of the drug lose out.
Finally, he discusses the self-fulfilling prophecy which suggests that tinkering with the elements of a system to avert a catastrophic negative event might in actuality result in the event.
It is important however to acknowledge that unintended consequences do not necessarily lead to a negative outcome. In fact, there are could be unanticipated benefits. A good example is Viagra which started off as a pill to lower blood pressure, but one discovered its potency to solve erectile dysfunctions. The discovery that ships that were sunk became the habitat and formation of very rich coral reefs in shallow waters that led scientists to make new discoveries in the emergence of flora and fauna of these habitats.

If there are initiatives exercised that are considered “positive initiative” to influence the system in a manner that contribute to the greatest good, it is often the case that these positive initiatives might prove to be catastrophic in the long term. Merton calls the cause of this unanticipated consequence as something called the product of the “relevance paradox” where decision makers thin they know their areas of ignorance regarding an issue, obtain the necessary information to fill that ignorance gap but intentionally or unintentionally neglect or disregard other areas as its relevance to the final outcome is not clear or not lined up to values. He goes on to argue, in a nutshell, that unintended consequences relate to our hubris – we are hardwired to put our short-term interest over long term interest and thus we tinker with the system to surface an effect which later blow back in unexpected forms. Albert Camus has said that “The evil in the world almost always comes of ignorance, and good intentions may do as much harm as malevolence if they lack understanding.”
An interesting emergent property that is related to the law of unintended consequence is the concept of Moral Hazard. It is a concept that individuals have incentives to alter their behavior when their risk or bad decision making is borne of diffused among others. For example:
If you have an insurance policy, you will take more risks than otherwise. The cost of those risks will impact the total economics of the insurance and might lead to costs being distributed from the high-risk takers to the low risk takers.

How do the conditions of the moral hazard arise in the first place? There are two important conditions that must hold. First, one party has more information than another party. The information asymmetry thus creates gaps in information and that creates a condition of moral hazard. For example, during 2006 when sub-prime mortgagors extended loans to individuals who had dubitable income and means to pay. The Banks who were buying these mortgages were not aware of it. Thus, they ended up holding a lot of toxic loans due to information asymmetry. Second, is the existence of an understanding that might affect the behavior of two agents. If a child knows that they are going to get bailed out by the parents, he/she might take some risks that he/she would otherwise might not have taken.
To counter the possibility of unintended consequences, it is important to raise our thinking to second-order thinking. Most of our thinking is simplistic and is based on opinions and not too well grounded in facts. There are a lot of biases that enter first order thinking and in fact, all of the elements that Merton touches on enters it – namely, ignorance, biases, errors, personal value systems and teleological thinking. Hence, it is important to get into second-order thinking – namely, the reasoning process is surfaced by looking at interactions of elements, temporal impacts and other system dynamics. We had mentioned earlier that it is still difficult to fully wrestle all the elements of emergent systems through the best of second-order thinking simply because the dynamics of a complex adaptive system or complex physical system would deny us that crown of competence. However, this fact suggests that we step away from simple, easy and defendable heuristics to measure and gauge complex systems.
Aaron Swartz took down a piece of the Berlin Wall! We have to take it all down!
“The world’s entire scientific … heritage … is increasingly being digitized and locked up by a handful of private corporations… The Open Access Movement has fought valiantly to ensure that scientists do not sign their copyrights away but instead ensure their work is published on the Internet, under terms that allow anyone to access it.” – Aaron Swartz
Information, in the context of scholarly articles by research at universities and think-tanks, is not a zero sum game. In other words, one person cannot have more without having someone have less. When you start creating “Berlin” walls in the information arena within the halls of learning, then learning itself is compromised. In fact, contributing or granting the intellectual estate into the creative commons serves a higher purpose in society – an access to information and hence, a feedback mechanism that ultimately enhances the value to the end-product itself. How? Since now the product has been distributed across a broader and diverse audience, and it is open to further critical analyses.

The universities have built a racket. They have deployed a Chinese wall between learning in a cloistered environment and the world who are not immediate participants. The Guardian wrote an interesting article on this matter and a very apt quote puts it all together.
“Academics not only provide the raw material, but also do the graft of the editing. What’s more, they typically do so without extra pay or even recognition – thanks to blind peer review. The publishers then bill the universities, to the tune of 10% of their block grants, for the privilege of accessing the fruits of their researchers’ toil. The individual academic is denied any hope of reaching an audience beyond university walls, and can even be barred from looking over their own published paper if their university does not stump up for the particular subscription in question.

This extraordinary racket is, at root, about the bewitching power of high-brow brands. Journals that published great research in the past are assumed to publish it still, and – to an extent – this expectation fulfils itself. To climb the career ladder academics must get into big-name publications, where their work will get cited more and be deemed to have more value in the philistine research evaluations which determine the flow of public funds. Thus they keep submitting to these pricey but mightily glorified magazines, and the system rolls on.”
http://www.guardian.co.uk/commentisfree/2012/apr/11/academic-journals-access-wellcome-trust

JSTOR is a not-for-profit organization that has invested heavily in providing an online system for archiving, accessing, and searching digitized copies of over 1,000 academic journals. More recently, I noticed some effort on their part to allow public access to only 3 articles over a period of 21 days. This stinks! This policy reflects an intellectual snobbery beyond Himalayan proportions. The only folks that have access to these academic journals and studies are professors, and researchers that are affiliated with a university and university libraries. Aaron Swartz noted the injustice of hoarding such knowledge and tried to distribute a significant proportion of JSTOR’s archive through one or more file-sharing sites. And what happened thereafter was perhaps one of the biggest misapplication of justice. The same justice that disallows asymmetry of information in Wall Street is being deployed to preserve the asymmetry of information at the halls of learning.

MSNBC contributor Chris Hayes criticized the prosecutors, saying “at the time of his death Aaron was being prosecuted by the federal government and threatened with up to 35 years in prison and $1 million in fines for the crime of—and I’m not exaggerating here—downloading too many free articles from the online database of scholarly work JSTOR.”
The Associated Press reported that Swartz’s case “highlights society’s uncertain, evolving view of how to treat people who break into computer systems and share data not to enrich themselves, but to make it available to others.”
Chris Soghioian, a technologist and policy analyst with the ACLU, said, “Existing laws don’t recognize the distinction between two types of computer crimes: malicious crimes committed for profit, such as the large-scale theft of bank data or corporate secrets; and cases where hackers break into systems to prove their skillfulness or spread information that they think should be available to the public.”
Kelly Caine, a professor at Clemson University who studies people’s attitudes toward technology and privacy, said Swartz “was doing this not to hurt anybody, not for personal gain, but because he believed that information should be free and open, and he felt it would help a lot of people.”
And then there were some modest reservations, and Swartz actions were attributed to reckless judgment. I contend that this does injustice to someone of Swartz’s commitment and intellect … the recklessness was his inability to grasp the notion that an imbecile in the system would pursue 35 years of imprisonment and $1M fine … it was not that he was not aware of what he was doing but he believed, as does many, that scholarly academic research should be available as a free for all.
We have a Berlin wall that needs to be taken down. Swartz started that but he was unable to keep at it. It is important to not rest in this endeavor and that everyone ought to actively petition their local congressman to push bills that will allow open access to these academic articles.
John Maynard Keynes had warned of the folly of “shutting off the sun and the stars because they do not pay a dividend”, because what is at stake here is the reach of the light of learning. Aaron was at the vanguard leading that movement, and we should persevere to become those points of light that will enable JSTOR to disseminate the information that they guard so unreservedly.
Darkness at Noon in Facebook!
Facebook began with a simple thesis: Connect Friends. That was the sine qua non of its existence. From a simple thesis to an effective UI design, Facebook has grown over the years to become the third largest community in the world. But as of the last few years they have had to resort to generating revenue to meet shareholder expectations. Today it is noon at Facebook but there is the long shadow of darkness that I posit have fallen upon perhaps one of the most influential companies in history.

The fact is that leaping from connecting friends to managing the conversations allows Facebook to create this petri dish to understand social interactions at large scale eased by their fine technology platform. To that end, they are moving into alternative distribution channels to create broader reach into global audience and to gather deeper insights into the interaction templates of the participants. The possibilities are immense: in that, this platform can be a collaborative beachhead into discoveries, exploration, learning, education, social and environmental awareness and ultimately contribute to elevated human conscience. But it has faltered, perhaps the shareholders and the analysts are much to blame, on account of the fangled existence of market demands and it has become one global billboard for advertisers to promote their brands. Darkness at noon is the most appropriate metaphor to reflect Facebook as it is now.
Let us take a small turn to briefly look at some of other very influential companies that have not been as much derailed as has Facebook. The companies are Twitter, Google and LinkedIn. Each of them are the leaders in their category, and all of them have moved toward monetization schemes from their specific user base. Each of them has weighed in significantly in their respective categories to create movements that have or will affect the course of the future. We all know how Twitter has contributed to super-fast news feeds globally that have spontaneously generated mass coalescence around issues that make a difference; Google has been an effective tool to allow an average person to access information; and LinkedIn has created professional and collaborative environment in the professional space. Thus, all three of these companies, despite supplementing fully their appetite for revenue through advertising, have not compromised their quintessence for being. Now all of these companies can definitely move their artillery to encompass the trajectory of FB but that would be a steep hill to climb. Furthermore, these companies have an aura associated within their categories: attempts to move out of their category have been feeble at best, and in some instances, not successful. Facebook has a phenomenal chance of putting together what they have to create a communion of knowledge and wisdom. And no company exists in the market better suited to do that at this point.

One could counter that Facebook sticks to its original vision and that what we have today is indeed what Facebook had planned for all along since the beginning. I don’t disagree. My point of contention in this matter is that though is that Facebook has created this informal and awesome platform for conversations and communities among friends, it has glossed over the immense positive fallout that could occur as a result of these interactions. And that is the development and enhancement of knowledge, collaboration, cultural play, encourage a diversity of thought, philanthropy, crowd sourcing scientific and artistic breakthroughs, etc. In other words, the objective has been met for the most part. Thank you Mark! Now Facebook needs to usher in a renaissance in the courtyard. Facebook needs to find a way out of the advertising morass that has shed darkness over all the product extensions and launches that have taken place over the last 2 years: Facebook can force a point of inflection to quadruple its impact on the course of history and knowledge. And the revenue will follow!

Medici Effect – Encourage Innovation in the Organization
“Creativity is just connecting things. When you ask creative people how they did something, they feel a little guilty because they didn’t really do it, they just saw something. It seemed obvious to them after a while. That’s because they were able to connect experiences they’ve had and synthesize new things. And the reason they were able to do that was that they’ve had more experiences or they have thought more about their experiences than other people.”
– Steve Jobs
What is the Medici Effect?
Frans Johanssen has written a lovely book on the Medici Effect. The term “Medici” relates to the Medici family in Florence that made immense contributions in art, architecture and literature. They were pivotal in catalyzing the Renaissance, and some of the great artists and scientists that we revere today – Donatello, Michelangelo, Leonardo da Vinci, and Galileo were commissioned for their works by the family.

Renaissance was the resurgence of the old Athenian democracy. It merged distinctive areas of humanism, philosophy, sciences, arts and literature into a unified body of knowledge that would advance the cause of human civilization. What the Medici effect speaks to is the outcome that is the result of creating a system that would incorporate what on first glance, may seem distinctive and discrete disciplines, into holistic outcomes and a shared simmering of wisdom that permeated the emergence of new disciplines, thoughts and implementations.
Supporting the organization to harness the power of the Medici Effect
We are past the industrial era, the Progressive era and the Information era. There are no formative lines that truly distinguish one era from another, but our knowledge has progressed along gray lines that have pushed the limits of human knowledge. We are now wallowing in a crucible wherein distinct disciplines have crisscrossed and merged together. The key thesis in the Medici effect is that the intersections of these distinctive disciplines enable the birth of new breakthrough ideas and leapfrog innovation.

So how do we introduce the Medici Effect in organizations?
Some of the key ways to implement the model is really to provide the support infrastructure for
1. Connections: Our brains are naturally wired toward associations. We try to associate a concept with contextual elements around that concept to give the concept more meaning. We learn by connecting concepts and associating them, for the most part, with elements that we are conversant in. However, one can create associations within a narrow parameter, constrained within certain semantic models that we have created. Organizations can hence channelize connections by implementing narrow parameters. On the other hand, connections can be far more free-form. That means that the connector thinks beyond the immediate boundaries of their domain or within certain domains that are “pre-ordained”. In those cases, we create what is commonly known as divergent thinking. In that approach, we cull elements from seemingly different areas but we thread them around some core to generate new approaches, new metaphors, and new models. Ensuring that employees are able to safely reach out to other nodes of possibilities is the primary implementation step to generate the Medici effect.
2. Collaborations: Connecting different streams of thought in different disciplines is a primary and formative step. To advance this further, organization need to be able to provide additional systems wherein people can collaborate among themselves. In fact, the collaboration impact accentuates the final outcome sooner. So enabling connections and collaboration work in sync to create what I would call – the network impact on a marketplace of ideas.
3. Learning Organization: Organizations need to continuously add fuel to the ecosystem. In other words, they need to bring in speakers, encourage and invest in training programs, allow exploration possibilities by developing an internal budget for that purpose and provide some time and degree of freedom for people to mull over ideas. This enables collaboration to be enriched within the context of diverse learning.
4. Encourage Cultural Diversity: Finally, organizations have to invest in cultural diversity. People from different cultures have varied viewpoints and information and view issues from different perspectives and cultures. Given the fact that we are more globalized now, the innate understanding and immersion in cultural experience enhances the Medici effect. It also creates innovation and ground-breaking thoughts within a broader scope of compassion, humanism, social and shared responsibilities.

Implementing systems to encourage the Medici effect will enable organizations to break out from legacy behavior and trammel into unguarded territories. The charter toward unknown but exciting possibilities open the gateway for amazing and awesome ideas that engage the employees and enable them to beat a path to the intersection of new ideas.
The Big Data Movement: Importance and Relevance today?
We are entering into a new age wherein we are interested in picking up a finer understanding of relationships between businesses and customers, organizations and employees, products and how they are being used, how different aspects of the business and the organizations connect to produce meaningful and actionable relevant information, etc. We are seeing a lot of data, and the old tools to manage, process and gather insights from the data like spreadsheets, SQL databases, etc., are not scalable to current needs. Thus, Big Data is becoming a framework to approach how to process, store and cope with the reams of data that is being collected.

According to IDC, it is imperative that organizations and IT leaders focus on the ever-increasing volume, variety and velocity of information that forms big data.
- Volume. Many factors contribute to the increase in data volume – transaction-based data stored through the years, text data constantly streaming in from social media, increasing amounts of sensor data being collected, etc. In the past, excessive data volume created a storage issue. But with today’s decreasing storage costs, other issues emerge, including how to determine relevance amidst the large volumes of data and how to create value from data that is relevant.
- Variety. Data today comes in all types of formats – from traditional databases to hierarchical data stores created by end users and OLAP systems, to text documents, email, meter-collected data, video, audio, stock ticker data and financial transactions. By some estimates, 80 percent of an organization’s data is not numeric! But it still must be included in analyses and decision making.
- Velocity. According to Gartner, velocity “means both how fast data is being produced and how fast the data must be processed to meet demand.” RFID tags and smart metering are driving an increasing need to deal with torrents of data in near-real time. Reacting quickly enough to deal with velocity is a challenge to most organizations.
SAS has added two additional dimensions:
- Variability. In addition to the increasing velocities and varieties of data, data flows can be highly inconsistent with periodic peaks. Is something big trending in the social media? Daily, seasonal and event-triggered peak data loads can be challenging to manage – especially with social media involved.
- Complexity. When you deal with huge volumes of data, it comes from multiple sources. It is quite an undertaking to link, match, cleanse and transform data across systems. However, it is necessary to connect and correlate relationships, hierarchies and multiple data linkages or your data can quickly spiral out of control. Data governance can help you determine how disparate data relates to common definitions and how to systematically integrate structured and unstructured data assets to produce high-quality information that is useful, appropriate and up-to-date.

So to reiterate, Big Data is a framework stemming from the realization that the data has gathered significant pace and that it’s growth has exceeded the capacity for an organization to handle, store and analyze the data in a manner that offers meaningful insights into the relationships between data points. I am calling this a framework, unlike other materials that call Big Data a consequent of the inability of organizations to handle mass amounts of data. I refer to Big Data as a framework because it sets the parameters around an organizations’ decision as to when and which tools must be deployed to address the data scalability issues.

Thus to put the appropriate parameters around when an organization must consider Big Data as part of their analytics roadmap in order to understand the patterns of data better, they have to answer the following ten questions:
- What are the different types of data that should be gathered?
- What are the mechanisms that have to be deployed to gather the relevant data?
- How should the data be processed, transformed and stored?
- How do we ensure that there is no single point of failure in data storage and data loss that may compromise data integrity?
- What are the models that have to be used to analyze the data?
- How are the findings of the data to be distributed to relevant parties?
- How do we assure the security of the data that will be distributed?
- What mechanisms do we create to implement feedback against the data to preserve data integrity?
- How do we morph the big data model into new forms that accounts for new patterns to reflect what is meaningful and actionable?
- How do we create a learning path for the big data model framework?
Some of the existing literature have commingled Big Data framework with analytics. In fact, the literature has gone on to make a rather assertive statement i.e. that Big Data and predictive analytics be looked upon in the same vein. Nothing could be further from the truth!
There are several tools available in the market to do predictive analytics against a set of data that may not qualify for the Big Data framework. While I was the CFO at Atari, we deployed business intelligence tools using Microstrategy, and Microstrategy had predictive modules. In my recent past, we had explored SAS and Minitab tools to do predictive analytics. In fact, even Excel can do multivariate, ANOVA and regressions analysis and best curve fit analysis. These analytical techniques have been part of the analytics arsenal for a long time. Different data sizes may need different tools to instantiate relevant predictive analysis. This is a very important point because companies that do not have Big Data ought to seriously reconsider their strategy of what tools and frameworks to use to gather insights. I have known companies that have gone the Big Data route, although all data points ( excuse my pun), even after incorporating capacity and forecasts, suggest that alternative tools are more cost-effective than implementing Big Data solutions. Big Data is not a one-size fit-all model. It is an expensive implementation. However, for the right data size which in this case would be very large data size, Big Data implementation would be extremely beneficial and cost effective in terms of the total cost of ownership.
Areas where Big Data Framework can be applied!
Some areas lend themselves to the application of the Big Data Framework. I have identified broadly four key areas:
- Marketing and Sales: Consumer behavior, marketing campaigns, sales pipelines, conversions, marketing funnels and drop-offs, distribution channels are all areas where Big Data can be applied to gather deeper insights.
- Human Resources: Employee engagement, employee hiring, employee retention, organization knowledge base, impact of cross-functional training, reviews, compensation plans are elements that Big Data can surface. After all, generally over 60% of company resources are invested in HR.
- Production and Operational Environments: Data growth, different types of data appended as the business learns about the consumer, concurrent usage patterns, traffic, web analytics are prime examples.
- Financial Planning and Business Operational Analytics: Predictive analytics around bottoms-up sales, marketing campaigns ROI, customer acquisitions costs, earned media and paid media, margins by SKU’s and distribution channels, operational expenses, portfolio evaluation, risk analysis, etc., are some of the examples in this category.
Hadoop: A Small Note!
Hadoop is becoming a more widely accepted tool in addressing Big Data Needs. It was invented by Google so they could index the structural and text information that they were collecting and present meaningful and actionable results to the users quickly. It was further developed by Yahoo that tweaked Hadoop for enterprise applications.
Hadoop runs on a large number of machines that don’t share memory or disks. The Hadoop software runs on each of these machines. Thus, if you have for example – over 10 gigabytes of data – you take that data and spread that across different machines. Hadoop tracks where all these data resides! The servers or machines are called nodes, and the common logical categories around which the data is disseminated are called clusters. Thus each server operates on its own little piece of the data, and then once the data is processed, the results are delivered to the main client as a unified whole. The method of reducing the disparate sources of information residing in various nodes and clusters into one unified whole is the process of MapReduce, an important mechanism of Hadoop. You will also hear something called Hive which is nothing but a data warehouse. This could be a structured or unstructured warehouse upon which the Hadoop works upon, processes data, enables redundancy across the clusters and offers a unified solution through the MapReduce function.

Personally, I have always been interested in Business Intelligence. I have always considered BI as a stepping stone, in the new age, to be a handy tool to truly understand a business and develop financial and operational models that are fairly close to the trending insights that the data generates. So my ear is always to the ground as I follow the developments in this area … and though I have not implemented a Big Data solution, I have always been and will continue to be interested in seeing its applications in certain contexts and against the various use cases in organizations.
Organization Architecture – Evolving strain!
") Innovation is happening at a rapid pace. An organization is being pummeled with new pieces of information, internally and externally, that is forcing pivots to accommodate changing customer needs and incorporating emerging technologies and solutions. Thus, the traditional organization structures have been fairly internally focused. Ronald Coase in his famous paper The Nature of the Firm (1937) had argued that organizations emerge to arrest transactional costs of managing multiple contracts with multiple service providers; the organization represents an efficient organizational unit given all other possible alternatives to coexist in an industrial ecosystem. Read the rest of this entry
Innovation is happening at a rapid pace. An organization is being pummeled with new pieces of information, internally and externally, that is forcing pivots to accommodate changing customer needs and incorporating emerging technologies and solutions. Thus, the traditional organization structures have been fairly internally focused. Ronald Coase in his famous paper The Nature of the Firm (1937) had argued that organizations emerge to arrest transactional costs of managing multiple contracts with multiple service providers; the organization represents an efficient organizational unit given all other possible alternatives to coexist in an industrial ecosystem. Read the rest of this entry
