Blog Archives
Distribution Economics
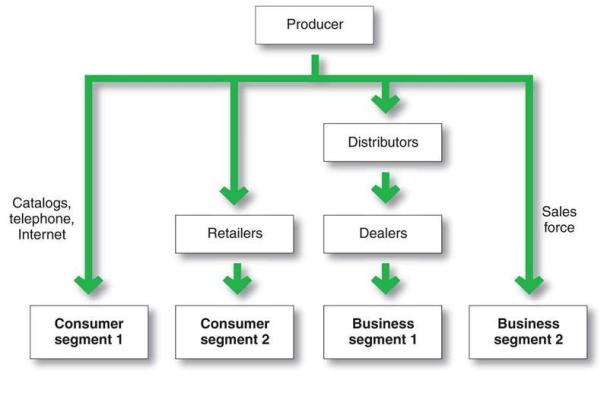
Distribution is a method to get products and services to the maximum number of customers efficiently.

Complexity science is the study of complex systems and the problems that are multi-dimensional, dynamic and unpredictable. It constitutes a set of interconnected relationships that are not always abiding to the laws of cause and effect, but rather the modality of non-linearity. Thomas Kuhn in his pivotal essay: The Structure of Scientific Revolutions posits that anomalies that arise in scientific method rise to the level where it can no longer be put on hold or simmer on a back-burner: rather, those anomalies become the front line for new methods and inquiries such that a new paradigm necessarily must emerge to supplant the old conversations. It is this that lays the foundation of scientific revolution – an emergence that occurs in an ocean of seeming paradoxes and competing theories. Contrary to a simple scientific method that seeks to surface regularities in natural phenomenon, complexity science studies the effects that rules have on agents. Rules do not drive systems toward a predictable outcome: rather it sets into motion a high density of interactions among agents such that the system coalesces around a purpose: that being necessarily that of survival in context of its immediate environment. In addition, the learnings that follow to arrive at the outcome is then replicated over periods to ensure that the systems mutate to changes in the external environment. In theory, the generative rules leads to emergent behavior that displays patterns of parallelism to earlier known structures.
For any system to survive and flourish, distribution of information, noise and signals in and outside of a CPS or CAS is critical. We have touched at length that the system comprises actors and agents that work cohesively together to fulfill a special purpose. Specialization and scale matter! How is a system enabled to fulfill their purpose and arrive at a scale that ensures long-term sustenance? Hence the discussion on distribution and scale which is a salient factor in emergence of complex systems that provide the inherent moat of “defensibility” against internal and external agents working against it.
Distribution, in this context, refers to the quality and speed of information processing in the system. It is either created by a set of rules that govern the tie-ups between the constituent elements in the system or it emerges based on a spontaneous evolution of communication protocols that are established in response to internal and external stimuli. It takes into account the available resources in the system or it sets up the demands on resource requirements. Distribution capabilities have to be effective and depending upon the dynamics of external systems, these capabilities might have to be modified effectively. Some distribution systems have to be optimized or organized around efficiency: namely, the ability of the system to distribute information efficiently. On the other hand, some environments might call for less efficiency as the key parameter, but rather focus on establishing a scale – an escape velocity in size and interaction such that the system can dominate the influence of external environments. The choice between efficiency and size is framed by the long-term purpose of the system while also accounting for the exigencies of ebbs and flows of external agents that might threaten the system’s existence.

Since all systems are subject to the laws of entropy and the impact of unintended consequences, strategies have to be orchestrated accordingly. While it is always naïve to assume exactitude in the ultimate impact of rules and behavior, one would surmise that such systems have to be built around the fault lines of multiple roles for agents or group of agents to ensure that the system is being nudged, more than less, toward the desired outcome. Hence, distribution strategy is the aggregate impact of several types of channels of information that are actively working toward a common goal. The idea is to establish multiple channels that invoke different strategies while not cannibalizing or sabotaging an existing set of channels. These mutual exclusive channels have inherent properties that are distinguished by the capacity and length of the channels, the corresponding resources that the channels use and the sheer ability to chaperone the system toward the overall purpose.
The complexity of the purpose and the external environment determines the strategies deployed and whether scale or efficiency are the key barometers for success. If a complex system must survive and hopefully replicate from strength to greater strength over time, size becomes more paramount than efficiency. Size makes up for the increased entropy which is the default tax on the system, and it also increases the possibility of the system to reach the escape velocity. To that end, managing for scale by compromising efficiency is a perfectly acceptable means since one is looking at the system with a long-term lens with built-in regeneration capabilities. However, not all systems might fall in this category because some environments are so dynamic that planning toward a long-term stability is not practical, and thus one has to quickly optimize for increased efficiency. It is thus obvious that scale versus efficiency involves risky bets around how the external environment will evolve. We have looked at how the systems interact with external environments: yet, it is just as important to understand how the actors work internally in a system that is pressed toward scale than efficiency, or vice versa. If the objective is to work toward efficiency, then capabilities can be ephemeral: one builds out agents and actors with capabilities that are mission-specific. On the contrary, scale driven systems demand capabilities that involve increased multi-tasking abilities, the ability to develop and learn from feedback loops, and to prime the constraints with additional resources. Scaling demand acceleration and speed: if a complex system can be devised to distribute information and learning at an accelerating pace, there is a greater likelihood that this system would dominate the environment.
Scaling systems can be approached by adding more agents with varying capabilities. However, increased number of participants exponentially increase the permutations and combinations of channels and that can make the system sluggish. Thus, in establishing the purpose and the subsequent design of the system, it is far more important to establish the rules of engagement. Further, the rules might have some centralized authority that will directionally provide the goal while other rules might be framed in a manner to encourage a pure decentralization of authority such that participants act quickly in groups and clusters to enable execution toward a common purpose.
In business we are surrounded by uncertainty and opportunities. It is how we calibrate around this that ultimately reflects success. The ideal framework at work would be as follows:
- What are the opportunities and what are the corresponding uncertainties associated with the opportunities? An honest evaluation is in order since this is what sets the tone for the strategic framework and direction of the organization.
- Should we be opportunistic and establish rules that allow the system to gear toward quick wins: this would be more inclined toward efficiencies. Or should we pursue dominance by evaluating our internal capability and the probability of winning and displacing other systems that are repositioning in advance or in response to our efforts? At which point, speed and scale become the dominant metric and the resources and capabilities and the set of governing rules have to be aligned accordingly.
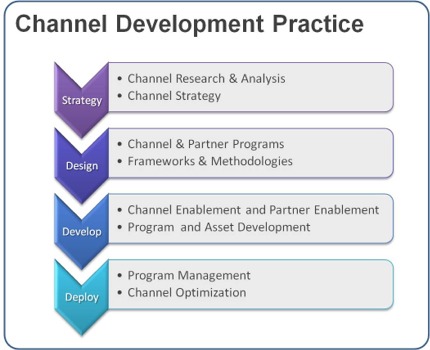
- How do we craft multiple channels within and outside of the system? In business lingo, that could translate into sales channels. These channels are selling products and services and can be adding additional value along the way to the existing set of outcomes that the system is engineered for. The more the channels that are mutually exclusive and clearly differentiated by their value propositions, the stronger the system and the greater the ability to scale quickly. These antennas, if you will, also serve to be receptors for new information which will feed data into the organization which can subsequently process and reposition, if the situation so warrants. Having as many differentiated antennas comprise what constitutes the distribution strategy of the organization.
- The final cut is to enable a multi-dimensional loop between external and internal system such that the system expands at an accelerating pace without much intervention or proportionate changes in rules. In other words, system expands autonomously – this is commonly known as the platform effect. Scale does not lead to platform effect although the platform effect most definitely could result in scale. However, scale can be an important contributor to platform effect, and if the latter gets root, then the overall system achieves efficiency and scale in the long run.
Winner Take All Strategy
Being the first to cross the finish line makes you a winner in only one phase of life. It’s what you do after you cross the line that really counts.
– Ralph Boston
Does winner-take-all strategy apply outside the boundaries of a complex system? Let us put it another way. If one were to pursue a winner-take-all strategy, then does this willful strategic move not bind them to the constraints of complexity theory? Will the net gains accumulate at a pace over time far greater than the corresponding entropy that might be a by-product of such a strategy? Does natural selection exhibit a winner-take-all strategy over time and ought we then to regard that winning combination to spur our decisions around crafting such strategies? Are we fated in the long run to arrive at a world where there will be a very few winners in all niches and what would that mean? How does that surmise with our good intentions of creating equal opportunities and a fair distribution of access to resources to a wider swath of the population? In other words, is a winner take all a deterministic fact and does all our trivial actions to counter that constitute love’s labor lost?

Natural selection is a mechanism for evolution. It explains how populations or species evolve or modify over time in such a manner that it becomes better suited to their environments. Recall the discussion on managing scale in the earlier chapter where we discussed briefly about aligning internal complexity to external complexity. Natural selection is how it plays out at a biological level. Essentially natural selection posits that living organisms have inherited traits that help them to survive and procreate. These organisms will largely leave more offspring than their peers since the presumption is that these organisms will carry key traits that will survive the vagaries of external complexity and environment (predators, resource scarcity, climate change, etc.) Since these traits are passed on to the next generate, these traits will become more common until such time that the traits are dominant over generations, if the environment has not been punctuated with massive changes. These organisms with these dominant traits will have adapted to their environment. Natural selection does not necessarily suggest that what is good for one is good for the collective species.
An example that was shared by Robert Frank in his book “The Darwin Economy” was the case of large antlers of the bull elk. These antlers developed as an instrument for attracting mates rather than warding off predators. Big antlers would suggest a greater likelihood of the bull elk to marginalize the elks with smaller antlers. Over time, the bull elks with small antlers would die off since they would not be able to produce offspring and pass their traits. Thus, the bull elks would largely comprise of those elks with large antlers. However, the flip side is that large antlers compromise mobility and thus are more likely to be attacked by predators. Although the individual elk with large antler might succeed to stay around over time, it is also true that the compromised mobility associated with large antlers would overall hurt the propagation of the species as a collective group. We will return to this very important concept later. The interests of individual animals were often profoundly in conflict with the broader interests of their own species. Corresponding to the development of the natural selection mechanism is the introduction of the concept of the “survival of the fittest” which was introduced by Herbert Spencer. One often uses natural selection and survival of the fittest interchangeable and that is plain wrong. Natural selection never claims that the species that will emerge is the strongest, the fastest, the largest, etc.: it simply claims that the species will be the fittest, namely it will evolve in a manner best suited for the environment in which it resides. Put it another way: survival of the most sympathetic is perhaps more applicable. Organisms that are more sympathetic and caring and work in harmony with the exigencies of an environment that is largely outside of their control would likely succeed and thrive.

We will digress into the world of business. A common conception that is widely discussed is that businesses must position toward a winner-take-all strategy – especially, in industries that have very high entry costs. Once these businesses entrench themselves in the space, the next immediate initiative would be to literally launch a full-frontal assault involving huge investments to capture the mind and the wallet of the customer. Peter Thiel says – Competition is for losers. If you want to create and capture lasting value, look to build a monopoly.” Once that is built, it would be hard to displace!
Scaling the organization intentionally is key to long-term success. There are a number of factors that contribute toward developing scale and thus establishing a strong footing in the particular markets. We are listing some of the key factors below:
- Barriers to entry: Some organizations have natural cost prohibitive barriers to entry like utility companies or automobile plants. They require large investments. On the other hand, organizations can themselves influence and erect huge barriers to entry even though the barriers did not exist. Organizations would massively invest in infrastructure, distribution, customer acquisition and retention, brand and public relations. Organizations that are able to rapidly do this at a massive scale would be the ones that is expected to exercise their leverage over a big consumption base well into the future.
- Multi-sided platform impacts: The value of information across multiple subsystems: company, supplier, customer, government increases disproportionately as it expands. We had earlier noted that if cities expand by 100%, then there is increasing innovating and goods that generate 115% -the concept of super-linear scaling. As more nodes are introduced into the system and a better infrastructure is created to support communication and exchange between the nodes, the more entrenched the business becomes. And interestingly, the business grows at a sub-linear scale – namely, it consumes less and less resources in proportion to its growth. Hence, we see the large unicorn valuation among companies where investors and market makers place calculated bets on investments of colossal magnitudes. The magnitude of such investments is relatively a recent event, and this is largely driven by the advances in technology that connect all stakeholders.
- Investment in learning: To manage scale is to also be selective of information that a system receives and how the information is processed internally. In addition, how is this information relayed to the external system or environment. This requires massive investment in areas like machine learning, artificial intelligence, big data, enabling increased computational power, development of new learning algorithms, etc. This means that organizations have to align infrastructure and capability while also working with external environments through public relations, lobbying groups and policymakers to chaperone a comprehensive and a very complex hard-to-replicate learning organism.
- Investment in brand: Brand personifies the value attributes of an organization. One connects brand to customer experience and perception of the organization’s product. To manage scale and grow, organizations must invest in brand: to capture increased mindshare of the consumer. In complexity science terms, the internal systems are shaped to emit powerful signals to the external environment and urge a response. Brand and learning work together to allow a harmonic growth of an internal system in the context of its immediate environment.
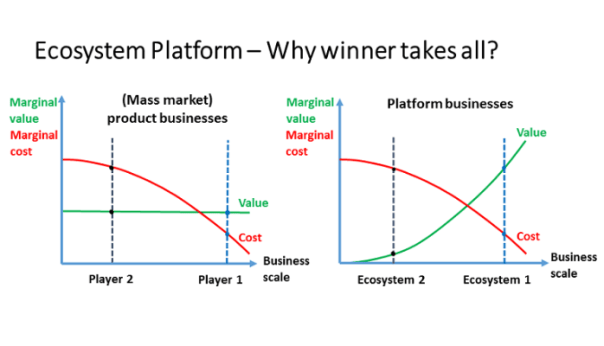
However, one must revert to the science of complexity to understand the long-term challenges of a winner-take-all mechanism. We have already seen the example that what is good for the individual bull-elk might not be the best for the species in the long-term. We see that super-linear scaling systems also emits significant negative by-products. Thus, the question that we need to ask is whether the organizations are paradoxically cultivating their own seeds of destruction in their ambitions of pursuing scale and market entrenchment.
Complex Physical and Adaptive Systems
There are two models in complexity. Complex Physical Systems and Complex Adaptive Systems! For us to grasp the patterns that are evolving, and much of it seemingly out of our control – it is important to understand both these models. One could argue that these models are mutually exclusive. While the existing body of literature might be inclined toward supporting that argument, we also find some degree of overlap that makes our understanding of complexity unstable. And instability is not to be construed as a bad thing! We might operate in a deterministic framework, and often, we might operate in the realms of a gradient understanding of volatility associated with outcomes. Keeping this in mind would be helpful as we deep dive into the two models. What we hope is that our understanding of these models would raise questions and establish mental frameworks for intentional choices that we are led to make by the system or make to influence the evolution of the system.
Complex Physical Systems (CPS)
Complex Physical Systems are bounded by certain laws. If there are initial conditions or elements in the system, there is a degree of predictability and determinism associated with the behavior of the elements governing the overarching laws of the system. Despite the tautological nature of the term (Complexity Physical System) which suggests a physical boundary, the late 1900’s surfaced some nuances to this model. In other words, if there is a slight and an arbitrary variation in the initial conditions, the outcome could be significantly different from expectations. The assumption of determinism is put to the sword. The notion that behaviors will follow established trajectories if rules are established and the laws are defined have been put to test. These discoveries by introspection offers an insight into the developmental block of complex physical systems and how a better understanding of it will enable us to acknowledge such systems when we see it and thereafter allow us to establish certain toll-gates and actions to navigate, to the extent possible, to narrow the region of uncertainty around outcomes.

The universe is designed as a complex physical system. Just imagine! Let this sink in a bit. A complex physical system might be regarded relatively simpler than a complex adaptive system. And with that in mind, once again …the universe is a complex physical system. We are awed by the vastness and scale of the universe, we regard the skies with an illustrious reverence and we wonder and ruminate on what lies beyond the frontiers of a universe, if anything. Really, there is nothing bigger than the universe in the physical realm and yet we regard it as a simple system. A “Simple” Complex Physical System. In fact, the behavior of ants that lead to the sustainability of an ant colony, is significantly more complex: and we mean by orders of magnitude.

Complexity behavior in nature reflects the tendency of large systems with many components to evolve into a poised “critical” state where minor disturbances or arbitrary changes in initial conditions can create a seemingly catastrophic impact on the overall system such that system changes significantly. And that happens not by some invisible hand or some uber design. What is fundamental to understanding complex systems is to understand that complexity is defined as the variability of the system. Depending on our lens, the scale of variability could change and that might lead to different apparatus that might be required to understand the system. Thus, determinism is not the measure: Stephen Jay Gould has argued that it is virtually impossible to predict the future. We have hindsight explanatory powers but not predictable powers. Hence, systems that start from the initial state over time might represent an outcome that is distinguishable in form and content from the original state. We see complex physical systems all around us. Snowflakes, patterns on coastlines, waves crashing on a beach, rain, etc.
Complex Adaptive Systems (CAS)
Complex adaptive systems, on the contrary, are learning systems that evolve. They are composed of elements which are called agents that interact with one another and adapt in response to the interactions.

Markets are a good example of complex adaptive systems at work.
CAS agents have three levels of activity. As described by Johnson in Complexity Theory: A Short Introduction – the three levels of activity are:
- Performance (moment by moment capabilities): This establishes the locus of all behavioral elements that signify the agent at a given point of time and thereafter establishes triggers or responses. For example, if an object is approaching and the response of the agent is to run, that would constitute a performance if-then outcome. Alternatively, it could be signals driven – namely, an ant emits a certain scent when it finds food: other ants will catch on that trail and act, en masse, to follow the trail. Thus, an agent or an actor in an adaptive system has detectors which allows them to capture signals from the environment for internal processing and it also has the effectors that translate the processing to higher order signals that influence other agents to behave in certain ways in the environment. The signal is the scent that creates these interactions and thus the rubric of a complex adaptive system.
- Credit assignment (rating the usefulness of available capabilities): When the agent gathers experience over time, the agent will start to rely heavily on certain rules or heuristics that they have found useful. It is also typical that these rules may not be the best rules, but it could be rules that are a result of first discovery and thus these rules stay. Agents would rank these rules in some sequential order and perhaps in an ordinal ranking to determine what is the best rule to fall back on under certain situations. This is the crux of decision making. However, there are also times when it is difficult to assign a rank to a rule especially if an action is setting or laying the groundwork for a future course of other actions. A spider weaving a web might be regarded as an example of an agent expending energy with the hope that she will get some food. This is a stage setting assignment that agents have to undergo as well. One of the common models used to describe this best is called the bucket-brigade algorithm which essentially states that the strength of the rule depends on the success of the overall system and the agents that constitute it. In other words, all the predecessors and successors need to be aware of only the strengths of the previous and following agent and that is done by some sort of number assignment that becomes stronger from the beginning of the origin of the system to the end of the system. If there is a final valuable end-product, then the pathway of the rules reflect success. Once again, it is conceivable that this might not be the optimal pathway but a satisficing pathway to result in a better system.
- Rule discovery (generating new capabilities): Performance and credit assignment in agent behavior suggest that the agents are governed by a certain bias. If the agents have been successful following certain rules, they would be inclined toward following those rules all the time. As noted, rules might not be optimal but satisficing. Is improvement a matter of just incremental changes to the process? We do see major leaps in improvement … so how and why does this happen? In other words, someone in the process have decided to take a different rule despite their experiences. It could have been an accident or very intentional.
One of the theories that have been presented is that of building blocks. CAS innovation is a result of reconfiguring the various components in new ways. One quips that if energy is neither created, nor destroyed …then everything that exists today or will exist tomorrow is nothing but a reconfiguration of energy in new ways. All of tomorrow resides in today … just patiently waiting to be discovered. Agents create hypotheses and experiment in the petri dish by reconfiguring their experiences and other agent’s experiences to formulate hypotheses and the runway for discovery. In other words, there is a collaboration element that comes into play where the interaction of the various agents and their assignment as a group to a rule also sets the stepping stone for potential leaps in innovation.
Another key characteristic of CAS is that the elements are constituted in a hierarchical order. Combinations of agents at a lower level result in a set of agents higher up and so on and so forth. Thus, agents in higher hierarchical orders take on some of the properties of the lower orders but it also includes the interaction rules that distinguishes the higher order from the lower order.
The Big Data Movement: Importance and Relevance today?
We are entering into a new age wherein we are interested in picking up a finer understanding of relationships between businesses and customers, organizations and employees, products and how they are being used, how different aspects of the business and the organizations connect to produce meaningful and actionable relevant information, etc. We are seeing a lot of data, and the old tools to manage, process and gather insights from the data like spreadsheets, SQL databases, etc., are not scalable to current needs. Thus, Big Data is becoming a framework to approach how to process, store and cope with the reams of data that is being collected.

According to IDC, it is imperative that organizations and IT leaders focus on the ever-increasing volume, variety and velocity of information that forms big data.
- Volume. Many factors contribute to the increase in data volume – transaction-based data stored through the years, text data constantly streaming in from social media, increasing amounts of sensor data being collected, etc. In the past, excessive data volume created a storage issue. But with today’s decreasing storage costs, other issues emerge, including how to determine relevance amidst the large volumes of data and how to create value from data that is relevant.
- Variety. Data today comes in all types of formats – from traditional databases to hierarchical data stores created by end users and OLAP systems, to text documents, email, meter-collected data, video, audio, stock ticker data and financial transactions. By some estimates, 80 percent of an organization’s data is not numeric! But it still must be included in analyses and decision making.
- Velocity. According to Gartner, velocity “means both how fast data is being produced and how fast the data must be processed to meet demand.” RFID tags and smart metering are driving an increasing need to deal with torrents of data in near-real time. Reacting quickly enough to deal with velocity is a challenge to most organizations.
SAS has added two additional dimensions:
- Variability. In addition to the increasing velocities and varieties of data, data flows can be highly inconsistent with periodic peaks. Is something big trending in the social media? Daily, seasonal and event-triggered peak data loads can be challenging to manage – especially with social media involved.
- Complexity. When you deal with huge volumes of data, it comes from multiple sources. It is quite an undertaking to link, match, cleanse and transform data across systems. However, it is necessary to connect and correlate relationships, hierarchies and multiple data linkages or your data can quickly spiral out of control. Data governance can help you determine how disparate data relates to common definitions and how to systematically integrate structured and unstructured data assets to produce high-quality information that is useful, appropriate and up-to-date.

So to reiterate, Big Data is a framework stemming from the realization that the data has gathered significant pace and that it’s growth has exceeded the capacity for an organization to handle, store and analyze the data in a manner that offers meaningful insights into the relationships between data points. I am calling this a framework, unlike other materials that call Big Data a consequent of the inability of organizations to handle mass amounts of data. I refer to Big Data as a framework because it sets the parameters around an organizations’ decision as to when and which tools must be deployed to address the data scalability issues.

Thus to put the appropriate parameters around when an organization must consider Big Data as part of their analytics roadmap in order to understand the patterns of data better, they have to answer the following ten questions:
- What are the different types of data that should be gathered?
- What are the mechanisms that have to be deployed to gather the relevant data?
- How should the data be processed, transformed and stored?
- How do we ensure that there is no single point of failure in data storage and data loss that may compromise data integrity?
- What are the models that have to be used to analyze the data?
- How are the findings of the data to be distributed to relevant parties?
- How do we assure the security of the data that will be distributed?
- What mechanisms do we create to implement feedback against the data to preserve data integrity?
- How do we morph the big data model into new forms that accounts for new patterns to reflect what is meaningful and actionable?
- How do we create a learning path for the big data model framework?
Some of the existing literature have commingled Big Data framework with analytics. In fact, the literature has gone on to make a rather assertive statement i.e. that Big Data and predictive analytics be looked upon in the same vein. Nothing could be further from the truth!
There are several tools available in the market to do predictive analytics against a set of data that may not qualify for the Big Data framework. While I was the CFO at Atari, we deployed business intelligence tools using Microstrategy, and Microstrategy had predictive modules. In my recent past, we had explored SAS and Minitab tools to do predictive analytics. In fact, even Excel can do multivariate, ANOVA and regressions analysis and best curve fit analysis. These analytical techniques have been part of the analytics arsenal for a long time. Different data sizes may need different tools to instantiate relevant predictive analysis. This is a very important point because companies that do not have Big Data ought to seriously reconsider their strategy of what tools and frameworks to use to gather insights. I have known companies that have gone the Big Data route, although all data points ( excuse my pun), even after incorporating capacity and forecasts, suggest that alternative tools are more cost-effective than implementing Big Data solutions. Big Data is not a one-size fit-all model. It is an expensive implementation. However, for the right data size which in this case would be very large data size, Big Data implementation would be extremely beneficial and cost effective in terms of the total cost of ownership.
Areas where Big Data Framework can be applied!
Some areas lend themselves to the application of the Big Data Framework. I have identified broadly four key areas:
- Marketing and Sales: Consumer behavior, marketing campaigns, sales pipelines, conversions, marketing funnels and drop-offs, distribution channels are all areas where Big Data can be applied to gather deeper insights.
- Human Resources: Employee engagement, employee hiring, employee retention, organization knowledge base, impact of cross-functional training, reviews, compensation plans are elements that Big Data can surface. After all, generally over 60% of company resources are invested in HR.
- Production and Operational Environments: Data growth, different types of data appended as the business learns about the consumer, concurrent usage patterns, traffic, web analytics are prime examples.
- Financial Planning and Business Operational Analytics: Predictive analytics around bottoms-up sales, marketing campaigns ROI, customer acquisitions costs, earned media and paid media, margins by SKU’s and distribution channels, operational expenses, portfolio evaluation, risk analysis, etc., are some of the examples in this category.
Hadoop: A Small Note!
Hadoop is becoming a more widely accepted tool in addressing Big Data Needs. It was invented by Google so they could index the structural and text information that they were collecting and present meaningful and actionable results to the users quickly. It was further developed by Yahoo that tweaked Hadoop for enterprise applications.
Hadoop runs on a large number of machines that don’t share memory or disks. The Hadoop software runs on each of these machines. Thus, if you have for example – over 10 gigabytes of data – you take that data and spread that across different machines. Hadoop tracks where all these data resides! The servers or machines are called nodes, and the common logical categories around which the data is disseminated are called clusters. Thus each server operates on its own little piece of the data, and then once the data is processed, the results are delivered to the main client as a unified whole. The method of reducing the disparate sources of information residing in various nodes and clusters into one unified whole is the process of MapReduce, an important mechanism of Hadoop. You will also hear something called Hive which is nothing but a data warehouse. This could be a structured or unstructured warehouse upon which the Hadoop works upon, processes data, enables redundancy across the clusters and offers a unified solution through the MapReduce function.

Personally, I have always been interested in Business Intelligence. I have always considered BI as a stepping stone, in the new age, to be a handy tool to truly understand a business and develop financial and operational models that are fairly close to the trending insights that the data generates. So my ear is always to the ground as I follow the developments in this area … and though I have not implemented a Big Data solution, I have always been and will continue to be interested in seeing its applications in certain contexts and against the various use cases in organizations.
