Blog Archives
Navigating Chaos and Model Thinking
An inherent property of a chaotic system is that slight changes in initial conditions in the system result in a disproportionate change in outcome that is difficult to predict. Chaotic systems appear to create outcomes that appear to be random: they are generated by simple and non-random processes but the complexity of such systems emerge over time driven by numerous iterations of simple rules. The elements that compose chaotic systems might be few in number, but these elements work together to produce an intricate set of dynamics that amplifies the outcome and makes it hard to be predictable. These systems evolve over time, doing so according to rules and initial conditions and how the constituent elements work together.

Complex systems are characterized by emergence. The interactions between the elements of the system with its environment create new properties which influence the structural development of the system and the roles of the agents. In such systems there is self-organization characteristics that occur, and hence it is difficult to study and effect a system by studying the constituent parts that comprise it. The task becomes even more formidable when one faces the prevalent reality that most systems exhibit non-linear dynamics.
So how do we incorporate management practices in the face of chaos and complexity that is inherent in organization structure and market dynamics? It would be interesting to study this in light of the evolution of management principles in keeping with the evolution of scientific paradigms.

Newtonian Mechanics and Taylorism
Traditional organization management has been heavily influenced by Newtonian mechanics. The five key assumptions of Newtonian mechanics are:
- Reality is objective
- Systems are linear and there is a presumption that all underlying cause and effect are linear
- Knowledge is empirical and acquired through collecting and analyzing data with the focus on surfacing regularities, predictability and control
- Systems are inherently efficient. Systems almost always follows the path of least resistance
- If inputs and process is managed, the outcomes are predictable
Frederick Taylor is the father of operational research and his methods were deployed in automotive companies in the 1940’s. Workers and processes are input elements to ensure that the machine functions per expectations. There was a linearity employed in principle. Management role was that of observation and control and the system would best function under hierarchical operating principles. Mass and efficient production were the hallmarks of management goal.

Randomness and the Toyota Way
The randomness paradigm recognized uncertainty as a pervasive constant. The various methods that Toyota Way invoked around 5W rested on the assumption that understanding the cause and effect is instrumental and this inclined management toward a more process-based deployment. Learning is introduced in this model as a dynamic variable and there is a lot of emphasis on the agents and providing them the clarity and purpose of their tasks. Efficiencies and quality are presumably driven by the rank and file and autonomous decisions are allowed. The management principle moves away from hierarchical and top-down to a more responsibility driven labor force.
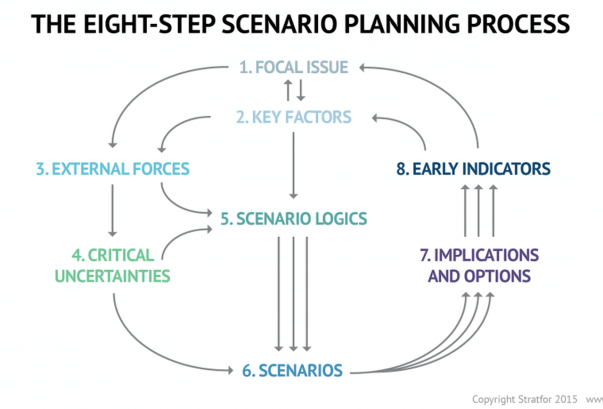
Complexity and Chaos and the Nimble Organization
Increasing complexity has led to more demands on the organization. With the advent of social media and rapid information distribution and a general rise in consciousness around social impact, organizations have to balance out multiple objectives. Any small change in initial condition can lead to major outcomes: an advertising mistake can become a global PR nightmare; a word taken out of context could have huge ramifications that might immediately reflect on the stock price; an employee complaint could force management change. Increasing data and knowledge are not sufficient to ensure long-term success. In fact, there is no clear recipe to guarantee success in an age fraught with non-linearity, emergence and disequilibrium. To succeed in this environment entails the development of a learning organization that is not governed by fixed top-down rules: rather the rules are simple and the guidance is around the purpose of the system or the organization. It is best left to intellectual capital to self-organize rapidly in response to external information to adapt and make changes to ensure organization resilience and success.
Companies are dynamic non-linear adaptive systems. The elements in the system are constantly interacting between themselves and their external environment. This creates new emergent properties that are sensitive to the initial conditions. A change in purpose or strategic positioning could set a domino effect and can lead to outcomes that are not predictable. Decisions are pushed out to all levels in the organization, since the presumption is that local and diverse knowledge that spontaneously emerge in response to stimuli is a superior structure than managing for complexity in a centralized manner. Thus, methods that can generate ideas, create innovation habitats, and embrace failures as providing new opportunities to learn are best practices that companies must follow. Traditional long-term planning and forecasting is becoming a far harder exercise and practically impossible. Thus, planning is more around strategic mindset, scenario planning, allowing local rules to auto generate without direct supervision, encourage dissent and diversity, stimulate creativity and establishing clarity of purpose and broad guidelines are the hall marks of success.
Principles of Leadership in a New Age
We have already explored the fact that traditional leadership models originated in the context of mass production and efficiencies. These models are arcane in our information era today, where systems are characterized by exponential dynamism of variables, increased density of interactions, increased globalization and interconnectedness, massive information distribution at increasing rapidity, and a general toward economies driven by free will of the participants rather than a central authority.

Complexity Leadership Theory (Uhl-Bien) is a “framework for leadership that enables the learning, creative and adaptive capacity of complex adaptive systems in knowledge-producing organizations or organizational units. Since planning for the long-term is virtually impossible, Leadership has to be armed with different tool sets to steer the organization toward achieving its purpose. Leaders take on enabler role rather than controller role: empowerment supplants control. Leadership is not about focus on traits of a single leader: rather, it redirects emphasis from individual leaders to leadership as an organizational phenomenon. Leadership is a trait rather than an individual. We recognize that complex systems have lot of interacting agents – in business parlance, which might constitute labor and capital. Introducing complexity leadership is to empower all of the agents with the ability to lead their sub-units toward a common shared purpose. Different agents can become leaders in different roles as their tasks or roles morph rapidly: it is not necessarily defined by a formal appointment or knighthood in title.
Thus, complexity of our modern-day reality demands a new strategic toolset for the new leader. The most important skills would be complex seeing, complex thinking, complex knowing, complex acting, complex trusting and complex being. (Elena Osmodo, 2012)

Complex Seeing: Reality is inherently subjective. It is a page of the Heisenberg Uncertainty principle that posits that the independence between the observer and the observed is not real. If leaders are not aware of this independence, they run the risk of engaging in decisions that are fraught with bias. They will continue to perceive reality with the same lens that they have perceived reality in the past, despite the fact that undercurrents and riptides of increasingly exponential systems are tearing away their “perceived reality.” Leader have to be conscious about the tectonic shifts, reevaluate their own intentions, probe and exclude biases that could cloud the fidelity of their decisions, and engage in a continuous learning process. The ability to sift and see through this complexity sets the initial condition upon which the entire system’s efficacy and trajectory rests.
Complex Thinking: Leaders have to be cognizant of falling prey to linear simple cause and effect thinking. On the contrary, leaders have to engage in counter-intuitive thinking, brainstorming and creative thinking. In addition, encouraging dissent, debates and diversity encourage new strains of thought and ideas.

Complex Feeling: Leaders must maintain high levels of energy and be optimistic of the future. Failures are not scoffed at; rather they are simply another window for learning. Leaders have to promote positive and productive emotional interactions. The leaders are tasked to increase positive feedback loops while reducing negative feedback mechanisms to the extent possible. Entropy and attrition taxes any system as is: the leader’s job is to set up safe environment to inculcate respect through general guidelines and leading by example.
Complex Knowing: Leadership is tasked with formulating simple rules to enable learned and quicker decision making across the organization. Leaders must provide a common purpose, interconnect people with symbols and metaphors, and continually reiterate the raison d’etre of the organization. Knowing is articulating: leadership has to articulate and be humble to any new and novel challenges and counterfactuals that might arise. The leader has to establish systems of knowledge: collective learning, collaborative learning and organizational learning. Collective learning is the ability of the collective to learn from experiences drawn from the vast set of individual actors operating in the system. Collaborative learning results due to interaction of agents and clusters in the organization. Learning organization, as Senge defines it, is “where people continually expand their capacity to create the results they truly desire, where new and expansive patterns of thinking are nurtured, where collective aspirations are set free, and where people are continually learning to see the whole together.”
Complex Acting: Complex action is the ability of the leader to not only work toward benefiting the agents in his/her purview, but also to ensure that the benefits resonates to a whole which by definition is greater than the sum of the parts. Complex acting is to take specific action-oriented steps that largely reflect the values that the organization represents in its environmental context.
Complex Trusting: Decentralization requires conferring power to local agents. For decentralization to work effectively, leaders have to trust that the agents will, in the aggregate, work toward advancing the organization. The cost of managing top-down is far more than the benefits that a trust-based decentralized system would work in a dynamic environment resplendent with the novelty of chaos and complexity.
Complex Being: This is the ability of the leaser to favor and encourage communication across the organization rapidly. The leader needs to encourage relationships and inter-functional dialogue.
The role of complex leaders is to design adaptive systems that are able to cope with challenging and novel environments by establishing a few rules and encouraging agents to self-organize autonomously at local levels to solve challenges. The leader’s main role in this exercise is to set the strategic directions and the guidelines and let the organizations run.
Distribution Economics
Distribution is a method to get products and services to the maximum number of customers efficiently.

Complexity science is the study of complex systems and the problems that are multi-dimensional, dynamic and unpredictable. It constitutes a set of interconnected relationships that are not always abiding to the laws of cause and effect, but rather the modality of non-linearity. Thomas Kuhn in his pivotal essay: The Structure of Scientific Revolutions posits that anomalies that arise in scientific method rise to the level where it can no longer be put on hold or simmer on a back-burner: rather, those anomalies become the front line for new methods and inquiries such that a new paradigm necessarily must emerge to supplant the old conversations. It is this that lays the foundation of scientific revolution – an emergence that occurs in an ocean of seeming paradoxes and competing theories. Contrary to a simple scientific method that seeks to surface regularities in natural phenomenon, complexity science studies the effects that rules have on agents. Rules do not drive systems toward a predictable outcome: rather it sets into motion a high density of interactions among agents such that the system coalesces around a purpose: that being necessarily that of survival in context of its immediate environment. In addition, the learnings that follow to arrive at the outcome is then replicated over periods to ensure that the systems mutate to changes in the external environment. In theory, the generative rules leads to emergent behavior that displays patterns of parallelism to earlier known structures.
For any system to survive and flourish, distribution of information, noise and signals in and outside of a CPS or CAS is critical. We have touched at length that the system comprises actors and agents that work cohesively together to fulfill a special purpose. Specialization and scale matter! How is a system enabled to fulfill their purpose and arrive at a scale that ensures long-term sustenance? Hence the discussion on distribution and scale which is a salient factor in emergence of complex systems that provide the inherent moat of “defensibility” against internal and external agents working against it.
Distribution, in this context, refers to the quality and speed of information processing in the system. It is either created by a set of rules that govern the tie-ups between the constituent elements in the system or it emerges based on a spontaneous evolution of communication protocols that are established in response to internal and external stimuli. It takes into account the available resources in the system or it sets up the demands on resource requirements. Distribution capabilities have to be effective and depending upon the dynamics of external systems, these capabilities might have to be modified effectively. Some distribution systems have to be optimized or organized around efficiency: namely, the ability of the system to distribute information efficiently. On the other hand, some environments might call for less efficiency as the key parameter, but rather focus on establishing a scale – an escape velocity in size and interaction such that the system can dominate the influence of external environments. The choice between efficiency and size is framed by the long-term purpose of the system while also accounting for the exigencies of ebbs and flows of external agents that might threaten the system’s existence.

Since all systems are subject to the laws of entropy and the impact of unintended consequences, strategies have to be orchestrated accordingly. While it is always naïve to assume exactitude in the ultimate impact of rules and behavior, one would surmise that such systems have to be built around the fault lines of multiple roles for agents or group of agents to ensure that the system is being nudged, more than less, toward the desired outcome. Hence, distribution strategy is the aggregate impact of several types of channels of information that are actively working toward a common goal. The idea is to establish multiple channels that invoke different strategies while not cannibalizing or sabotaging an existing set of channels. These mutual exclusive channels have inherent properties that are distinguished by the capacity and length of the channels, the corresponding resources that the channels use and the sheer ability to chaperone the system toward the overall purpose.
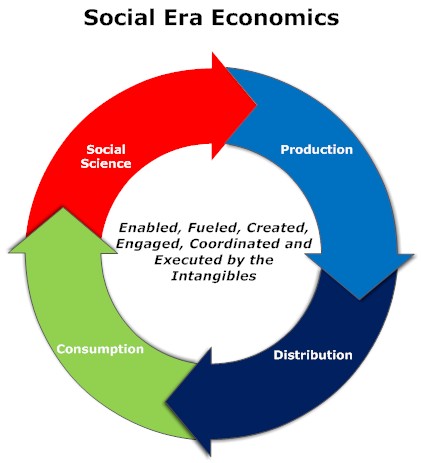
The complexity of the purpose and the external environment determines the strategies deployed and whether scale or efficiency are the key barometers for success. If a complex system must survive and hopefully replicate from strength to greater strength over time, size becomes more paramount than efficiency. Size makes up for the increased entropy which is the default tax on the system, and it also increases the possibility of the system to reach the escape velocity. To that end, managing for scale by compromising efficiency is a perfectly acceptable means since one is looking at the system with a long-term lens with built-in regeneration capabilities. However, not all systems might fall in this category because some environments are so dynamic that planning toward a long-term stability is not practical, and thus one has to quickly optimize for increased efficiency. It is thus obvious that scale versus efficiency involves risky bets around how the external environment will evolve. We have looked at how the systems interact with external environments: yet, it is just as important to understand how the actors work internally in a system that is pressed toward scale than efficiency, or vice versa. If the objective is to work toward efficiency, then capabilities can be ephemeral: one builds out agents and actors with capabilities that are mission-specific. On the contrary, scale driven systems demand capabilities that involve increased multi-tasking abilities, the ability to develop and learn from feedback loops, and to prime the constraints with additional resources. Scaling demand acceleration and speed: if a complex system can be devised to distribute information and learning at an accelerating pace, there is a greater likelihood that this system would dominate the environment.
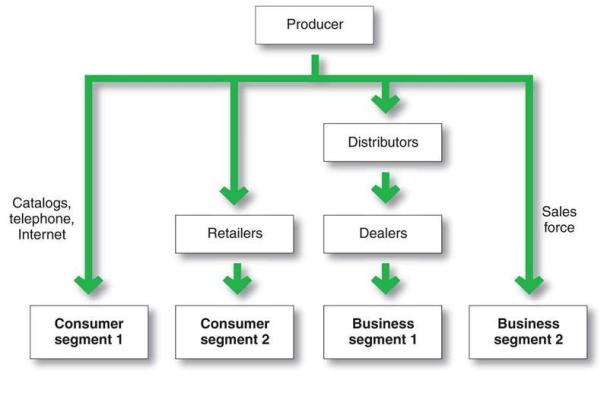
Scaling systems can be approached by adding more agents with varying capabilities. However, increased number of participants exponentially increase the permutations and combinations of channels and that can make the system sluggish. Thus, in establishing the purpose and the subsequent design of the system, it is far more important to establish the rules of engagement. Further, the rules might have some centralized authority that will directionally provide the goal while other rules might be framed in a manner to encourage a pure decentralization of authority such that participants act quickly in groups and clusters to enable execution toward a common purpose.
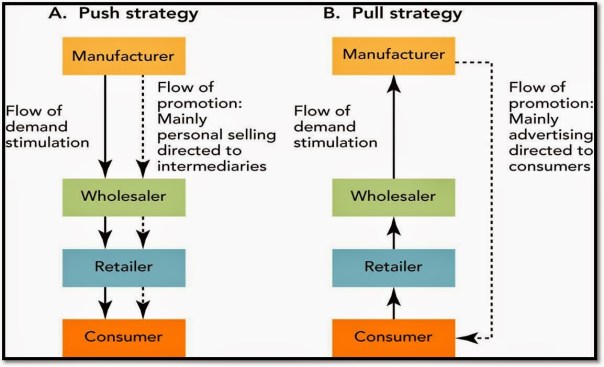
In business we are surrounded by uncertainty and opportunities. It is how we calibrate around this that ultimately reflects success. The ideal framework at work would be as follows:
- What are the opportunities and what are the corresponding uncertainties associated with the opportunities? An honest evaluation is in order since this is what sets the tone for the strategic framework and direction of the organization.
- Should we be opportunistic and establish rules that allow the system to gear toward quick wins: this would be more inclined toward efficiencies. Or should we pursue dominance by evaluating our internal capability and the probability of winning and displacing other systems that are repositioning in advance or in response to our efforts? At which point, speed and scale become the dominant metric and the resources and capabilities and the set of governing rules have to be aligned accordingly.
- How do we craft multiple channels within and outside of the system? In business lingo, that could translate into sales channels. These channels are selling products and services and can be adding additional value along the way to the existing set of outcomes that the system is engineered for. The more the channels that are mutually exclusive and clearly differentiated by their value propositions, the stronger the system and the greater the ability to scale quickly. These antennas, if you will, also serve to be receptors for new information which will feed data into the organization which can subsequently process and reposition, if the situation so warrants. Having as many differentiated antennas comprise what constitutes the distribution strategy of the organization.
- The final cut is to enable a multi-dimensional loop between external and internal system such that the system expands at an accelerating pace without much intervention or proportionate changes in rules. In other words, system expands autonomously – this is commonly known as the platform effect. Scale does not lead to platform effect although the platform effect most definitely could result in scale. However, scale can be an important contributor to platform effect, and if the latter gets root, then the overall system achieves efficiency and scale in the long run.
Network Theory and Network Effects
Complexity theory needs to be coupled with network theory to get a more comprehensive grasp of the underlying paradigms that govern the outcomes and morphology of emergent systems. In order for us to understand the concept of network effects which is commonly used to understand platform economics or ecosystem value due to positive network externalities, we would like to take a few steps back and appreciate the fundamental theory of networks. This understanding will not only help us to understand complexity and its emergent properties at a low level but also inform us of the impact of this knowledge on how network effects can be shaped to impact outcomes in an intentional manner.

There are first-order conditions that must be met to gauge whether the subject of the observation is a network. Firstly, networks are all about connectivity within and between systems. Understanding the components that bind the system would be helpful. However, do keep in mind that complexity systems (CPS and CAS) might have emergent properties due to the association and connectivity of the network that might not be fully explained by network theory. All the same, understanding networking theory is a building block to understanding emergent systems and the outcome of its structure on addressing niche and macro challenges in society.
Networks operates spatially in a different space and that has been intentionally done to allow some simplification and subsequent generalization of principles. The geometry of network is called network topology. It is a 2D perspective of connectivity.
Networks are subject to constraints (physical resources, governance constraint, temporal constraints, channel capacity, absorption and diffusion of information, distribution constraint) that might be internal (originated by the system) or external (originated in the environment that the network operates in).
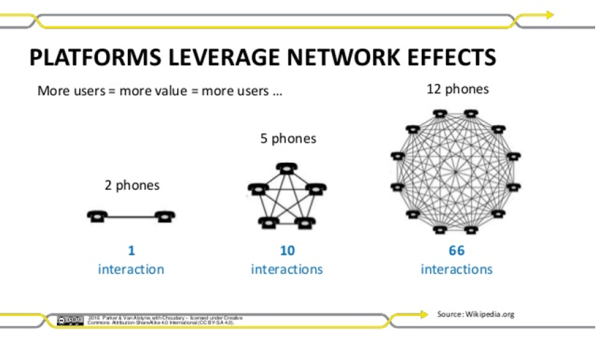
Finally, there is an inherent non-linearity impact in networks. As nodes increase linearly, connections will increase exponentially but might be subject to constraints. The constraints might define how the network structure might morph and how information and signals might be processed differently.
Graph theory is the most widely used tool to study networks. It consists of four parts: vertices which represent an element in the network, edges refer to relationship between nodes which we call links, directionality which refers to how the information is passed ( is it random and bi-directional or follows specific rules and unidirectional), channels that refer to bandwidth that carry information, and finally the boundary which establishes specificity around network operations. A graph can be weighted – namely, a number can be assigned to each length to reflect the degree of interaction or the strength of resources or the proximity of the nodes or the ordering of discernible clusters.
The central concept of network theory thus revolves around connectivity between nodes and how non-linear emergence occurs. A node can have multiple connections with other node/nodes and we can weight the node accordingly. In addition, the purpose of networks is to pass information in the most efficient manner possible which relays into the concept of a geodesic which is either the shortest path between two nodes that must work together to achieve a purpose or the least number of leaps through links that information must negotiate between the nodes in the network.
Technically, you look for the longest path in the network and that constitutes the diameter while you calculate the average path length by examining the shortest path between nodes, adding all of those paths up and then dividing by the number of pairs. Significance of understanding the geodesic allows an understanding of the size of the network and throughput power that the network is capable of.
Nodes are the atomic elements in the network. It is presumed that its degree of significance is related to greater number of connections. There are other factors that are important considerations: how adjacent or close are the nodes to one another, does some nodes have authority or remarkable influence on others, are nodes positioned to be a connector between other nodes, and how capable are the nodes in absorbing, processing and diffusing the information across the links or channels. How difficult is it for the agents or nodes in the network to make connections? It is presumed that if the density of the network is increased, then we create a propensity in the overall network system to increase the potential for increased connectivity.

As discussed previously, our understanding of the network is deeper once we understand the elements well. The structure or network topology is represented by the graph and then we must understand size of network and the patterns that are manifested in the visual depiction of the network. Patterns, for our purposes, might refer to clusters of nodes that are tribal or share geographical proximity that self-organize and thus influence the structure of the network. We will introduce a new term homophily where agents connect with those like themselves. This attribute presumably allows less resources needed to process information and diffuse outcomes within the cluster. Most networks have a cluster bias: in other words, there are areas where there is increased activity or increased homogeneity in attributes or some form of metric that enshrines a group of agents under one specific set of values or activities. Understanding the distribution of cluster and the cluster bias makes it easier to influence how to propagate or even dismantle the network. This leads to an interesting question: Can a network that emerges spontaneously from the informal connectedness between agents be subjected to some high dominance coefficient – namely, could there be nodes or links that might exercise significant weight on the network?
The network has to align to its environment. The environment can place constraints on the network. In some instances, the agents have to figure out how to overcome or optimize their purpose in the context of the presence of the environmental constraints. There is literature that suggests the existence of random networks which might be an initial state, but it is widely agreed that these random networks self-organize around their purpose and their interaction with its environment. Network theory assigns a number to the degree of distribution which means that all or most nodes have an equivalent degree of connectivity and there is no skewed influence being weighed on the network by a node or a cluster. Low numbers assigned to the degree of distribution suggest a network that is very democratic versus high number that suggests centralization. To get a more practical sense, a mid-range number assigned to a network constitutes a decentralized network which has close affinities and not fully random. We have heard of the six degrees of separation and that linkage or affinity is most closely tied to a mid-number assignment to the network.
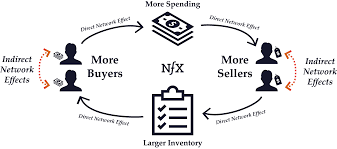
We are now getting into discussions on scale and binding this with network theory. Metcalfe’s law states that the value of a network grows as a square of the number of the nodes in the network. More people join the network, the more valuable the network. Essentially, there is a feedback loop that is created, and this feedback loop can kindle a network to grow exponentially. There are two other topics – Contagion and Resilience. Contagion refers to the ability of the agents to diffuse information. This information can grow the network or dismantle it. Resilience refers to how the network is organized to preserve its structure. As you can imagine, they have huge implications that we see. How do certain ideas proliferate over others, how does it cluster and create sub-networks which might grow to become large independent networks and how it creates natural defense mechanisms against self-immolation and destruction?
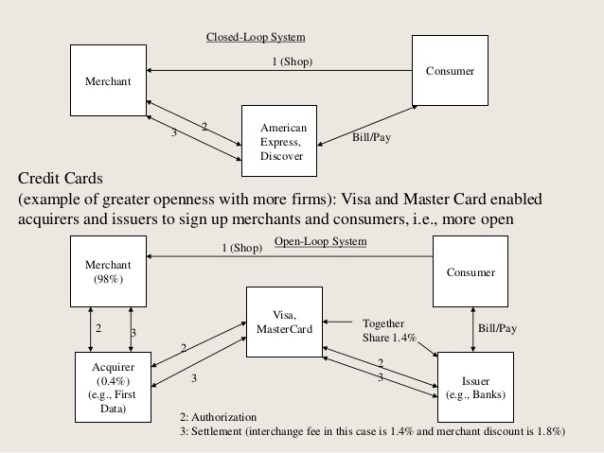
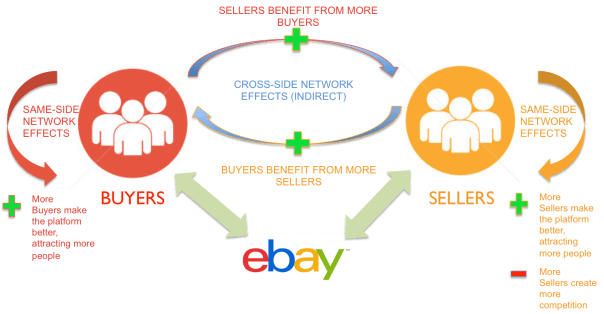
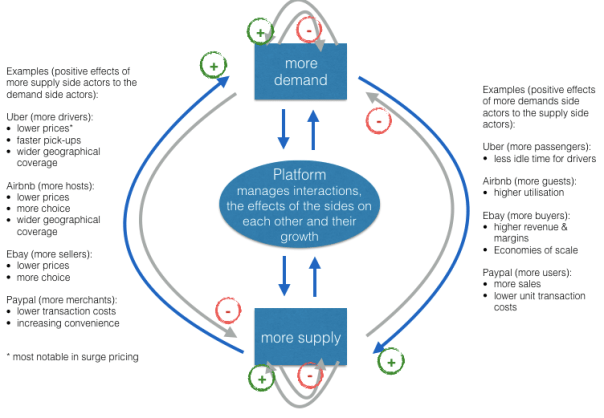
Network effect is commonly known as externalities in economics. It is an effect that is external to the transaction but influences the transaction. It is the incremental benefit gained by an existing user for each new user that joins the network. There are two types of network effects: Direct network effects and Indirect network effect. Direct network effects are same side effects. The value of a service goes up as the number of users goes up. For example, if more people have phones, it is useful for you to have a phone. The entire value proposition is one-sided. Indirect networks effects are multi-sided. It lends itself to our current thinking around platforms and why smart platforms can exponentially increase the network. The value of the service increases for one user group when a new user group joins the network. Take for example the relationship between credit card banks, merchants and consumers. There are three user groups, and each gather different value from the network of agents that have different roles. If more consumers use credit cards to buy, more merchants will sign up for the credit cards, and as more merchants sign up – more consumers will sign up with the bank to get more credit cards. This would be an example of a multi-sided platform that inherently has multi-sided network effects. The platform inherently gains significant power such that it becomes more valuable for participants in the system to join the network despite the incremental costs associated with joining the network. Platforms that are built upon effective multi-sided network effects grow quickly and are generally sustainable. Having said that, it could be just as easy that a few dominant bad actors in the network can dismantle and unravel the network completely. We often hear of the tipping point: namely, that once the platform reaches a critical mass of users, it would be difficult to dismantle it. That would certainly be true if the agents and services are, in the aggregate, distributed fairly across the network: but it is also possible that new networks creating even more multi-sided network effects could displace an entrenched network. Hence, it is critical that platform owners manage the quality of content and users and continue to look for more opportunities to introduce more user groups to entrench and yet exponentially grow the network.
Model Thinking
| Model Framework |
The fundamental tenet of theory is the concept of “empiria“. Empiria refers to our observations. Based on observations, scientists and researchers posit a theory – it is part of scientific realism.
A scientific model is a causal explanation of how variables interact to produce a phenomenon, usually linearly organized. A model is a simplified map consisting of a few, primary variables that is gauged to have the most explanatory powers for the phenomenon being observed. We discussed Complex Physical Systems and Complex Adaptive Systems early on this chapter. It is relatively easier to map CPS to models than CAS, largely because models become very unwieldy as it starts to internalize more variables and if those variables have volumes of interaction between them. A simple analogy would be the use of multiple regression models: when you have a number of independent variables that interact strongly between each other, autocorrelation errors occur, and the model is not stable or does not have predictive value.

Research projects generally tend to either look at a case study or alternatively, they might describe a number of similar cases that are logically grouped together. Constructing a simple model that can be general and applied to many instances is difficult, if not impossible. Variables are subject to a researcher’s lack of understanding of the variable or the volatility of the variable. What further accentuates the problem is that the researcher misses on the interaction of how the variables play against one another and the resultant impact on the system. Thus, our understanding of our system can be done through some sort of model mechanics but, yet we share the common belief that the task of building out a model to provide all of the explanatory answers are difficult, if not impossible. Despite our understanding of our limitations of modeling, we still develop frameworks and artifact models because we sense in it a tool or set of indispensable tools to transmit the results of research to practical use cases. We boldly generalize our findings from empiria into general models that we hope will explain empiria best. And let us be mindful that it is possible – more so in the CAS systems than CPS that we might have multiple models that would fight over their explanatory powers simply because of the vagaries of uncertainty and stochastic variations.
Popper says: “Science does not rest upon rock-bottom. The bold structure of its theories rises, as it were, above a swamp. It is like a building erected on piles. The piles are driven down from above into the swamp, but not down to any natural or ‘given’ base; and when we cease our attempts to drive our piles into a deeper layer, it is not because we have reached firm ground. We simply stop when we are satisfied that they are firm enough to carry the structure, at least for the time being”. This leads to the satisficing solution: if a model can choose the least number of variables to explain the greatest amount of variations, the model is relatively better than other models that would select more variables to explain the same. In addition, there is always a cost-benefit analysis to be taken into consideration: if we add x number of variables to explain variation in the outcome but it is not meaningfully different than variables less than x, then one would want to fall back on the less-variable model because it is less costly to maintain.
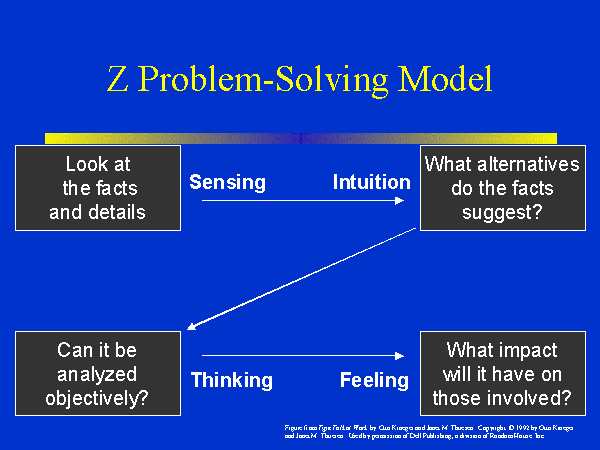
Researchers must address three key elements in the model: time, variation and uncertainty. How do we craft a model which reflects the impact of time on the variables and the outcome? How to present variations in the model? Different variables might vary differently independent of one another. How do we present the deviation of the data in a parlance that allows us to make meaningful conclusions regarding the impact of the variations on the outcome? Finally, does the data that is being considered are actual or proxy data? Are the observations approximate? How do we thus draw the model to incorporate the fuzziness: would confidence intervals on the findings be good enough?
Two other equally other concepts in model design is important: Descriptive Modeling and Normative Modeling.
Descriptive models aim to explain the phenomenon. It is bounded by that goal and that goal only.
There are certain types of explanations that they fall back on: explain by looking at data from the past and attempting to draw a cause and effect relationship. If the researcher is able to draw a complete cause and effect relationship that meets the test of time and independent tests to replicate the results, then the causality turns into law for the limited use-case or the phenomenon being explained. Another explanation method is to draw upon context: explaining a phenomenon by looking at the function that the activity fulfills in its context. For example, a dog barks at a stranger to secure its territory and protect the home. The third and more interesting type of explanation is generally called intentional explanation: the variables work together to serve a specific purpose and the researcher determines that purpose and thus, reverse engineers the understanding of the phenomenon by understanding the purpose and how the variables conform to achieve that purpose.
This last element also leads us to thinking through the other method of modeling – namely, normative modeling. Normative modeling differs from descriptive modeling because the target is not to simply just gather facts to explain a phenomenon, but rather to figure out how to improve or change the phenomenon toward a desirable state. The challenge, as you might have already perceived, is that the subjective shadow looms high and long and the ultimate finding in what would be a normative model could essentially be a teleological representation or self-fulfilling prophecy of the researcher in action. While this is relatively more welcome in a descriptive world since subjectivism is diffused among a larger group that yields one solution, it is not the best in a normative world since variation of opinions that reflect biases can pose a problem.
How do we create a representative model of a phenomenon? First, we weigh if the phenomenon is to be understood as a mere explanation or to extend it to incorporate our normative spin on the phenomenon itself. It is often the case that we might have to craft different models and then weigh one against the other that best represents how the model can be explained. Some of the methods are fairly simple as in bringing diverse opinions to a table and then agreeing upon one specific model. The advantage of such an approach is that it provides a degree of objectivism in the model – at least in so far as it removes the divergent subjectivity that weaves into the various models. Other alternative is to do value analysis which is a mathematical method where the selection of the model is carried out in stages. You define the criteria of the selection and then the importance of the goal (if that be a normative model). Once all of the participants have a general agreement, then you have the makings of a model. The final method is to incorporate all all of the outliers and the data points in the phenomenon that the model seeks to explain and then offer a shared belief into those salient features in the model that would be best to apply to gain information of the phenomenon in a predictable manner.

There are various languages that are used for modeling:
Written Language refers to the natural language description of the model. If price of butter goes up, the quantity demanded of the butter will go down. Written language models can be used effectively to inform all of the other types of models that follow below. It often goes by the name of “qualitative” research, although we find that a bit limiting. Just a simple statement like – This model approximately reflects the behavior of people living in a dense environment …” could qualify as a written language model that seeks to shed light on the object being studied.
Icon Models refer to a pictorial representation and probably the earliest form of model making. It seeks to only qualify those contours or shapes or colors that are most interesting and relevant to the object being studied. The idea of icon models is to pictorially abstract the main elements to provide a working understanding of the object being studied.
Topological Models refer to how the variables are placed with respect to one another and thus helps in creating a classification or taxonomy of the model. Once can have logical trees, class trees, Venn diagrams, and other imaginative pictorial representation of fields to further shed light on the object being studied. In fact, pictorial representations must abide by constant scale, direction and placements. In other words, if the variables are placed on a different scale on different maps, it would be hard to draw logical conclusions by sight alone. In addition, if the placements are at different axis in different maps or have different vectors, it is hard to make comparisons and arrive at a shared consensus and a logical end result.
Arithmetic Models are what we generally fall back on most. The data is measured with an arithmetic scale. It is done via tables, equations or flow diagrams. The nice thing about arithmetic models is that you can show multiple dimensions which is not possible with other modeling languages. Hence, the robustness and the general applicability of such models are huge and thus is widely used as a key language to modeling.
Analogous Models refer to crafting explanations using the power of analogy. For example, when we talk about waves – we could be talking of light waves, radio waves, historical waves, etc. These metaphoric representations can be used to explain phenomenon, but at best, the explanatory power is nebulous, and it would be difficult to explain the variations and uncertainties between two analogous models. However, it still is used to transmit information quickly through verbal expressions like – “Similarly”, “Equivalently”, “Looks like ..” etc. In fact, extrapolation is a widely used method in modeling and we would ascertain this as part of the analogous model to a great extent. That is because we time-box the variables in the analogous model to one instance and the extrapolated model to another instance and we tie them up with mathematical equations.
The Law of Unintended Consequences
The Law of Unintended Consequence is that the actions of a central body that might claim omniscient, omnipotent and omnivalent intelligence might, in fact, lead to consequences that are not anticipated or unintended.
The concept of the Invisible Hand as introduced by Adam Smith argued that it is the self-interest of all the market agents that ultimately create a system that maximizes the good for the greatest amount of people.
Robert Merton, a sociologist, studied the law of unintended consequence. In an influential article titled “The Unanticipated Consequences of Purposive Social Action,” Merton identified five sources of unanticipated consequences.
Ignorance makes it difficult and impossible to anticipate the behavior of every element or the system which leads to incomplete analysis.
Errors that might occur when someone uses historical data and applies the context of history into the future. Linear thinking is a great example of an error that we are wrestling with right now – we understand that there are systems, looking back, that emerge exponentially but it is hard to decipher the outcome unless one were to take a leap of faith.
Biases work its way into the study as well. We study a system under the weight of our biases, intentional or unintentional. It is hard to strip that away even if there are different bodies of thought that regard a particular system and how a certain action upon the system would impact it.
Weaved with the element of bias is the element of basic values that may require or prohibit certain actions even if the long-term impact is unfavorable. A good example would be the toll gates established by the FDA to allow drugs to be commercialized. In its aim to provide a safe drug, the policy might be such that the latency of the release of drugs for experiments and commercial purposes are so slow that many patients who might otherwise benefit from the release of the drug lose out.
Finally, he discusses the self-fulfilling prophecy which suggests that tinkering with the elements of a system to avert a catastrophic negative event might in actuality result in the event.
It is important however to acknowledge that unintended consequences do not necessarily lead to a negative outcome. In fact, there are could be unanticipated benefits. A good example is Viagra which started off as a pill to lower blood pressure, but one discovered its potency to solve erectile dysfunctions. The discovery that ships that were sunk became the habitat and formation of very rich coral reefs in shallow waters that led scientists to make new discoveries in the emergence of flora and fauna of these habitats.

If there are initiatives exercised that are considered “positive initiative” to influence the system in a manner that contribute to the greatest good, it is often the case that these positive initiatives might prove to be catastrophic in the long term. Merton calls the cause of this unanticipated consequence as something called the product of the “relevance paradox” where decision makers thin they know their areas of ignorance regarding an issue, obtain the necessary information to fill that ignorance gap but intentionally or unintentionally neglect or disregard other areas as its relevance to the final outcome is not clear or not lined up to values. He goes on to argue, in a nutshell, that unintended consequences relate to our hubris – we are hardwired to put our short-term interest over long term interest and thus we tinker with the system to surface an effect which later blow back in unexpected forms. Albert Camus has said that “The evil in the world almost always comes of ignorance, and good intentions may do as much harm as malevolence if they lack understanding.”
An interesting emergent property that is related to the law of unintended consequence is the concept of Moral Hazard. It is a concept that individuals have incentives to alter their behavior when their risk or bad decision making is borne of diffused among others. For example:
If you have an insurance policy, you will take more risks than otherwise. The cost of those risks will impact the total economics of the insurance and might lead to costs being distributed from the high-risk takers to the low risk takers.

How do the conditions of the moral hazard arise in the first place? There are two important conditions that must hold. First, one party has more information than another party. The information asymmetry thus creates gaps in information and that creates a condition of moral hazard. For example, during 2006 when sub-prime mortgagors extended loans to individuals who had dubitable income and means to pay. The Banks who were buying these mortgages were not aware of it. Thus, they ended up holding a lot of toxic loans due to information asymmetry. Second, is the existence of an understanding that might affect the behavior of two agents. If a child knows that they are going to get bailed out by the parents, he/she might take some risks that he/she would otherwise might not have taken.
To counter the possibility of unintended consequences, it is important to raise our thinking to second-order thinking. Most of our thinking is simplistic and is based on opinions and not too well grounded in facts. There are a lot of biases that enter first order thinking and in fact, all of the elements that Merton touches on enters it – namely, ignorance, biases, errors, personal value systems and teleological thinking. Hence, it is important to get into second-order thinking – namely, the reasoning process is surfaced by looking at interactions of elements, temporal impacts and other system dynamics. We had mentioned earlier that it is still difficult to fully wrestle all the elements of emergent systems through the best of second-order thinking simply because the dynamics of a complex adaptive system or complex physical system would deny us that crown of competence. However, this fact suggests that we step away from simple, easy and defendable heuristics to measure and gauge complex systems.
Emergent Systems: Introduction
The whole is greater than the sum of its parts. “Emergent properties” refer to those properties that emerge that might be entirely unexpected. As discussed in CAS, they arise from the collaborative functioning of a system. In other words, emergent properties are properties of a group of items, but it would be erroneous for us to reduce such systems into properties of atomic elements and use those properties as binding elements to understand emergence Some common examples of emergent properties include cities, bee hives, ant colonies and market systems. Out thinking attributes causal effects – namely, that behavior of elements would cause certain behaviors in other hierarchies and thus an entity emerges at a certain state. However, we observe that a process of emergence is the observation of an effect without an apparent cause. Yet it is important to step back and regard the relationships and draw lines of attribution such that one can concur that there is an impact of elements at the lowest level that surfaces, in some manner, at the highest level which is the subject of our observation.

Jochenn Fromm in his paper “Types and Forms of Emergence” has laid this out best. He says that emergent properties are “amazing and paradox: fundamental but familiar.” In other words, emergent properties are changeless and changing, constant and fluctuating, persistent and shifting, inevitable and unpredictable. The most important note that he makes is that the emergent property is part of the system and at the same time it might not always be a part of the system. There is an undercurrent of novelty or punctuated gaps that might arise that is inexplicable, and it is this fact that renders true emergence virtually irreducible. Thus, failure is embodied in all emergent systems – failure being that the system does not behave according to expectation. Despite all rules being followed and quality thresholds are established at every toll gate at the highest level, there is still a possibility of failure which suggests that there is some missing information in the links. It is also possible that the missing information is dynamic – you do not step in the same water twice – which makes the study to predict emergent systems to be a rather difficult exercise. Depending on the lens through which we look at, the system might appear or disappear.
There are two types of emergence: Descriptive and Explanatory emergence. Descriptive emergence means that properties of wholes cannot be necessarily defined through the properties of the pasts. Explanatory emergence means laws of complex systems cannot be deduced from the laws of interaction of simpler elements that constitute it. Thus the emergence is a result of the amount of variety embodied in the system, the amount of external influence that weights and shapes the overall property and direction of the system, the type of resources that the system consumes, the type of constraints that the system is operating under and the number of levels of sub-systems that work together to build out the final system. Thus, systems can be benign as in the system is relatively more predictable whereas a radical system is a material departure of a system from expectation. If the parts that constitute a system is independent of its workings from other parts and can be boxed within boundaries, emergent systems become more predictable. A watch is an example of a system that follows the different mechanical elements in a watch that are geared for reading the time as it ultimate purpose. It is a good example of a complex physical system. However, these systems are very brittle – a failure in one point can cascade into a failure of the entire system. Systems that are more resilient are those where the elements interact and learn from one another. In other words, the behavior of the elements excites other elements – all of which work together to create a dance toward a more stable state. They deploy what is often called the flocking trick and the pheromone trick. Flocking trick is largely the emulation of the particles that are close to each other – very similar to the cellular automata as introduced by Neumann and discussed in the earlier chapter. The Pheromone trick reflects how the elements leave marks that are acted upon as signals by other elements and thus they all work together around these signal trails to behave and thus act as a forcing function to create the systems.

There are systems that have properties of extremely strong emergence. What does Consciousness, Life, and Culture have in common? How do we look at Climate? What about the organic development of cities? These are just some examples of system where determinism is nigh impossible. We might be able to tunnel through the various and diverse elements that embody the system, but it would be difficult to coherently and tangibly draw all set of relationships, signals, effectors and detectors, etc. to grapple with a complete understanding of the system. Wrestling a strong emergent system would be a task that might even be outside the purview of the highest level of computational power available. And yet, these systems exist, and they emerge and evolve. Yet we try to plan for these systems or plan to direct policies to influence the system, not fully knowing the impact. This is also where the unintended consequences of our action might take free rein.
Complex Physical and Adaptive Systems
There are two models in complexity. Complex Physical Systems and Complex Adaptive Systems! For us to grasp the patterns that are evolving, and much of it seemingly out of our control – it is important to understand both these models. One could argue that these models are mutually exclusive. While the existing body of literature might be inclined toward supporting that argument, we also find some degree of overlap that makes our understanding of complexity unstable. And instability is not to be construed as a bad thing! We might operate in a deterministic framework, and often, we might operate in the realms of a gradient understanding of volatility associated with outcomes. Keeping this in mind would be helpful as we deep dive into the two models. What we hope is that our understanding of these models would raise questions and establish mental frameworks for intentional choices that we are led to make by the system or make to influence the evolution of the system.
Complex Physical Systems (CPS)
Complex Physical Systems are bounded by certain laws. If there are initial conditions or elements in the system, there is a degree of predictability and determinism associated with the behavior of the elements governing the overarching laws of the system. Despite the tautological nature of the term (Complexity Physical System) which suggests a physical boundary, the late 1900’s surfaced some nuances to this model. In other words, if there is a slight and an arbitrary variation in the initial conditions, the outcome could be significantly different from expectations. The assumption of determinism is put to the sword. The notion that behaviors will follow established trajectories if rules are established and the laws are defined have been put to test. These discoveries by introspection offers an insight into the developmental block of complex physical systems and how a better understanding of it will enable us to acknowledge such systems when we see it and thereafter allow us to establish certain toll-gates and actions to navigate, to the extent possible, to narrow the region of uncertainty around outcomes.

The universe is designed as a complex physical system. Just imagine! Let this sink in a bit. A complex physical system might be regarded relatively simpler than a complex adaptive system. And with that in mind, once again …the universe is a complex physical system. We are awed by the vastness and scale of the universe, we regard the skies with an illustrious reverence and we wonder and ruminate on what lies beyond the frontiers of a universe, if anything. Really, there is nothing bigger than the universe in the physical realm and yet we regard it as a simple system. A “Simple” Complex Physical System. In fact, the behavior of ants that lead to the sustainability of an ant colony, is significantly more complex: and we mean by orders of magnitude.

Complexity behavior in nature reflects the tendency of large systems with many components to evolve into a poised “critical” state where minor disturbances or arbitrary changes in initial conditions can create a seemingly catastrophic impact on the overall system such that system changes significantly. And that happens not by some invisible hand or some uber design. What is fundamental to understanding complex systems is to understand that complexity is defined as the variability of the system. Depending on our lens, the scale of variability could change and that might lead to different apparatus that might be required to understand the system. Thus, determinism is not the measure: Stephen Jay Gould has argued that it is virtually impossible to predict the future. We have hindsight explanatory powers but not predictable powers. Hence, systems that start from the initial state over time might represent an outcome that is distinguishable in form and content from the original state. We see complex physical systems all around us. Snowflakes, patterns on coastlines, waves crashing on a beach, rain, etc.
Complex Adaptive Systems (CAS)
Complex adaptive systems, on the contrary, are learning systems that evolve. They are composed of elements which are called agents that interact with one another and adapt in response to the interactions.

Markets are a good example of complex adaptive systems at work.
CAS agents have three levels of activity. As described by Johnson in Complexity Theory: A Short Introduction – the three levels of activity are:
- Performance (moment by moment capabilities): This establishes the locus of all behavioral elements that signify the agent at a given point of time and thereafter establishes triggers or responses. For example, if an object is approaching and the response of the agent is to run, that would constitute a performance if-then outcome. Alternatively, it could be signals driven – namely, an ant emits a certain scent when it finds food: other ants will catch on that trail and act, en masse, to follow the trail. Thus, an agent or an actor in an adaptive system has detectors which allows them to capture signals from the environment for internal processing and it also has the effectors that translate the processing to higher order signals that influence other agents to behave in certain ways in the environment. The signal is the scent that creates these interactions and thus the rubric of a complex adaptive system.
- Credit assignment (rating the usefulness of available capabilities): When the agent gathers experience over time, the agent will start to rely heavily on certain rules or heuristics that they have found useful. It is also typical that these rules may not be the best rules, but it could be rules that are a result of first discovery and thus these rules stay. Agents would rank these rules in some sequential order and perhaps in an ordinal ranking to determine what is the best rule to fall back on under certain situations. This is the crux of decision making. However, there are also times when it is difficult to assign a rank to a rule especially if an action is setting or laying the groundwork for a future course of other actions. A spider weaving a web might be regarded as an example of an agent expending energy with the hope that she will get some food. This is a stage setting assignment that agents have to undergo as well. One of the common models used to describe this best is called the bucket-brigade algorithm which essentially states that the strength of the rule depends on the success of the overall system and the agents that constitute it. In other words, all the predecessors and successors need to be aware of only the strengths of the previous and following agent and that is done by some sort of number assignment that becomes stronger from the beginning of the origin of the system to the end of the system. If there is a final valuable end-product, then the pathway of the rules reflect success. Once again, it is conceivable that this might not be the optimal pathway but a satisficing pathway to result in a better system.
- Rule discovery (generating new capabilities): Performance and credit assignment in agent behavior suggest that the agents are governed by a certain bias. If the agents have been successful following certain rules, they would be inclined toward following those rules all the time. As noted, rules might not be optimal but satisficing. Is improvement a matter of just incremental changes to the process? We do see major leaps in improvement … so how and why does this happen? In other words, someone in the process have decided to take a different rule despite their experiences. It could have been an accident or very intentional.
One of the theories that have been presented is that of building blocks. CAS innovation is a result of reconfiguring the various components in new ways. One quips that if energy is neither created, nor destroyed …then everything that exists today or will exist tomorrow is nothing but a reconfiguration of energy in new ways. All of tomorrow resides in today … just patiently waiting to be discovered. Agents create hypotheses and experiment in the petri dish by reconfiguring their experiences and other agent’s experiences to formulate hypotheses and the runway for discovery. In other words, there is a collaboration element that comes into play where the interaction of the various agents and their assignment as a group to a rule also sets the stepping stone for potential leaps in innovation.
Another key characteristic of CAS is that the elements are constituted in a hierarchical order. Combinations of agents at a lower level result in a set of agents higher up and so on and so forth. Thus, agents in higher hierarchical orders take on some of the properties of the lower orders but it also includes the interaction rules that distinguishes the higher order from the lower order.
The Unbearable Lightness of Being
Where the mind is without fear and the head is held high
Where knowledge is free
Where the world has not been broken up into fragments
By narrow domestic walls
Where words come out from the depth of truth
Where tireless striving stretches its arms towards perfection
Where the clear stream of reason has not lost its way
Into the dreary desert sand of dead habit
Where the mind is led forward by thee
Into ever-widening thought and action
Into that heaven of freedom, my Father, let my country awake.
– Rabindranath Tagore

Among the many fundamental debates in philosophy, one of the fundamental debates has been around the concept of free will. The debates have stemmed around two arguments associated with free will.
1) Since future actions are governed by the circumstances of the present and the past, human beings future actions are predetermined on account of the learnings from the past. Hence, the actions that happen are not truly a consequent of free will.
2) The counter-argument is that future actions may not necessarily be determined and governed by the legacy of the present and the past, and hence leaves headroom for the individual to exercise free will.

Now one may wonder what determinism or lack of it has anything to do with the current state of things in an organizational context. How is this relevant? Why are the abstract notions of determinism and free will important enough to be considered in the context of organizational evolution? How does the meaning lend itself to structured institutions like business organizations, if you will, whose sole purpose is to create products and services to meet the market demand.
So we will throw a factual wrinkle in this line of thought. We will introduce now an element of chance. How does chance change the entire dialectic? Simply because chance is an unforeseen and random event that may not be pre-determined; in fact, a chance event may not have a causal trigger. And chance or luck could be meaningful enough to untether an organization and its folks to explore alternative paths. It is how the organization and the people are aligned to take advantage of that random nondeterministic future that could make a huge difference to the long term fate of the organization.
The principle of inductive logic states that what is true for n and n+1 would be true for n+2. The inductive logic creates predictability and hence organizations create pathways to exploit the logical extension of inductive logic. It is the most logical apparatus that exists to advance groups in a stable but robust manner to address the multitude of challenges that that they have to grapple with. After all, the market is governed by animal spirits! But let us think through this very carefully. All competition or collaboration that occurs among groups to address the market demands result in homogenous behavior with general homogeneous outcomes. Simply put, products and services become commoditized. Their variance is not unique and distinctive. However, they could be just be distinctive enough to eke out enough profits in the margins before being absorbed into a bigger whole. At that point, identity is effaced over time. Organizations gravitate to a singularity. Unique value propositions wane over time.

So let us circle back to chance. Chance is our hope to create divergence. Chance is the factoid that cancels out the inductive vector of industrial organization. Chance does not exist … it is not a “waiting for Godot” metaphor around the corner. If it always did, it would have been imputed by the determinists in their inductive world and we would end up with a dystopian homogenous future. Chance happens. And sometimes it has a very short half-life. And if the organization and people are aligned and their mindset is adapted toward embracing and exploiting that fleeting factoid of chance, the consequences could be huge. New models would emerge, new divergent paths would be traduced and society and markets would burst into a garden of colorful ideas in virtual oasis of new markets.

So now to tie this all to free will and to the unbearable lightness of being! It is the existence of chance that creates the opportunity to exercise free will on the part of an individual, but it is the organizations responsibility to allow the individual to unharness themselves from organization inertia. Thus, organizations have to perpetuate an environment wherein employees are afforded some headroom to break away. And I don’t mean break away as in people leaving the organization to do their own gigs; I mean breakaway in thought and action within the boundaries of the organization to be open to element of chance and exploit it. Great organizations do not just encourage the lightness of being … unharnessing the talent but rather – the great organizations are the ones that make the lightness of being unbearable. These individuals are left with nothing but an awareness and openness to chance to create incredible values … far more incredible and awe inspiring and momentous than a more serene state of general business as usual affairs.
MECE Framework, Analysis, Synthesis and Organization Architecture toward Problem-Solving
MECE is a thought tool that has been systematically used in McKinsey. It stands for Mutually Exclusive, Comprehensively Exhaustive. We will go into both these components in detail and then relate this to the dynamics of an organization mindset. The presumption in this note is that the organization mindset has been engraved over time or is being driven by the leadership. We are looking at MECE since it represents a tool used by the most blue chip consulting firm in the world. And while doing that, we will , by the end of the article, arrive at the conclusion that this framework alone will not be the panacea to all investigative methodology to assess a problem – rather, this framework has to reconcile with the active knowledge that most things do not fall in the MECE framework, and thus an additional system framework is needed to amplify our understanding for problem solving and leaving room for chance.
So to apply the MECE technique, first you define the problem that you are solving for. Once you are past the definition phase, well – you are now ready to apply the MECE framework.

MECE is a framework used to organize information which is:
- Mutually exclusive: Information should be grouped into categories so that each category is separate and distinct without any overlap; and
- Collectively exhaustive: All of the categories taken together should deal with all possible options without leaving any gaps.
In other words, once you have defined a problem – you figure out the broad categories that relate to the problem and then brainstorm through ALL of the options associated with the categories. So think of it as a mental construct that you move across a horizontal line with different well defined shades representing categories, and each of those partitions of shades have a vertical construct with all of the options that exhaustively explain those shades. Once you have gone through that exercise, which is no mean feat – you will be then looking at an artifact that addresses the problem. And after you have done that, you individually look at every set of options and its relationship to the distinctive category … and hopefully you are well on your path to coming up with relevant solutions.
Now some may argue that my understanding of MECE is very simplistic. In fact, it may very well be. But I can assure you that it captures the essence of very widely used framework in consulting organizations. And this framework has been imported to large organizations and have cascaded down to different scale organizations ever since.
Here is a link that would give you a deeper understanding of the MECE framework:
http://firmsconsulting.com/2010/09/22/a-complete-mckinsey-style-mece-decision-tree/
Now we are going to dig a little deeper. Allow me to digress and take you down a path less travelled. We will circle back to MECE and organizational leadership in a few moments. One of the memorable quotes that have left a lasting impression is by a great Nobel Prize winning physicist, Richard Feynman.

“I have a friend who’s an artist and has sometimes taken a view which I don’t agree with very well. He’ll hold up a flower and say “look how beautiful it is,” and I’ll agree. Then he says “I as an artist can see how beautiful this is but you as a scientist takes this all apart and it becomes a dull thing,” and I think that he’s kind of nutty. First of all, the beauty that he sees is available to other people and to me too, I believe. Although I may not be quite as refined aesthetically as he is … I can appreciate the beauty of a flower. At the same time, I see much more about the flower than he sees. I could imagine the cells in there, the complicated actions inside, which also have a beauty. I mean it’s not just beauty at this dimension, at one centimeter; there’s also beauty at smaller dimensions, the inner structure, also the processes. The fact that the colors in the flower evolved in order to attract insects to pollinate it is interesting; it means that insects can see the color. It adds a question: does this aesthetic sense also exist in the lower forms? Why is it aesthetic? All kinds of interesting questions which the science knowledge only adds to theexcitement, the mystery and the awe of a flower! It only adds. I don’t understand how it subtracts.”

The above quote by Feynman lays the groundwork to understand two different approaches – namely, the artist approaches the observation of the flower from the synthetic standpoint, whereas Feynman approaches it from an analytic standpoint. Both do not offer views that are antithetical to one another: in fact, you need both to gather a holistic view and arrive at a conclusion – the sum is greater than the parts. Feynman does not address the essence of beauty that the artist puts forth; he looks at the beauty of how the components and its mechanics interact well and how it adds to our understanding of the flower. This is very important because the following dialogue with explore another concept to drive this difference between analysis and synthesis home.
There are two possible ways of gaining knowledge. Either we can proceed from the construction of the flower ( the Feynman method) , and then seek to determine the laws of the mutual interaction of its parts as well as its response to external stimuli; or we can begin with what the flower accomplishes and then attempt to account for this. By the first route we infer effects from given causes, whereas by the second route we seek causes of given effects. We can call the first route synthetic, and the second analytic.
We can easily see how the cause effect relationship is translated into a relationship between the analytic and synthetic foundation.
A system’s internal processes — i.e. the interactions between its parts — are regarded as the cause of what the system, as a unit, performs. What the system performs is thus the effect. From these very relationships we can immediately recognize the requirements for the application of the analytic and synthetic methods.
The synthetic approach — i.e. to infer effects on the basis of given causes — is therefore appropriate when the laws and principles governing a system’s internal processes are known, but when we lack a detailed picture of how the system behaves as a whole.

Another example … we do not have a very good understanding of the long-term dynamics of galactic systems, nor even of our own solar system. This is because we cannot observe these objects for the thousands or even millions of years which would be needed in order to map their overall behavior.
However, we do know something about the principles, which govern these dynamics, i.e. gravitational interaction between the stars and planets respectively. We can therefore apply a synthetic procedure in order to simulate the gross dynamics of these objects. In practice, this is done with the use of computer models which calculate the interaction of system parts over long, simulated time periods.

The analytical approach — drawing conclusions about causes on the basis of effects – is appropriate when a system’s overall behavior is known, but when we do not have clear or certain knowledge about the system’s internal processes or the principles governing these. On the other hand, there are a great many systems for which we neither have a clear and certain conception of how they behave as a whole, nor fully understand the principles at work which cause that behavior. Organizational behavior is one such example since it introduces the fickle spirits of the employees that, at an aggregate create a distinct character in the organization.

Leibniz was among the first to define analysis and synthesis as modern methodological concepts:
“Synthesis … is the process in which we begin from principles and [proceed to] build up theorems and problems … while analysis is the process in which we begin with a given conclusion or proposed problem and seek the principles by which we may demonstrate the conclusion or solve the problem.”
So we have wandered down this path of analysis and synthesis and now we will circle back to MECE and the organization. MECE framework is a prime example of the application of analytics in an organization structure. The underlying hypothesis is that the application of the framework will illuminate and add clarity to understanding the problems that we are solving for. But here is the problem: the approach could lead to paralysis by analysis. If one were to apply this framework, one would lose itself in the weeds whereas it is just as important to view the forest. So organizations have to step back and assess at what point we stop the analysis i.e. we have gathered information and at what point we set our roads to discovering a set of principles that will govern the action to solve a set of problems. It is almost always impossible to gather all information to make the best decision – especially where speed, iteration, distinguishing from the herd quickly, stamping a clear brand etc. are becoming the hallmarks of great organizations.

Applying the synthetic principle in addition to “MECE think” leaves room for error and sub-optimal solutions. But it crowd sources the limitless power of imagination and pattern thinking that will allow the organization to make critical breakthroughs in innovative thinking. It is thus important that both the principles are promulgated by the leadership as coexisting principles that drive an organization forward. It ignites employee engagement, and it imputes the stochastic errors that result when employees may not have all the MECE conditions checked off.
In conclusion, it is important that the organization and its leadership set its architecture upon the traditional pillars of analysis and synthesis – MECE and systems thinking. And this architecture serves to be the springboard for the employees that allows for accidental discoveries, flights of imagination, Nietzschean leaps that transform the organization toward the pathway of innovation, while still grounded upon the bedrock of facts and empirical observations.

Risk Management and Finance
If you are in finance, you are a risk manager. Say what? Risk management! Imagine being the hub in a spoke of functional areas, each of which is embedded with a risk pattern that can vary over time. A sound finance manager would be someone who would be best able to keep pulse, and be able to support the decisions that can contain the risk. Thus, value management becomes critical: Weighing the consequence of a decision against the risk that the decision poses. Not cost management, but value management. And to make value management more concrete, we turn to cash impact or rather – the discounted value of future stream of cash that may or may not be a consequent to a decision. Companies carry risks. If not, a company will not offer any premiums in value to the market. They create competitive advantage – defined as sorting a sustained growth in free cash flow as the key metric that becomes the separator.
John Kay, an eminent strategist, had identified four sources of competitive advantage: Organization Architecture and Culture, Reputation, Innovation and Strategic Assets. All of these are inextricably intertwined, and must be aligned to service value in the company. The business value approach underpins the interrelationships best. And in so doing, scenario planning emerges as a sound machination to manage risks. Understanding the profit impact of a strategy, and the capability/initiative tie-in is one of the most crucial conversations that a good finance manager could encourage in a company. Product, market and internal capabilities become the anchor points in evolving discussions. Scenario planning thus emerges in context of trends and uncertainties: a trend in patterns may open up possibilities, the latter being in the domain of uncertainty.
There are multiple methods one could use in building scenarios and engaging in fruitful risk assessment.
1.Sensitivity Assessment: Evaluate decisions in the context of the strategy’s reliance on the resilience of business conditions. Assess the various conditions in a scenario or mutually exclusive scenarios, assess a probabilistic guesstimate on success factors, and then offer simple solutions. This assessment tends to be heuristic oriented and excellent when one is dealing with few specific decisions to be made. There is an elevated sense of clarity with regard to the business conditions that may present itself. And this is most commonly used, but does not thwart the more realistic conditions where clarity is obfuscated and muddy.
2.Strategy Evaluation: Use scenarios to test a strategy by throwing a layer of interaction complexity. To the extent you can disaggregate the complexity, the evaluation of a strategy is better tenable. But once again, disaggregation has its downsides. We don’t operate in a vacuum. It is the aggregation, and negotiating through this aggregation effectively is where the real value is. You may have heard of the Mckinsey MECE (Mutually Exclusive; Comprehensively Exhaustive) methodology where strategic thrusts are disaggregated and contained within a narrow framework. The idea is that if one does that enough, one has an untrammeled confidence in choosing one initiative over another. That is true again in some cases, but my belief is that the world operates at a more synthetic level than pure analytic. We resort to analytics since it is too damned hard to synthesize, and be able to agree on an optimal solution. I am not creaming analytics; I am only suggesting that there is some possibility that a false hypothesis is accepted and a true one rejected. Thus analytics is an important tool, but must be weighed along with the synthetic tradition.
3.Synthetic Development: By far the most interesting and perhaps the most controversial with glint of academic and theoretical monstrosities included – this represents developing and broadcasting all scenarios equally weighed, and grouping interaction of scenarios. Thus, if introducing a multi-million dollar initiative in untested waters is a decision you have to weigh, one must go through the first two methods, and then review the final outcome against peripheral factors that were not introduced initially. A simple statement or realization like – The competition for Southwest is the Greyhound bus – could significantly alter the expanse of the strategy.
If you think of the new world of finance being nothing more than crunching numbers … stop and think again. Yes …crunching those numbers play a big part, less a cause than an effect of the mental model that you appropriate in this prized profession.
