Category Archives: Complexity

The Finance Playbook for Scaling Complexity Without Chaos
From Controlled Growth to Operational Grace
Somewhere between Series A optimism and Series D pressure sits the very real challenge of scale. Not just growth for its own sake but growth with control, precision, and purpose. A well-run finance function becomes less about keeping the lights on and more about lighting the runway. I have seen it repeatedly. You can double ARR, but if your deal desk, revenue operations, or quote-to-cash processes are even slightly out of step, you are scaling chaos, not a company.
Finance does not scale with spreadsheets and heroics. It scales with clarity. With every dollar, every headcount, and every workflow needing to be justified in terms of scale, simplicity must be the goal. I recall sitting in a boardroom where the CEO proudly announced a doubling of the top line. But it came at the cost of three overlapping CPQ systems, elongated sales cycles, rogue discounting, and a pipeline no one trusted. We did not have a scale problem. We had a complexity problem disguised as growth.
OKRs Are Not Just for Product Teams
When finance is integrated into company OKRs, magic happens. We begin aligning incentives across sales, legal, product, and customer success teams. Suddenly, the sales operations team is not just counting bookings but shaping them. Deal desk isn’t just a speed bump before legal review, but a value architect. Our quote-to-cash process is no longer a ticketing system but a flywheel for margin expansion.
At a Series B company, their shift began by tying financial metrics directly to the revenue team’s OKRs. Quota retirement was not enough. They measured the booked gross margin. Customer acquisition cost. Implementation of velocity. The sales team was initially skeptical but soon began asking more insightful questions. Deals that initially appeared promising were flagged early. Others that seemed too complicated were simplified before they even reached RevOps. Revenue is often seen as art. But finance gives it rhythm.
Scaling Complexity Despite the Chaos
The truth is that chaos is not the enemy of scale. Chaos is the cost of momentum. Every startup that is truly growing at a pace inevitably creates complexity. Systems become tangled. Roles blur. Approvals drift. That is not failure. That is physics. What separates successful companies is not the absence of chaos but their ability to organize it.
I often compare this to managing a growing city. You do not stop new buildings from going up just because traffic worsens. You introduce traffic lights, zoning laws, and transit systems that support the growth. In finance, that means being ready to evolve processes as soon as growth introduces friction. It means designing modular systems where complexity is absorbed rather than resisted. You do not simplify the growth. You streamline the experience of growing. Read Scale by Geoffrey West. Much of my interest in complexity theory and architecture for scale comes from it. Also, look out for my book, which will be published in February 2026: Complexity and Scale: Managing Order from Chaos. This book aligns literature in complexity theory with the microeconomics of scaling vectors and enterprise architecture.
At a late-stage Series C company, the sales motion had shifted from land-and-expand to enterprise deals with multi-year terms and custom payment structures. The CPQ tool was unable to keep up. Rather than immediately overhauling the tool, they developed middleware logic that routed high-complexity deals through a streamlined approval process, while allowing low-risk deals to proceed unimpeded. The system scaled without slowing. Complexity still existed, but it no longer dictated pace.
Cash Discipline: The Ultimate Growth KPI
Cash is not just oxygen. It is alignment. When finance speaks early and often about burn efficiency, marginal unit economics, and working capital velocity, we move from gatekeepers to enablers. I often remind founders that the cost of sales is not just the commission plan. It’s in the way deals are structured. It’s in how fast a contract can be approved. It’s in how many hands a quote needs to pass through.
At one Series A professional services firm, they introduced a “Deal ROI Calculator” at the deal desk. It calculated not just price and term but implementation effort, support burden, and payback period. The result was staggering. Win rates remained stable, but average deal profitability increased by 17 percent. Sales teams began choosing deals differently. Finance was not saying no. It was saying, “Say yes, but smarter.”
Velocity is a Decision, Not a Circumstance
The best-run companies are not faster because they have fewer meetings. They are faster because decisions are closer to the data. Finance’s job is to put insight into the hands of those making the call. The goal is not to make perfect decisions. It is to make the best decision possible with the available data and revisit it quickly.
In one post-Series A firm, we embedded finance analysts inside revenue operations. It blurred the traditional lines but sped up decision-making. Discount approvals have been reduced from 48 hours to 12-24 hours. Pricing strategies became iterative. A finance analyst co-piloted the forecast and flagged gaps weeks earlier than our CRM did. It wasn’t about more control. It was about more confidence.
When Process Feels Like Progress
It is tempting to think that structure slows things down. However, the right QTC design can unlock margin, trust, and speed simultaneously. Imagine a deal desk that empowers sales to configure deals within prudent guardrails. Or a contract management workflow that automatically flags legal risks. These are not dreams. These are the functions we have implemented.
The companies that scale well are not perfect. But their finance teams understand that complexity compounds quietly. And so, we design our systems not to prevent chaos but to make good decisions routine. We don’t wait for the fire drill. We design out the fire.
Make Your Revenue Operations Your Secret Weapon
If your finance team still views sales operations as a reporting function, you are underutilizing a strategic lever. Revenue operations, when empowered, can close the gap between bookings and billings. They can forecast with precision. They can flag incentive misalignment. One of the best RevOps leaders I worked with used to say, “I don’t run reports. I run clarity.” That clarity was worth more than any point solution we bought.
In scaling environments, automation is not optional. But automation alone does not save a broken process. Finance must own the blueprint. Every system, from CRM to CPQ to ERP, must speak the same language. Data fragmentation is not just annoying. It is value-destructive.
What Should You Do Now?
Ask yourself: Does finance have visibility into every step of the revenue funnel? Do our QTC processes support strategic flexibility? Is our deal desk a source of friction or a source of enablement? Can our sales comp plan be audited and justified in a board meeting without flinching?
These are not theoretical. They are the difference between Series C confusion and Series D confidence.
Let’s Make This Personal
I have seen incredible operators get buried under process debt because they mistook motion for progress. I have seen lean finance teams punch above their weight because they anchored their operating model in OKRs, cash efficiency, and rapid decision cycles. I have also seen the opposite. A sales ops function sitting in the corner. A deal desk no one trusts. A QTC process where no one knows who owns what.
These are fixable. But only if finance decides to lead. Not just report.
So here is my invitation. If you are a CFO, a CRO, a GC, or a CEO reading this, take one day this quarter to walk your revenue path from lead to cash. Sit with the people who feel the friction. Map the handoffs. And then ask, is this how we scale with control? Do you have the right processes in place? Do you have the technology to activate the process and minimize the friction?

Beyond the Buzz: The Real Economics Behind SaaS, AI, and Everything in Between
Introduction
Throughout my career, I have had the privilege of working in and leading finance teams across several SaaS companies. The SaaS model is familiar territory to me: its economics are well understood, its metrics are measurable, and its value creation pathways have been tested over time. Erich Mersch’s book on SaaS Hacks is my Bible. In contrast, my exposure to pure AI companies has been more limited. I have directly supported two AI-driven businesses, and much of my perspective comes from observation, benchmarking, and research. This combination of direct experience and external study has hopefully shaped a balanced view: one grounded in practicality yet open to the new dynamics emerging in the AI era.

Across both models, one principle remains constant: a business is only as strong as its unit economics. When leaders understand the economics of their business, they gain the ability to map them to daily operations, and from there, to the financial model. The linkage from unit economics to operations to financial statements is what turns financial insight into strategic control. It ensures that decisions on pricing, product design, and investment are all anchored in how value is truly created and captured.
Today, CFOs and CEOs must not only manage their profit and loss (P&L) statement but also understand the anatomy of revenue, cost, and cash flow at the micro level. SaaS, AI, and hybrid SaaS-AI models each have unique economic signatures. SaaS rewards scalability and predictability. AI introduces variability and infrastructure intensity. Hybrids offer both opportunity and complexity. This article examines the financial structure, gross margin profile, and investor lens of each model to help finance leaders not only measure performance but also interpret it by turning data into judgment and judgment into a better strategy.
Part I: SaaS Companies — Economics, Margins, and Investor Lens
The heart of any SaaS business is its recurring revenue model. Unlike traditional software, where revenue is recognized upfront, SaaS companies earn revenue over time as customers subscribe to a service. This shift from ownership to access creates predictable revenue streams but also introduces delayed payback cycles and continuous obligations to deliver value. Understanding the unit economics behind this model is essential for CFOs and CEOs, as it enables them to see beyond top-line growth and assess whether each customer, contract, or cohort truly creates long-term value.
A strong SaaS company operates like a flywheel. Customer acquisition drives recurring revenue, which funds continued innovation and improved service, in turn driving more customer retention and referrals. But a flywheel is only as strong as its components. The economics of SaaS can be boiled down to a handful of measurable levers: gross margin, customer acquisition cost, retention rate, lifetime value, and cash efficiency. Each one tells a story about how the company converts growth into profit.
The SaaS Revenue Engine
At its simplest, a SaaS company makes money by providing access to its platform on a subscription basis. The standard measure of health is Annual Recurring Revenue (ARR). ARR represents the contracted annualized value of active subscriptions. It is the lifeblood metric of the business. When ARR grows steadily with low churn, the company can project future cash flows with confidence.
Revenue recognition in SaaS is governed by time. Even if a customer pays upfront, the revenue is recognized over the duration of the contract. This creates timing differences between bookings, billings, and revenue. CFOs must track all three to understand both liquidity and profitability. Bookings signal demand, billings signal cash inflow, and revenue reflects the value earned.
One of the most significant advantages of SaaS is predictability. High renewal rates lead to stable revenues. Upsells and cross-sells increase customer lifetime value. However, predictability can also mask underlying inefficiencies. A SaaS business can grow fast and still destroy value if each new customer costs more to acquire than they bring in lifetime revenue. This is where unit economics comes into play.

Core Unit Metrics in SaaS
The three central metrics every CFO and CEO must know are:
- Customer Acquisition Cost (CAC): The total sales and marketing expenses needed to acquire one new customer.
- Lifetime Value (LTV): The total revenue a customer is expected to generate over their relationship with the company.
- Payback Period: The time it takes for gross profit from a customer to recover CAC.
A healthy SaaS business typically maintains an LTV-to-CAC ratio of at least 3:1. This means that for every dollar spent acquiring a customer, the company earns three dollars in lifetime value. Payback periods under twelve months are typically considered strong, especially in mid-market or enterprise SaaS. Long payback periods signal cash inefficiency and high-risk during downturns.
Retention is equally essential. The stickier the product, the lower the churn, and the more predictable the revenue. Net revenue retention (NRR) is a powerful metric because it combines churn and expansion. A business with 120 percent NRR is growing revenue even without adding new customers, which investors love to see.
Gross Margin Dynamics
Gross margin is the backbone of SaaS profitability. It measures how much of each revenue dollar remains after deducting direct costs, such as hosting, support, and third-party software fees. Well-run SaaS companies typically achieve gross margins of between 75% and 85%. This reflects the fact that software is highly scalable. Once built, it can be replicated at almost no additional cost. They use the margins to fund their GTM strategy. They have room until they don’t.
However, gross margin is not guaranteed. In practice, it can erode for several reasons. First, rising cloud infrastructure costs can quietly eat into margins if not carefully managed. Companies that rely heavily on AWS, Azure, or Google Cloud need cost optimization strategies, including reserved instances and workload tuning. Second, customer support and success functions, while essential, can become heavy if processes are not automated. Third, complex integrations or data-heavy products can increase variable costs per customer.
Freemium and low-entry pricing models can also dilute margins if too many users remain on free tiers or lower-paying plans. The CFO’s job is to ensure that pricing reflects the actual value delivered and that the cost-to-serve remains aligned with revenue per user. A mature SaaS company tracks unit margins by customer segment to identify where profitability thrives or erodes.
Operating Leverage and the Rule of 40
The power of SaaS lies in its potential for operating leverage. Fixed costs, such as R&D, engineering, and sales infrastructure, remain relatively constant as revenue scales. As a result, incremental revenue flows disproportionately to the bottom line once the business passes break-even. This makes SaaS an attractive model once scale is achieved, although reaching that scale can take a considerable amount of time.
The Rule of 40 is a shorthand metric many investors use to gauge the balance between growth and profitability. It states that a SaaS company’s revenue growth rate, plus its EBITDA margin, should equal or exceed 40 percent. A company growing 30 percent annually with a 15 percent EBITDA margin scores 45, which is considered healthy. A company growing at 60 percent but losing 30 percent EBITDA would score 30, suggesting inefficiency. This rule forces management to strike a balance between ambition and discipline. This 40% rule was based on empirical analysis, and every Jack and Jill swears by it. I am not sure that we can have this Rule and apply it blindly. I am not generally in favor of these broad rules. That is a lot of fodder for a different conversation.
Cash Flow and Efficiency
Cash flow timing is another defining feature of SaaS. Many customers prepay annually, creating favorable working capital dynamics. This gives SaaS companies negative net working capital, which can help fund growth. However, high upfront CAC and long payback periods can strain cash reserves. CFOs must ensure growth is financed efficiently and that burn multiples remain sustainable. Burn-multiple measures the cash burn relative to net new ARR added. A burn rate of multiple below 1 is excellent; it means the company spends one dollar to generate one dollar of recurring revenue. Ratios above 2 suggest inefficiency.
As markets have tightened, investors have shifted focus from pure growth to efficient growth. Cash is no longer cheap, and dilution from equity raises is costly. I attended a networking event in San Jose about a month ago, and one of the finance leaders said, “We are in the middle of a nuclear winter.” I thought that summarized the current state of the funding market. Therefore, SaaS CFOs must guide companies toward self-funding growth, improving gross margins, and shortening CAC payback cycles.
Valuation and Investor Perspective
Investors view SaaS companies through the lens of predictability, scalability, and margin potential. Historically, during low-interest-rate periods, high-growth SaaS companies traded at 10 to 15 times ARR. In the current normalized environment, top performers trade between 5 and 8 times ARR, with discounts for slower growth or lower margins.
The key drivers of valuation include:
- Growth Rate: Faster ARR growth leads to higher multiples, provided it is efficient.
- Gross Margin: High margins indicate scalability and control over cost structure.
- Retention and Expansion: Strong NRR signals durable revenue and pricing power.
- Profitability Trajectory: Investors reward companies that balance growth with clear paths to cash flow breakeven.
Investors now differentiate between the quality of growth and the quantity of growth. Revenue driven by deep discounts or heavy incentives is less valuable than revenue driven by customer adoption and satisfaction. CFOs must clearly communicate cohort performance, renewal trends, and contribution margins to demonstrate that growth is sustainable and durable.
Emerging Challenges in SaaS Economics
While SaaS remains a powerful model, new challenges have emerged. Cloud infrastructure costs are rising, putting pressure on gross margins. AI features are becoming table stakes, but they introduce new variable costs tied to compute. Customer expectations are also shifting toward usage-based pricing, which can lead to reduced predictability in revenue recognition.
To navigate these shifts, CFOs must evolve their financial reporting and pricing strategies. Gross margin analysis must now include compute efficiency metrics. Sales compensation plans must reflect profitability, not just bookings. Pricing teams must test elasticity to ensure ARPU growth outpaces cost increases.
SaaS CFOs must also deepen their understanding of cohort economics. Not all customers are equal. Some segments deliver faster payback and higher retention, while others create drag. Segmented reporting enables management to allocate capital wisely and avoid pursuing unprofitable markets.
The Path Forward
The essence of SaaS unit economics is discipline. Growth only creates value when each unit of growth strengthens the financial foundation. This requires continuous monitoring of margins, CAC, retention, and payback. It also requires cross-functional collaboration between finance, product, and operations. Finance must not only report outcomes but also shape strategy, ensuring that pricing aligns with value and product decisions reflect cost realities.
For CEOs, understanding these dynamics is vital to setting priorities. For CFOs, the task is to build a transparent model that links operational levers to financial outcomes. Investors reward companies that can tell a clear story with data: a path from top-line growth to sustainable free cash flow.
Ultimately, SaaS remains one of the most attractive business models when executed effectively. The combination of recurring revenue, high margins, and operating leverage creates long-term compounding value. But it rewards precision. The CFO who masters unit economics can turn growth into wealth, while the one who ignores it may find that scale without discipline is simply a faster road to inefficiency. The king is not dead: Long live the king.

Part II: Pure AI Companies — Economics, Margins, and Investor Lens
Artificial intelligence companies represent a fundamentally different business model from traditional SaaS. Where SaaS companies monetize access to pre-built software, AI companies monetize intelligence: the ability of models to learn, predict, and generate. This shift changes everything about unit economics. The cost per unit of value is no longer near zero. It is tied to the underlying cost of computation, data processing, and model maintenance. As a result, CFOs and CEOs leading AI-first companies must rethink what scale, margin, and profitability truly mean.
While SaaS scales easily once software is built, AI scales conditionally. Each customer interaction may trigger new inference requests, consume GPU time, and incur variable costs. Every additional unit of demand brings incremental expenses. The CFO’s challenge is to translate these technical realities into financial discipline, which involves building an organization that can sustain growth without being constrained by its own cost structure.
Understanding the AI Business Model
AI-native companies generate revenue by providing intelligence as a service. Their offerings typically fall into three categories:
- Platform APIs: Selling access to models that perform tasks such as image recognition, text generation, or speech processing.
- Enterprise Solutions: Custom model deployments tailored for specific industries like healthcare, finance, or retail.
- Consumer Applications: AI-powered tools like copilots, assistants, or creative generators.
Each model has unique economics. API-based businesses often employ usage-based pricing, resembling utilities. Enterprise AI firms resemble consulting hybrids, blending software with services. Consumer AI apps focus on scale, requiring low-cost inference to remain profitable.
Unlike SaaS subscriptions, AI revenue is often usage-driven. This makes it more elastic but less predictable. When customers consume more tokens, queries, or inferences, revenue rises but so do costs. This tight coupling between revenue and cost means margins depend heavily on technical efficiency. CFOs must treat cost-per-inference as a central KPI, just as SaaS leaders track gross margin percentage.
Gross Margins and Cost Structures
For pure AI companies, the gross margin reflects the efficiency of their infrastructure. In the early stages, margins often range between 40% and 60%. With optimization, some mature players approach 70 percent or higher. However, achieving SaaS-like margins requires significant investment in optimization techniques, such as model compression, caching, and hardware acceleration.
The key cost components include:
- Compute: GPU and cloud infrastructure costs are the most significant variable expenses. Each inference consumes compute cycles, and large models require expensive hardware.
- Data: Training and fine-tuning models involve significant data acquisition, labeling, and storage costs.
- Serving Infrastructure: Orchestration, latency management, and load balancing add further expenses.
- Personnel: Machine learning engineers, data scientists, and research teams represent high fixed costs.
Unlike SaaS, where the marginal cost per user declines toward zero, AI marginal costs can remain flat or even rise with increasing complexity. The more sophisticated the model, the more expensive it is to serve each request. CFOs must therefore design pricing strategies that match the cost-to-serve, ensuring unit economics remain positive.
To track progress, leading AI finance teams adopt new metrics such as cost per 1,000 tokens, cost per inference, or cost per output. These become the foundation for gross margin improvement programs. Without these metrics, management cannot distinguish between profitable and loss-making usage.
Capital Intensity and Model Training
A defining feature of AI economics is capital intensity. Training large models can cost tens or even hundreds of millions of dollars. These are not operating expenses in the traditional sense; they are long-term investments. The question for CFOs is how to treat them. Should they be expensed, like research and development, or capitalized, like long-lived assets? The answer depends on accounting standards and the potential for model reuse.
If a model will serve as a foundation for multiple products or customers over several years, partial capitalization may be a defensible approach. However, accounting conservatism often favors expensing, which depresses near-term profits. Regardless of treatment, management must view training costs as sunk investments that must earn a return through widespread reuse.
Due to these high upfront costs, AI firms must carefully plan their capital allocation. Not every model warrants training from scratch. Fine-tuning open-source or pre-trained models may achieve similar outcomes at a fraction of the cost. The CFO’s role is to evaluate return on invested capital in R&D and ensure technical ambition aligns with commercial opportunity.
Cash Flow Dynamics
Cash flow management in AI businesses is a significant challenge. Revenue often scales more slowly than costs in early phases. Infrastructure bills accrue monthly, while customers may still be in pilot stages. This results in negative contribution margins and high burn rates. Without discipline, rapid scaling can amplify losses.
The path to positive unit economics comes from optimization. Model compression, quantization, and batching can lower the cost per inference. Strategic use of lower-cost hardware, such as CPUs for lighter tasks, can also be beneficial. Some firms pursue vertical integration, building proprietary chips or partnering for preferential GPU pricing. Others use caching and heuristic layers to reduce the number of repeated inference calls.
Cash efficiency improves as AI companies move from experimentation to productization. Once a model stabilizes and workload patterns become predictable, cost forecasting and margin planning become more reliable. CFOs must carefully time their fundraising and growth, ensuring the company does not overbuild infrastructure before demand materializes.
Pricing Strategies
AI pricing remains an evolving art. Standard models include pay-per-use, subscription tiers with usage caps, or hybrid pricing that blends base access fees with variable usage charges. The proper structure depends on the predictability of usage, customer willingness to pay, and cost volatility.
Usage-based pricing aligns revenue with cost but increases forecasting uncertainty. Subscription pricing provides stability but can lead to margin compression if usage spikes. CFOs often employ blended approaches, utilizing base subscriptions that cover average usage, with additional fees for exceeding demand. This provides a buffer against runaway costs while maintaining customer flexibility.
Transparent pricing is crucial. Customers need clarity about what drives cost. Complexity breeds disputes and churn. Finance leaders should collaborate with product and sales teams to develop pricing models that are straightforward, equitable, and profitable. Scenario modeling helps anticipate edge cases where heavy usage erodes margins.
Valuation and Investor Perspective
Investors evaluate AI companies through a different lens than SaaS. Because AI is still an emerging field, investors look beyond current profitability and focus on technical moats, data advantages, and the scalability of cost curves. A strong AI company demonstrates three things:
- Proprietary Model or Data: Access to unique data sets or model architectures that competitors cannot easily replicate.
- Cost Curve Mastery: A clear path to reducing cost per inference as scale grows.
- Market Pull: Evidence of real-world demand and willingness to pay for intelligence-driven outcomes.
Valuations often blend software multiples with hardware-like considerations. Early AI firms may be valued at 6 to 10 times forward revenue if they show strong growth and clear cost reduction plans. Companies perceived as purely research-driven, without commercial traction, face steeper discounts. Investors are increasingly skeptical of hype and now seek proof of sustainable margins.
In diligence, investors focus on gross margin trajectory, data defensibility, and customer concentration. They ask questions like: How fast is the cost per inference declining? What portion of revenue comes from repeat customers? How dependent is the business on third-party models or infrastructure? The CFO’s job is to prepare crisp, data-backed answers.
Measuring Efficiency and Scale
AI CFOs must introduce new forms of cost accounting. Traditional SaaS dashboards that focus solely on ARR and churn are insufficient. AI demands metrics that link compute usage to financial outcomes. Examples include:
- Compute Utilization Rate: Percentage of GPU capacity effectively used.
- Model Reuse Ratio: Number of applications or customers served by a single trained model.
- Cost per Output Unit: Expense per generated item, prediction, or token.
By tying these technical metrics to revenue and gross margin, CFOs can guide engineering priorities. Finance becomes a strategic partner in improving efficiency, not just reporting cost overruns. In a later article, we will discuss complexity and Scale. I am writing a book on that subject, and this is highly relevant to how AI-based businesses are evolving. It is expected to be released by late February next year and will be available on Kindle as an e-book.
Risk Management and Uncertainty
AI companies face unique risks. Dependence on external cloud providers introduces pricing and supply risks. Regulatory scrutiny over data usage can limit access to models or increase compliance costs. Rapid technological shifts may render models obsolete before their amortization is complete. CFOs must build contingency plans, diversify infrastructure partners, and maintain agile capital allocation processes.
Scenario planning is essential. CFOs should model high, medium, and low usage cases with corresponding cost structures. Sensitivity analysis on cloud pricing, GPU availability, and demand elasticity helps avoid surprises. Resilience matters as much as growth.
The Path Forward
For AI companies, the journey to sustainable economics is one of learning curves. Every technical improvement that reduces the cost per unit enhances the margin. Every dataset that improves model accuracy also enhances customer retention. Over time, these compounding efficiencies create leverage like SaaS, but the path is steeper.
CFOs must view AI as a cost-compression opportunity. The winners will not simply have the best models but the most efficient ones. Investors will increasingly value businesses that show declining cost curves, strong data moats, and precise product-market fit.
For CEOs, the message is focus. Building every model from scratch or chasing every vertical can drain capital. The best AI firms choose their battles wisely, investing deeply in one or two defensible areas. Finance leaders play a crucial role in guiding these choices with evidence, rather than emotion.
In summary, pure AI companies operate in a world where scale is earned, not assumed. The economics are challenging but not insurmountable. With disciplined pricing, rigorous cost tracking, and clear communication to investors, AI businesses can evolve from capital-intensive experiments into enduring, high-margin enterprises. The key is turning intelligence into economics and tackling it one inference at a time.
Part III: SaaS + AI Hybrid Models: Economics and Investor Lens
In today’s market, most SaaS companies are no longer purely software providers. They are becoming intelligence platforms, integrating artificial intelligence into their products to enhance customer value. These hybrid models combine the predictability of SaaS with the innovation of AI. They hold great promises, but they also introduce new complexities in economics, margin structure, and investor expectations. For CFOs and CEOs, the challenge is not just understanding how these elements coexist but managing them in harmony to deliver profitable growth.
The hybrid SaaS-AI model is not simply the sum of its parts. It requires balancing two different economic engines: one that thrives on recurring, high-margin revenue and another that incurs variable costs linked to compute usage. The key to success lies in recognizing where AI enhances value and where it risks eroding profitability. Leaders who can measure, isolate, and manage these dynamics can unlock superior economics and investor confidence.
The Nature of Hybrid SaaS-AI Businesses
A hybrid SaaS-AI company starts with a core subscription-based platform. Customers pay recurring fees for access, support, and updates. Additionally, the company leverages AI-powered capabilities to enhance automation, personalization, analytics, and decision-making. These features can be embedded into existing workflows or offered as add-ons, sometimes billed based on usage.
Examples include CRMs with AI-assisted forecasting, HR platforms with intelligent candidate screening, or project tools with predictive insights. In each case, AI transforms user experience and perceived value, but it also introduces incremental cost per transaction. Every inference call, data model query, or real-time prediction consumes compute power and storage.
This hybridization reshapes the traditional SaaS equation. Revenue predictability remains strong due to base subscriptions, but gross margins become more variable. CFOs must now consider blended margins and segment economics. The task is to ensure that AI features expand total lifetime value faster than they inflate cost-to-serve.
Dual Revenue Streams and Pricing Design
Hybrid SaaS-AI companies often operate with two complementary revenue streams:
- Subscription Revenue: Fixed or tiered recurring revenue, predictable and contract-based.
- Usage-Based Revenue: Variable income tied to AI consumption, such as per query, token, or transaction.
This dual model offers flexibility. Subscriptions provide stability, while usage-based revenue captures upside from heavy engagement. However, it also complicates forecasting. CFOs must model revenue variance under various usage scenarios and clearly communicate these assumptions to the Board and investors.
Pricing design becomes a strategic lever. Some firms include AI features in premium tiers to encourage upgrades. Others use consumption pricing, passing compute costs directly to customers. The right approach depends on customer expectations, cost structure, and product positioning. For enterprise markets, predictable pricing is often a preferred option. For developer- or API-driven products, usage-based pricing aligns better with the delivery of value.
The most effective hybrid models structure pricing so that incremental revenue per usage exceeds incremental cost per usage. This ensures positive unit economics across both streams. Finance teams should run sensitivity analyses to test break-even points and adjust thresholds as compute expenses fluctuate.
Gross Margin Bifurcation
Gross margin in hybrid SaaS-AI companies must be analyzed in two layers:
- SaaS Core Margin: Typically, 75 to 85 percent is driven by software delivery, hosting, and support.
- AI Layer Margin: Often 40 to 60 percent, and it depends on compute efficiency and pricing.
When blended, the total margin may initially decline, especially if AI usage grows faster than subscription base revenue. The risk is that rising compute costs erode profitability before pricing can catch up. To manage this, CFOs should report segmented gross margins to the Board. This transparency helps avoid confusion when consolidated margins fluctuate.
The goal is not to immediately maximize blended margins, but to demonstrate a credible path toward margin expansion through optimization. Over time, as AI models become more efficient and the cost per inference declines, blended margins can recover. Finance teams should measure and communicate progress in terms of margin improvement per usage unit, not just overall percentages.
Impact on Customer Economics
AI features can materially improve customer economics. They increase stickiness, reduce churn, and create opportunities for upsell. A customer who utilizes AI-driven insights or automation tools is more likely to renew, as the platform becomes an integral part of their workflow. This improved retention directly translates into a higher lifetime value.
In some cases, AI features can also justify higher pricing or premium tiers. The key is measurable value. Customers pay more when they see clear ROI: for example, faster decision-making, labor savings, or improved accuracy. CFOs should work with product and customer success teams to quantify these outcomes and use them in renewal and pricing discussions.
The critical financial question is whether AI-enhanced LTV grows faster than CAC and variable cost. If so, AI drives profitable growth. If not, it becomes an expensive feature rather than a revenue engine. Regular cohort analysis helps ensure that AI adoption is correlated with improved unit economics.
Operating Leverage and Efficiency
Hybrid SaaS-AI companies must rethink operating leverage. Traditional SaaS gains leverage by spreading fixed costs over recurring revenue. In contrast, AI introduces variable costs tied to usage. This weakens the traditional leverage model. To restore it, finance leaders must focus on efficiency levers within AI operations.
Techniques such as caching, batching, and model optimization can reduce compute costs per request. Partnering with cloud providers for reserved capacity or leveraging model compression can further improve cost efficiency. The finance team’s role is to quantify these savings and ensure engineering priorities align with economic goals.
Another form of leverage comes from data reuse. The more a single model or dataset serves multiple customers or use cases, the higher the effective ROI on data and training investment. CFOs should track data utilization ratios and model reuse metrics as part of their financial dashboards.
Cash Flow and Capital Planning
Cash flow in hybrid businesses depends on the balance between stable subscription inflows and variable infrastructure outflows. CFOs must forecast not only revenue but also compute consumption. During early rollout, AI usage can spike unpredictably, leading to cost surges. Scenario planning is essential. Building buffers into budgets prevents margin shocks.
Capital allocation should prioritize scalability. Investments in AI infrastructure should follow demonstrated demand, not speculative projections. Over-provisioning GPU capacity can result in unnecessary cash expenditures. Many firms start with cloud credits or pay-as-you-go models before committing to long-term leases or hardware purchases. The objective is to match the cost ramp with revenue realization.
As with SaaS, negative working capital from annual prepayments can be used to fund expansion. However, CFOs should reserve portions of this cash for compute variability and cost optimization initiatives.
Investor Perspective
Investors view hybrid SaaS-AI models with both enthusiasm and scrutiny. They appreciate the potential for differentiation and pricing power, but expect clear evidence that AI integration enhances, rather than dilutes, economics. The investment thesis often centers on three questions:
- Does AI materially increase customer lifetime value?
- Can the company sustain or improve gross margins as AI usage scales?
- Is there a clear path to efficient growth under the Rule of 40?
Companies that answer yes to all three earn premium valuations. Investors will typically apply core SaaS multiples (5 to 8 times Annual Recurring Revenue, or ARR) with modest uplifts if AI features drive measurable revenue growth. However, if AI costs are poorly controlled or margins decline, valuations compress quickly.
To maintain investor confidence, CFOs must provide transparency. This includes segmented reporting, sensitivity scenarios, and clear explanations of cost drivers. Investors want to see not just innovation, but financial stewardship.
Strategic Positioning
The strategic role of AI within a SaaS company determines how investors perceive it. There are three broad positioning models:
- AI as a Feature: Enhances existing workflows but is not core to monetization. Example: an email scheduling tool with AI suggestions.
- AI as a Co-Pilot: Drives user productivity and becomes central to customer experience. Example: CRM with AI-generated insights.
- AI as a Platform: Powers entire ecosystems and opens new revenue lines. Example: a developer platform offering custom AI models.
Each model carries different costs and pricing implications. CFOs should ensure that the company’s financial model aligns with its strategic posture. A feature-based AI approach should be margin-accretive. A platform-based approach may accept lower margins initially in exchange for future ecosystem revenue.
Risk Management and Governance
Hybrid models also introduce new risks. Data privacy, model bias, and regulatory compliance can create unexpected liabilities. CFOs must ensure robust governance frameworks are in place. Insurance, audit, and legal teams should work closely together to manage exposure effectively. Transparency in AI decision-making builds customer trust and reduces reputational risk.
Another risk is dependency on third-party models or APIs. Companies that use external large language models face risks related to cost and reliability. CFOs should evaluate the total cost of ownership between building and buying AI capabilities. Diversifying across providers or developing proprietary models can mitigate concentration risk.
The CFO’s Role
In hybrid SaaS-AI organizations, the CFO’s role expands beyond financial reporting. Finance becomes the integrator of technology, strategy, and economics. The CFO must help design pricing strategies, measure the cost-to-serve, and effectively communicate value to investors. This requires fluency in both financial and technical language.
Regular dashboards should include metrics such as blended gross margin, compute cost per user, AI utilization rate, and LTV uplift resulting from AI adoption. This data-driven approach allows management to make informed trade-offs between innovation and profitability.
The CFO also acts as an educator. Boards and investors may not yet be familiar with AI-driven cost structures. Clear, simple explanations build confidence and support strategic decisions.
The Path Forward
The future belongs to companies that combine SaaS predictability with AI intelligence. Those who succeed will treat AI not as a novelty but as an economic engine. They will manage AI costs with the same rigor they apply to headcount or cloud spend. They will design pricing that reflects value creation, not just usage volume. And they will communicate to investors how each new AI feature strengthens the overall financial model.
Hybrid SaaS-AI companies occupy the forefront of modern business economics. They demonstrate that innovation and discipline are not opposites, but they are partners working toward a common objective. For CFOs and CEOs, the path forward is clear: measure what matters, value price, and guide the organization with transparency and foresight. Over time, this combination of creativity and control will separate enduring leaders from experimental wanderers.
Summary
In every business model, clarity around unit economics forms the foundation for sound decision-making. Whether one is building a SaaS company, an AI company, or a hybrid of both, understanding how revenue and costs behave at the most granular level allows management to design operations and financial models that scale intelligently. Without that clarity, growth becomes noise and is not sustainable.
From years of working across SaaS businesses, I have seen firsthand how the model rewards discipline. Predictable recurring revenue, high gross margins, and scalable operating leverage create a compounding effect when managed carefully. The challenge lies in balancing acquisition cost, retention, and cash efficiency, so that each new unit of growth strengthens rather than strains the business.
In AI, the economic story changes. Here, each unit of output incurs tangible costs, such as computation, data, and inference. The path to profitability lies not in volume alone, but in mastering the cost curve. Efficiency, model reuse, and pricing alignment become as critical as sales growth. AI firms must show investors that scaling demand will compress, not inflate, the cost per unit. I have no clue how they intend to do that with GPU demand going through the roof, but in this article, let us assume for giggles that there will be a light at the end of the tunnel, and GPU costs will temper down so it can fuel AI-driven business.
For hybrid SaaS-AI businesses, success depends on integration. AI should deepen customer value, expand lifetime revenue, and justify incremental costs. CFOs and CEOs must manage dual revenue streams, measure blended margins, and communicate transparently with investors about both the promise and the trade-offs of AI adoption.
Ultimately, understanding economics is knowing the truth. I am an economist, and I like to think I am unbiased. It enables leaders to align ambition with reality and design financial models that convey a credible narrative. As the lines between SaaS and AI continue to blur, those who understand the economics underlying innovation will be best equipped to build companies that endure.
The CFO as Chief Option Architect: Embracing Uncertainty
Part I: Embracing the Options Mindset
This first half explores the philosophical and practical foundation of real options thinking, scenario-based planning, and the CFO’s evolving role in navigating complexity. The voice is grounded in experience, built on systems thinking, and infused with a deep respect for the unpredictability of business life.
I learned early that finance, for all its formulas and rigor, rarely rewards control. In one of my earliest roles, I designed a seemingly watertight budget, complete with perfectly reconciled assumptions and cash flow projections. The spreadsheet sang. The market didn’t. A key customer delayed a renewal. A regulatory shift in a foreign jurisdiction quietly unraveled a tax credit. In just six weeks, our pristine model looked obsolete. I still remember staring at the same Excel sheet and realizing that the budget was not a map, but a photograph, already out of date. That moment shaped much of how I came to see my role as a CFO. Not as controller-in-chief, but as architect of adaptive choices.

The world has only become more uncertain since. Revenue operations now sit squarely in the storm path of volatility. Between shifting buying cycles, hybrid GTM models, and global macro noise, what used to be predictable has become probabilistic. Forecasting a quarter now feels less like plotting points on a trendline and more like tracing potential paths through fog. It is in this context that I began adopting and later, championing, the role of the CFO as “Chief Option Architect.” Because when prediction fails, design must take over.
This mindset draws deeply from systems thinking. In complex systems, what matters is not control, but structure. A system that adapts will outperform one that resists. And the best way to structure flexibility, I have found, is through the lens of real options. Borrowed from financial theory, real options describe the value of maintaining flexibility under uncertainty. Instead of forcing an all-in decision today, you make a series of smaller decisions, each one preserving the right, but not the obligation, to act in a future state. This concept, though rooted in asset pricing, holds powerful relevance for how we run companies.
When I began modeling capital deployment for new GTM motions, I stopped thinking in terms of “budget now, or not at all.” Instead, I started building scenario trees. Each branch represented a choice: deploy full headcount at launch or split into a two-phase pilot with a learning checkpoint. Invest in a new product SKU with full marketing spend, or wait for usage threshold signals to pass before escalation. These decision trees capture something that most budgets never do—the reality of the paths not taken, the contingencies we rarely discuss. And most importantly, they made us better at allocating not just capital, but attention. I am sharing my Bible on this topic, which was referred to me by Dr. Alexander Cassuto at Cal State Hayward in the Econometrics course. It was definitely more pleasant and easier to read than Jiang’s book on Econometrics.

This change in framing altered my approach to every part of revenue operations. Take, for instance, the deal desk. In traditional settings, deal desk is a compliance checkpoint where pricing, terms, and margin constraints are reviewed. But when viewed through an options lens, the deal desk becomes a staging ground for strategic bets. A deeply discounted deal might seem reckless on paper, but if structured with expansion clauses, usage gates, or future upsell options, it can behave like a call option on account growth. The key is to recognize and price the option value. Once I began modeling deals this way, I found we were saying “yes” more often, and with far better clarity on risk.
Data analytics became essential here not for forecasting the exact outcome, but for simulating plausible ones. I leaned heavily on regression modeling, time-series decomposition, and agent-based simulation. We used R to create time-based churn scenarios across customer cohorts. We used Arena to simulate resource allocation under delayed expansion assumptions. These were not predictions. They were controlled chaos exercises, designed to show what could happen, not what would. But the power of this was not just in the results, but it was in the mindset it built. We stopped asking, “What will happen?” and started asking, “What could we do if it does?”
From these simulations, we developed internal thresholds to trigger further investment. For example, if three out of five expansion triggers were fired, such as usage spike, NPS improvement, and additional department adoption, then we would greenlight phase two of GTM spend. That logic replaced endless debate with a predefined structure. It also gave our board more confidence. Rather than asking them to bless a single future, we offered a roadmap of choices, each with its own decision gates. They didn’t need to believe our base case. They only needed to believe we had options.
Yet, as elegant as these models were, the most difficult challenge remained human. People, understandably, want certainty. They want confidence in forecasts, commitment to plans, and clarity in messaging. I had to coach my team and myself to get comfortable with the discomfort of ambiguity. I invoked the concept of bounded rationality from decision science: we make the best decisions we can with the information available to us, within the time allotted. There is no perfect foresight. There is only better framing.
This is where the law of unintended consequences makes its entrance. In traditional finance functions, overplanning often leads to rigidity. You commit to hiring plans that no longer make sense three months in. You promise CAC thresholds that collapse under macro pressure. You bake linearity into a market that moves in waves. When this happens, companies double down, pushing harder against the wrong wall. But when you think in options, you pull back when the signal tells you to. You course-correct. You adapt. And paradoxically, you appear more stable.
As we embedded this thinking deeper into our revenue operations, we also became more cross-functional. Sales began to understand the value of deferring certain go-to-market investments until usage signals validated demand. Product began to view feature development as portfolio choices: some high-risk, high-return, others safer but with less upside. Customer Success began surfacing renewal and expansion probabilities not as binary yes/no forecasts, but as weighted signals on a decision curve. The shared vocabulary of real options gave us a language for navigating ambiguity together.
We also brought this into our capital allocation rhythm. Instead of annual budget cycles, we moved to rolling forecasts with embedded thresholds. If churn stayed below 8% and expansion held steady, we would greenlight an additional five SDRs. If product-led growth signals in EMEA hit critical mass, we’d fund a localized support pod. These weren’t whims. They were contingent commitments, bound by logic, not inertia. And that changed everything.
The results were not perfect. We made wrong bets. Some options expired worthless. Others took longer to mature than we expected. But overall, we made faster decisions with greater alignment. We used our capital more efficiently. And most of all, we built a culture that didn’t flinch at uncertainty—but designed for it.
In the next part of this essay, I will go deeper into the mechanics of implementing this philosophy across the deal desk, QTC architecture, and pipeline forecasting. I will also show how to build dashboards that visualize decision trees and option paths, and how to teach your teams to reason probabilistically without losing speed. Because in a world where volatility is the only certainty, the CFO’s most enduring edge is not control, but it is optionality, structured by design and deployed with discipline.
Part II: Implementing Option Architecture Inside RevOps
A CFO cannot simply preach agility from a whiteboard. To embed optionality into the operational fabric of a company, the theory must show up in tools, in dashboards, in planning cadences, and in the daily decisions made by deal desks, revenue teams, and systems owners. I have found that fundamental transformation comes not from frameworks, but from friction—the friction of trying to make the idea work across functions, under pressure, and at scale. That’s where option thinking proves its worth.
We began by reimagining the deal desk, not as a compliance stop but as a structured betting table. In conventional models, deal desks enforce pricing integrity, review payment terms, and ensure T’s and C’s fall within approved tolerances. That’s necessary, but not sufficient. In uncertain environments—where customer buying behavior, competitive pressure, or adoption curves wobble without warning: rigid deal policies become brittle. The opportunity lies in recasting the deal desk as a decision node within a larger options tree.
Consider a SaaS enterprise deal involving land-and-expand potential. A rigid model forces either full commitment upfront or defers expansion, hoping for a vague “later.” But if we treat the deal like a compound call option, we see more apparent logic. You price the initial land deal aggressively, with usage-based triggers that, when met, unlock favorable expansion terms. You embed a re-pricing clause if usage crosses a defined threshold in 90 days. You insert a “soft commit” expansion clause tied to the active user count. None of these is just a term. They are embedded with real options. And when structured well, they deliver upside without requiring the customer to commit to uncertain future needs.
In practice, this approach meant reworking CPQ systems, retraining legal, and coaching reps to frame options credibly. We designed templates with optionality clauses already coded into Salesforce workflows. Once an account crossed a pre-defined trigger say, 80% license utilization, then the next best action flowed to the account executive and customer success manager. The logic wasn’t linear. It was branching. We visualized deal paths in a way that corresponds to mapping a decision tree in a risk-adjusted capital model.
Yet even the most elegant structure can fail if the operating rhythm stays linear. That is why we transitioned away from rigid quarterly forecasts toward rolling scenario-based planning. Forecasting ceased to be a spreadsheet contest. Instead, we evaluated forecast bands, not point estimates. If base churn exceeded X% in a specific cohort, how did that impact our expansion coverage ratio? If deal velocity in EMEA slowed by two weeks, how would that compress the bookings-to-billings gap? We visualized these as cascading outcomes, not just isolated misses.
To build this capability, we used what I came to call “option dashboards.” These were layered, interactive models with inputs tied to a live pipeline and post-sale telemetry. Each card on the dashboard represented a decision node—an inflection point. Would we deploy more headcount into SMB if the average CAC-to-LTV fell below 3:1? Would we pause feature rollout in one region to redirect support toward a segment with stronger usage signals? Each choice was pre-wired with boundary logic. The decisions didn’t live in a drawer—they lived in motion.
Building these dashboards required investment. But more than tools, it required permission. Teams needed to know they could act on signal, not wait for executive validation every time a deviation emerged. We institutionalized the language of “early signal actionability.” If revenue leaders spotted a decline in renewal health across a cluster of customers tied to the same integration module, they didn’t wait for a churn event. They pulled forward roadmap fixes. That wasn’t just good customer service, but it was real options in flight.
This also brought a new flavor to our capital allocation rhythm. Rather than annual planning cycles that locked resources into static swim lanes, we adopted gated resourcing tied to defined thresholds. Our FP&A team built simulation models in Python and R, forecasting the expected value of a resourcing move based on scenario weightings. For example, if a new vertical showed a 60% likelihood of crossing a 10-deal threshold by mid-Q3, we pre-approved GTM spend to activate contingent on hitting that signal. This looked cautious to some. But in reality, it was aggressive and in the right direction, at the right moment.
Throughout all of this, I kept returning to a central truth: uncertainty punishes rigidity, but rewards those who respect its contours. A pricing policy that cannot flex will leave margin on the table or kill deals in flight. A hiring plan that commits too early will choke working capital. And a CFO who waits for clarity before making bets will find they arrive too late. In decision theory, we often talk about “the cost of delay” versus “the cost of error.” A good options model minimizes both, which, interestingly, is not by being just right, but by being ready.
Of course, optionality without discipline can devolve into indecision. We embedded guardrails. We defined thresholds that made decision inertia unacceptable. If a cohort’s NRR dropped for three consecutive months and win-back campaigns failed, we sunsetted that motion. If a beta feature was unable to hit usage velocity within a quarter, we reallocated the development budget. These were not emotional decisions, but they were logical conclusions of failed options. And we celebrated them. A failed option, tested and closed, beats a zombie investment every time.
We also revised our communication with the board. Instead of defending fixed forecasts, we presented probability-weighted trees. “If churn holds, and expansion triggers fire, we’ll beat target by X.” “If macro shifts pull SMB renewals down by 5%, we stay within plan by flexing mid-market initiatives.” This shifted the conversation from finger-pointing to scenario readiness. Investors liked it. More importantly, so did the executive team. We could disagree on base assumptions but still align on decisions because we’d mapped the branches ahead of time.
One area where this thought made an outsized impact was compensation planning. Sales comp is notoriously fragile under volatility. We redesigned quota targets and commission accelerators using scenario bands, not fixed assumptions. We tested payout curves under best, base, and downside cases. We then ran Monte Carlo simulations to see how frequently actuals would fall into the “too much upside” or “demotivating downside” zones. This led to more durable comp plans, which meant fewer panicked mid-year resets. Our reps trusted the system. And our CFO team could model cost predictability with far greater confidence.
In retrospection, all these loops back to a single mindset shift: you don’t plan to be right. You plan to stay in the game. And staying in the game requires options that are well-designed, embedded into the process, and respected by every function. Sales needs to know they can escalate an expansion offer once particular customer signals fire. Success needs to know they have the budget authority to engage support when early churn flags arise. Product needs to know they can pause a roadmap stream if NPV no longer justifies it. And finance needs to know that its most significant power is not in control, but in preparation.
Today, when I walk into a revenue operations review or a strategic planning offsite, I do not bring a budget with fixed forecasts. I get a map. It has branches. It has signals. It has gates. And it has options, and each one designed not to predict the future, but to help us meet it with composure, and to move quickly when the fog clears.
Because in the world I have operated in, spanning economic cycles, geopolitical events, sudden buyer hesitation, system failures, and moments of exponential product success since 1994 until now, one principle has held. The companies that win are not the ones who guess right. They are the ones who remain ready. And readiness, I have learned, is the true hallmark of a great CFO.
AI and the Evolving Role of CFOs
For much of the twentieth century, the role of the Chief Financial Officer was understood in familiar terms. A steward of control. A master of precision. A guardian of the balance sheet. The CFO was expected to be meticulous, cautious, and above all, accountable. Decisions were made through careful deliberation. Assumptions were scrutinized. Numbers did not lie; they merely required interpretation. There was an art to the conservatism and a quiet pride in it. Order, after all, was the currency of good finance.
Then artificial intelligence arrived—not like a polite guest knocking at the door, but more like a storm bursting through the windows, unsettling assumptions, and rewriting the rules of what it means to manage the financial function. Suddenly, the world of structured inputs and predictable outputs became a dynamic theater of probabilities, models, and machine learning loops. The close of the quarter, once a ritual of discipline and human labor, was now something that could be shortened by algorithms. Forecasts, previously the result of sleepless nights and spreadsheets, could now be generated in minutes. And yet, beneath the glow of progress, a quieter question lingered in the minds of financial leaders: Are we still in control?
The paradox is sharp. AI promises greater accuracy, faster insights, and efficiencies that were once unimaginable. But it also introduces new vulnerabilities. Decisions made by machines cannot always be explained by humans. Data patterns shift, and models evolve in ways that are hard to monitor, let alone govern. The very automation that liberates teams from tedious work may also obscure how decisions are being made. For CFOs, whose role rests on the fulcrum of control and transparency, this presents a challenge unlike any other.
To understand what is at stake, one must first appreciate the philosophical shift taking place. Traditional finance systems were built around rules. If a transaction did not match a predefined criterion, it was flagged. If a value exceeded a threshold, it triggered an alert. There was a hierarchy to control. Approvals, audits, reconciliations—all followed a chain of accountability. AI, however, does not follow rules in the conventional sense. It learns patterns. It makes predictions. It adjusts based on what it sees. In place of linear logic, it offers probability. In place of rules, it gives suggestions.
This does not make AI untrustworthy, but it does make it unfamiliar. And unfamiliarity breeds caution. For CFOs who have spent decades refining control environments, AI is not merely a tool. It is a new philosophy of decision-making. And it is one that challenges the muscle memory of the profession.
What, then, does it mean to stay in control in an AI-enhanced finance function? It begins with visibility. CFOs must ensure that the models driving key decisions—forecasts, risk assessments, working capital allocations—are not black boxes. Every algorithm must come with a passport. What data went into it? What assumptions were made? How does it behave when conditions change? These are not technical questions alone. They are governance questions. And they sit at the heart of responsible financial leadership.
Equally critical is the quality of data. An AI model is only as reliable as the information it consumes. Dirty data, incomplete records, or inconsistent definitions can quickly derail the most sophisticated tools. In this environment, the finance function must evolve from being a consumer of data to a custodian of it. The general ledger, once a passive repository of transactions, becomes part of a living data ecosystem. Consistency matters. Lineage matters. And above all, context matters. A forecast that looks brilliant in isolation may collapse under scrutiny if it was trained on flawed assumptions.
But visibility and data are only the beginning. As AI takes on more tasks that were once performed by humans, the traditional architecture of control must be reimagined. Consider the principle of segregation of duties. In the old world, one person entered the invoice, another approved it, and a third reviewed the ledger. These checks and balances were designed to prevent fraud, errors, and concentration of power. But what happens when an AI model is performing all three functions? Who oversees the algorithm? Who reviews the reviewer?
The answer is not to retreat from automation, but to introduce new forms of oversight. CFOs must create protocols for algorithmic accountability. This means establishing thresholds for machine-generated recommendations, building escalation paths for exceptions, and defining moments when human judgement must intervene. It is not about mistrusting the machine. It is about ensuring that the machine is governed with the same discipline once reserved for people.
And then there is the question of resilience. AI introduces new dependencies—on data pipelines, on cloud infrastructures, on model stability. A glitch in a forecasting model could ripple through the entire enterprise plan. A misfire in an expense classifier could disrupt a close. These are not hypothetical risks. They are operational realities. Just as organizations have disaster recovery plans for cyber breaches or system outages, they must now develop contingency plans for AI failures. The models must be monitored. The outputs must be tested. And the humans must be prepared to take over when the automation stumbles.
Beneath all of this, however, lies a deeper cultural transformation. The finance team of the future will not be composed solely of accountants, auditors, and analysts. It will also include data scientists, machine learning specialists, and process architects. The rhythm of work will shift—from data entry and manual reconciliations to interpretation, supervision, and strategic advising. This demands a new kind of fluency. Not necessarily the ability to write code, but the ability to understand how AI works, what it can do, and where its boundaries lie.
This is not a small ask. It requires training, cross-functional collaboration, and a willingness to challenge tradition. But it also opens the door to a more intellectually rich finance function—one where humans and machines collaborate to generate insights that neither could have achieved alone.
If there is a guiding principle in all of this, it is that control does not mean resisting change. It means shaping it. For CFOs, the task is not to retreat into spreadsheets or resist the encroachment of algorithms. It is to lead the integration of intelligence into every corner of the finance operation. To set the standards, define the guardrails, and ensure that the organization embraces automation not as a surrender of responsibility, but as an evolution of it.
Because in the end, the goal is not simply to automate. It is to augment. Not to replace judgement, but to elevate it. Not to remove the human hand from finance, but to position it where it matters most: at the helm, guiding the ship through faster currents, with clearer vision and steadier hands.
Artificial intelligence may never match the emotional weight of human intuition. It may not understand the stakes behind a quarter’s earnings or the subtle implications of a line item in a note to shareholders. But it can free up time. It can provide clarity. It can make the financial function faster, more adaptive, and more resilient.
And if the CFO of the past was a gatekeeper, the CFO of the future will be a choreographer—balancing risk and intelligence, control and creativity, all while ensuring that the numbers, no matter how complex their origin, still tell a story that is grounded in truth.
The machines are here. They are learning. And they are listening. The challenge is not to contain them, but to guide them—thoughtfully, carefully, and with the discipline that has always defined great finance.
Because in this new world, control is not lost. It is simply redefined.
Bias and Error: Human and Organizational Tradeoff
“I spent a lifetime trying to avoid my own mental biases. A.) I rub my own nose into my own mistakes. B.) I try and keep it simple and fundamental as much as I can. And, I like the engineering concept of a margin of safety. I’m a very blocking and tackling kind of thinker. I just try to avoid being stupid. I have a way of handling a lot of problems — I put them in what I call my ‘too hard pile,’ and just leave them there. I’m not trying to succeed in my ‘too hard pile.’” : Charlie Munger — 2020 CalTech Distinguished Alumni Award interview
Bias is a disproportionate weight in favor of or against an idea or thing, usually in a way that is closed-minded, prejudicial, or unfair. Biases can be innate or learned. People may develop biases for or against an individual, a group, or a belief. In science and engineering, a bias is a systematic error. Statistical bias results from an unfair sampling of a population, or from an estimation process that does not give accurate results on average.
Error refers to a outcome that is different from reality within the context of the objective function that is being pursued.
Thus, I would like to think that the Bias is a process that might lead to an Error. However, that is not always the case. There are instances where a bias might get you to an accurate or close to an accurate result. Is having a biased framework always a bad thing? That is not always the case. From an evolutionary standpoint, humans have progressed along the dimension of making rapid judgements – and much of them stemming from experience and their exposure to elements in society. Rapid judgements are typified under the System 1 judgement (Kahneman, Tversky) which allows bias and heuristic to commingle to effectively arrive at intuitive decision outcomes.

And again, the decision framework constitutes a continually active process in how humans or/and organizations execute upon their goals. It is largely an emotional response but could just as well be an automated response to a certain stimulus. However, there is a danger prevalent in System 1 thinking: it might lead one to comfortably head toward an outcome that is seemingly intuitive, but the actual result might be significantly different and that would lead to an error in the judgement. In math, you often hear the problem of induction which establishes that your understanding of a future outcome relies on the continuity of the past outcomes, and that is an errant way of thinking although it still represents a useful tool for us to advance toward solutions.
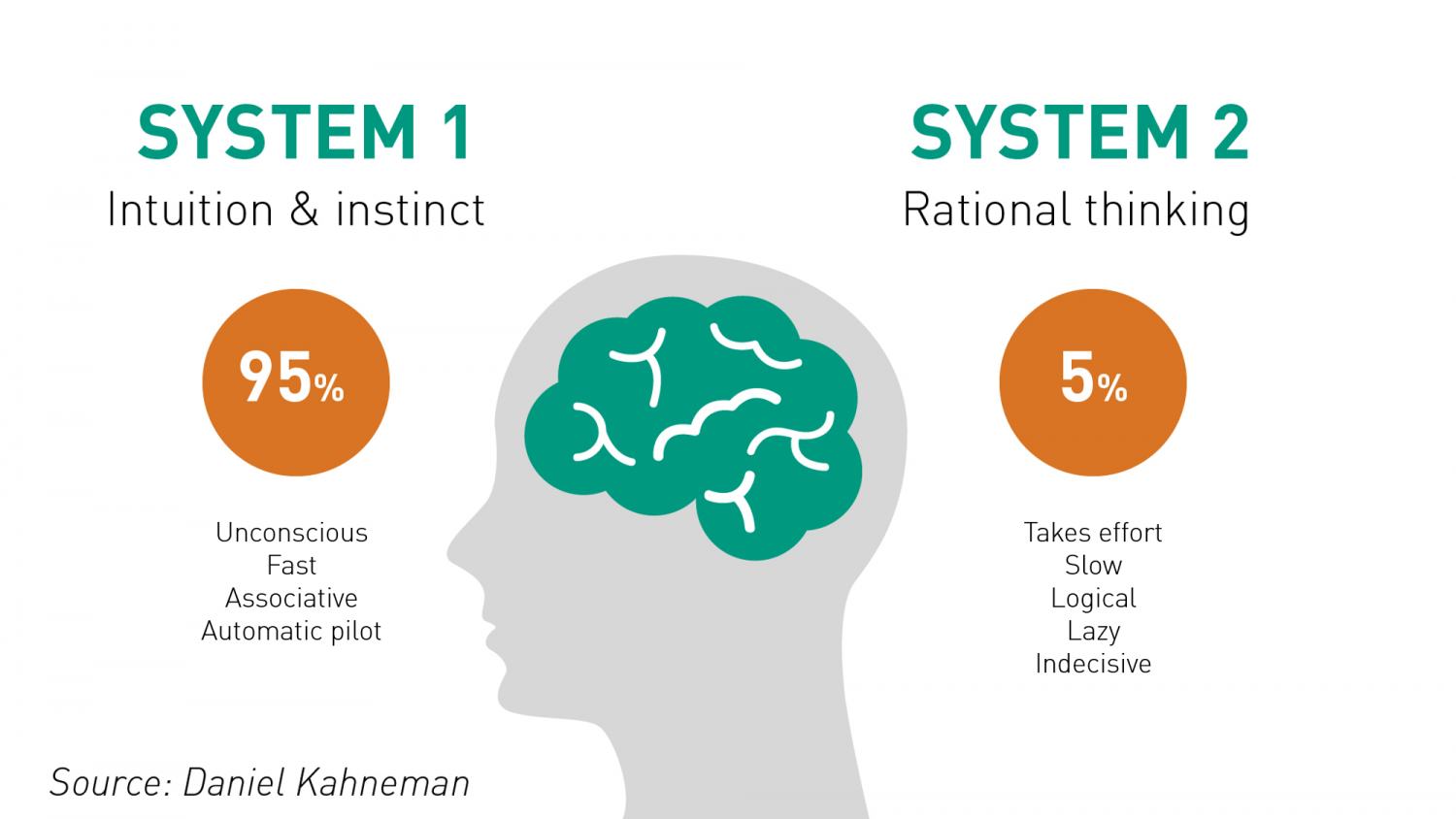
System 2 judgement emerges as another means to temper the more significant variabilities associated with System 1 thinking. System 2 thinking represents a more deliberate approach which leads to a more careful construct of rationale and thought. It is a system that slows down the decision making since it explores the logic, the assumptions, and how the framework tightly fits together to test contexts. There are a more lot more things at work wherein the person or the organization has to invest the time, focus the efforts and amplify the concentration around the problem that has to be wrestled with. This is also the process where you search for biases that might be at play and be able to minimize or remove that altogether. Thus, each of the two Systems judgement represents two different patterns of thinking: rapid, more variable and more error prone outcomes vs. slow, stable and less error prone outcomes.
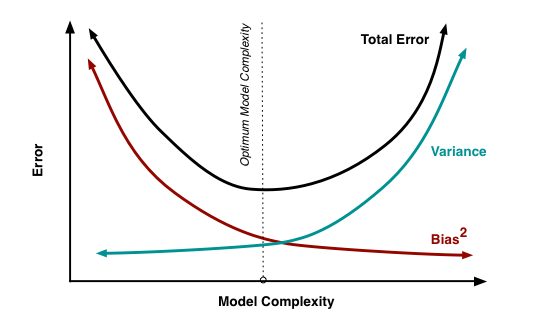
So let us revisit the Bias vs. Variance tradeoff. The idea is that the more bias you bring to address a problem, there is less variance in the aggregate. That does not mean that you are accurate. It only means that there is less variance in the set of outcomes, even if all of the outcomes are materially wrong. But it limits the variance since the bias enforces a constraint in the hypotheses space leading to a smaller and closely knit set of probabilistic outcomes. If you were to remove the constraints in the hypotheses space – namely, you remove bias in the decision framework – well, you are faced with a significant number of possibilities that would result in a larger spread of outcomes. With that said, the expected value of those outcomes might actually be closer to reality, despite the variance – than a framework decided upon by applying heuristic or operating in a bias mode.
So how do we decide then? Jeff Bezos had mentioned something that I recall: some decisions are one-way street and some are two-way. In other words, there are some decisions that cannot be undone, for good or for bad. It is a wise man who is able to anticipate that early on to decide what system one needs to pursue. An organization makes a few big and important decisions, and a lot of small decisions. Identify the big ones and spend oodles of time and encourage a diverse set of input to work through those decisions at a sufficiently high level of detail. When I personally craft rolling operating models, it serves a strategic purpose that might sit on shifting sands. That is perfectly okay! But it is critical to evaluate those big decisions since the crux of the effectiveness of the strategy and its concomitant quantitative representation rests upon those big decisions. Cutting corners can lead to disaster or an unforgiving result!

I will focus on the big whale decisions now. I will assume, for the sake of expediency, that the series of small decisions, in the aggregate or by itself, will not sufficiently be large enough that it would take us over the precipice. (It is also important however to examine the possibility that a series of small decisions can lead to a more holistic unintended emergent outcome that might have a whale effect: we come across that in complexity theory that I have already touched on in a set of previous articles).

Cognitive Biases are the biggest mea culpas that one needs to worry about. Some of the more common biases are confirmation bias, attribution bias, the halo effect, the rule of anchoring, the framing of the problem, and status quo bias. There are other cognition biases at play, but the ones listed above are common in planning and execution. It is imperative that these biases be forcibly peeled off while formulating a strategy toward problem solving.
But then there are also the statistical biases that one needs to be wary of. How we select data or selection bias plays a big role in validating information. In fact, if there are underlying statistical biases, the validity of the information is questionable. Then there are other strains of statistical biases: the forecast bias which is the natural tendency to be overtly optimistic or pessimistic without any substantive evidence to support one or the other case. Sometimes how the information is presented: visually or in tabular format – can lead to sins of the error of omission and commission leading the organization and judgement down paths that are unwarranted and just plain wrong. Thus, it is important to be aware of how statistical biases come into play to sabotage your decision framework.

One of the finest illustrations of misjudgment has been laid out by Charlie Munger. Here is the excerpt link : https://fs.blog/great-talks/psychology-human-misjudgment/ He lays out a very comprehensive 25 Biases that ail decision making. Once again, stripping biases do not necessarily result in accuracy — it increases the variability of outcomes that might be clustered around a mean that might be closer to accuracy than otherwise.
Variability is Noise. We do not know a priori what the expected mean is. We are close, but not quite. There is noise or a whole set of outcomes around the mean. Viewing things closer to the ground versus higher would still create a likelihood of accepting a false hypothesis or rejecting a true one. Noise is extremely hard to sift through, but how you can sift through the noise to arrive at those signals that are determining factors, is critical to organization success. To get to this territory, we have eliminated the cognitive and statistical biases. Now is the search for the signal. What do we do then? An increase in noise impairs accuracy. To improve accuracy, you either reduce noise or figure out those indicators that signal an accurate measure.
This is where algorithmic thinking comes into play. You start establishing well tested algorithms in specific use cases and cross-validate that across a large set of experiments or scenarios. It has been proved that algorithmic tools are, in the aggregate, superior to human judgement – since it systematically can surface causal and correlative relationships. Furthermore, special tools like principal component analysis and factory analysis can incorporate a large input variable set and establish the patterns that would be impregnable for even System 2 mindset to comprehend. This will bring decision making toward the signal variants and thus fortify decision making.

The final element is to assess the time commitment required to go through all the stages. Given infinite time and resources, there is always a high likelihood of arriving at those signals that are material for sound decision making. Alas, the reality of life does not play well to that assumption! Time and resources are constraints … so one must make do with sub-optimal decision making and establish a cutoff point wherein the benefits outweigh the risks of looking for another alternative. That comes down to the realm of judgements. While George Stigler, a Nobel Laureate in Economics, introduce search optimization in fixed sequential search – a more concrete example has been illustrated in “Algorithms to Live By” by Christian & Griffiths. They suggested an holy grail response: 37% is the accurate answer. In other words, you would reach a suboptimal decision by ensuring that you have explored up to 37% of your estimated maximum effort. While the estimated maximum effort is quite ambiguous and afflicted with all of the elements of bias (cognitive and statistical), the best thinking is to be as honest as possible to assess that effort and then draw your search threshold cutoff.

An important element of leadership is about making calls. Good calls, not necessarily the best calls! Calls weighing all possible circumstances that one can, being aware of the biases, bringing in a diverse set of knowledge and opinions, falling back upon agnostic tools in statistics, and knowing when it is appropriate to have learnt enough to pull the trigger. And it is important to cascade the principles of decision making and the underlying complexity into and across the organization.
Navigating Chaos and Model Thinking
An inherent property of a chaotic system is that slight changes in initial conditions in the system result in a disproportionate change in outcome that is difficult to predict. Chaotic systems appear to create outcomes that appear to be random: they are generated by simple and non-random processes but the complexity of such systems emerge over time driven by numerous iterations of simple rules. The elements that compose chaotic systems might be few in number, but these elements work together to produce an intricate set of dynamics that amplifies the outcome and makes it hard to be predictable. These systems evolve over time, doing so according to rules and initial conditions and how the constituent elements work together.
Complex systems are characterized by emergence. The interactions between the elements of the system with its environment create new properties which influence the structural development of the system and the roles of the agents. In such systems there is self-organization characteristics that occur, and hence it is difficult to study and effect a system by studying the constituent parts that comprise it. The task becomes even more formidable when one faces the prevalent reality that most systems exhibit non-linear dynamics.
So how do we incorporate management practices in the face of chaos and complexity that is inherent in organization structure and market dynamics? It would be interesting to study this in light of the evolution of management principles in keeping with the evolution of scientific paradigms.

Newtonian Mechanics and Taylorism
Traditional organization management has been heavily influenced by Newtonian mechanics. The five key assumptions of Newtonian mechanics are:
- Reality is objective
- Systems are linear and there is a presumption that all underlying cause and effect are linear
- Knowledge is empirical and acquired through collecting and analyzing data with the focus on surfacing regularities, predictability and control
- Systems are inherently efficient. Systems almost always follows the path of least resistance
- If inputs and process is managed, the outcomes are predictable
Frederick Taylor is the father of operational research and his methods were deployed in automotive companies in the 1940’s. Workers and processes are input elements to ensure that the machine functions per expectations. There was a linearity employed in principle. Management role was that of observation and control and the system would best function under hierarchical operating principles. Mass and efficient production were the hallmarks of management goal.
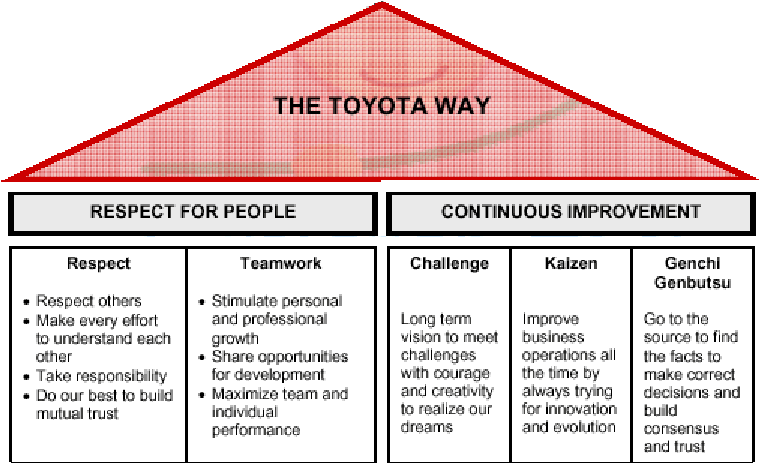
Randomness and the Toyota Way
The randomness paradigm recognized uncertainty as a pervasive constant. The various methods that Toyota Way invoked around 5W rested on the assumption that understanding the cause and effect is instrumental and this inclined management toward a more process-based deployment. Learning is introduced in this model as a dynamic variable and there is a lot of emphasis on the agents and providing them the clarity and purpose of their tasks. Efficiencies and quality are presumably driven by the rank and file and autonomous decisions are allowed. The management principle moves away from hierarchical and top-down to a more responsibility driven labor force.
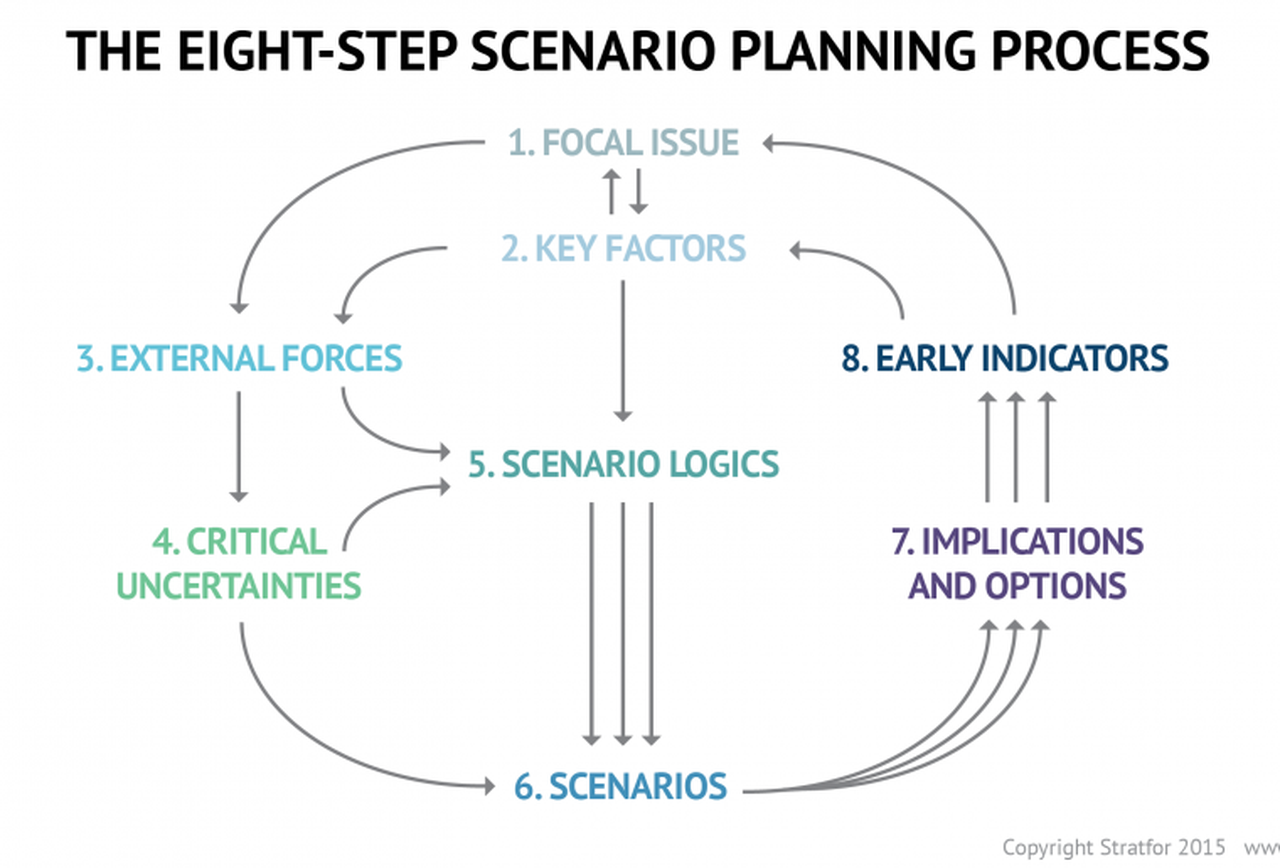
Complexity and Chaos and the Nimble Organization
Increasing complexity has led to more demands on the organization. With the advent of social media and rapid information distribution and a general rise in consciousness around social impact, organizations have to balance out multiple objectives. Any small change in initial condition can lead to major outcomes: an advertising mistake can become a global PR nightmare; a word taken out of context could have huge ramifications that might immediately reflect on the stock price; an employee complaint could force management change. Increasing data and knowledge are not sufficient to ensure long-term success. In fact, there is no clear recipe to guarantee success in an age fraught with non-linearity, emergence and disequilibrium. To succeed in this environment entails the development of a learning organization that is not governed by fixed top-down rules: rather the rules are simple and the guidance is around the purpose of the system or the organization. It is best left to intellectual capital to self-organize rapidly in response to external information to adapt and make changes to ensure organization resilience and success.
Companies are dynamic non-linear adaptive systems. The elements in the system are constantly interacting between themselves and their external environment. This creates new emergent properties that are sensitive to the initial conditions. A change in purpose or strategic positioning could set a domino effect and can lead to outcomes that are not predictable. Decisions are pushed out to all levels in the organization, since the presumption is that local and diverse knowledge that spontaneously emerge in response to stimuli is a superior structure than managing for complexity in a centralized manner. Thus, methods that can generate ideas, create innovation habitats, and embrace failures as providing new opportunities to learn are best practices that companies must follow. Traditional long-term planning and forecasting is becoming a far harder exercise and practically impossible. Thus, planning is more around strategic mindset, scenario planning, allowing local rules to auto generate without direct supervision, encourage dissent and diversity, stimulate creativity and establishing clarity of purpose and broad guidelines are the hall marks of success.
Principles of Leadership in a New Age
We have already explored the fact that traditional leadership models originated in the context of mass production and efficiencies. These models are arcane in our information era today, where systems are characterized by exponential dynamism of variables, increased density of interactions, increased globalization and interconnectedness, massive information distribution at increasing rapidity, and a general toward economies driven by free will of the participants rather than a central authority.

Complexity Leadership Theory (Uhl-Bien) is a “framework for leadership that enables the learning, creative and adaptive capacity of complex adaptive systems in knowledge-producing organizations or organizational units. Since planning for the long-term is virtually impossible, Leadership has to be armed with different tool sets to steer the organization toward achieving its purpose. Leaders take on enabler role rather than controller role: empowerment supplants control. Leadership is not about focus on traits of a single leader: rather, it redirects emphasis from individual leaders to leadership as an organizational phenomenon. Leadership is a trait rather than an individual. We recognize that complex systems have lot of interacting agents – in business parlance, which might constitute labor and capital. Introducing complexity leadership is to empower all of the agents with the ability to lead their sub-units toward a common shared purpose. Different agents can become leaders in different roles as their tasks or roles morph rapidly: it is not necessarily defined by a formal appointment or knighthood in title.
Thus, complexity of our modern-day reality demands a new strategic toolset for the new leader. The most important skills would be complex seeing, complex thinking, complex knowing, complex acting, complex trusting and complex being. (Elena Osmodo, 2012)

Complex Seeing: Reality is inherently subjective. It is a page of the Heisenberg Uncertainty principle that posits that the independence between the observer and the observed is not real. If leaders are not aware of this independence, they run the risk of engaging in decisions that are fraught with bias. They will continue to perceive reality with the same lens that they have perceived reality in the past, despite the fact that undercurrents and riptides of increasingly exponential systems are tearing away their “perceived reality.” Leader have to be conscious about the tectonic shifts, reevaluate their own intentions, probe and exclude biases that could cloud the fidelity of their decisions, and engage in a continuous learning process. The ability to sift and see through this complexity sets the initial condition upon which the entire system’s efficacy and trajectory rests.
Complex Thinking: Leaders have to be cognizant of falling prey to linear simple cause and effect thinking. On the contrary, leaders have to engage in counter-intuitive thinking, brainstorming and creative thinking. In addition, encouraging dissent, debates and diversity encourage new strains of thought and ideas.
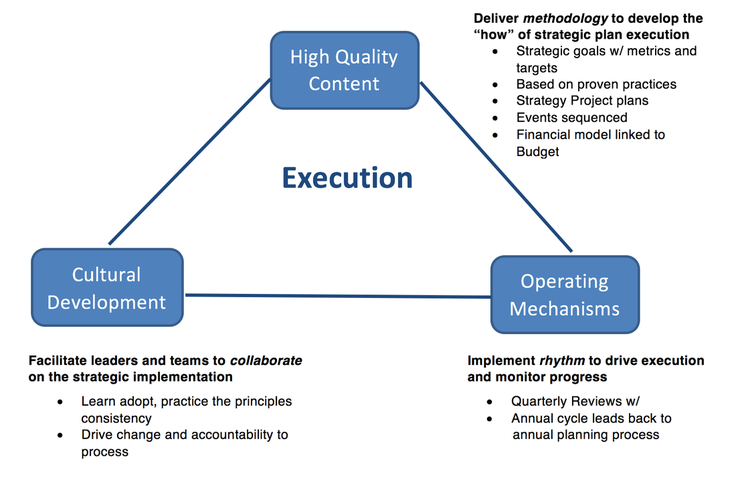
Complex Feeling: Leaders must maintain high levels of energy and be optimistic of the future. Failures are not scoffed at; rather they are simply another window for learning. Leaders have to promote positive and productive emotional interactions. The leaders are tasked to increase positive feedback loops while reducing negative feedback mechanisms to the extent possible. Entropy and attrition taxes any system as is: the leader’s job is to set up safe environment to inculcate respect through general guidelines and leading by example.
Complex Knowing: Leadership is tasked with formulating simple rules to enable learned and quicker decision making across the organization. Leaders must provide a common purpose, interconnect people with symbols and metaphors, and continually reiterate the raison d’etre of the organization. Knowing is articulating: leadership has to articulate and be humble to any new and novel challenges and counterfactuals that might arise. The leader has to establish systems of knowledge: collective learning, collaborative learning and organizational learning. Collective learning is the ability of the collective to learn from experiences drawn from the vast set of individual actors operating in the system. Collaborative learning results due to interaction of agents and clusters in the organization. Learning organization, as Senge defines it, is “where people continually expand their capacity to create the results they truly desire, where new and expansive patterns of thinking are nurtured, where collective aspirations are set free, and where people are continually learning to see the whole together.”
Complex Acting: Complex action is the ability of the leader to not only work toward benefiting the agents in his/her purview, but also to ensure that the benefits resonates to a whole which by definition is greater than the sum of the parts. Complex acting is to take specific action-oriented steps that largely reflect the values that the organization represents in its environmental context.
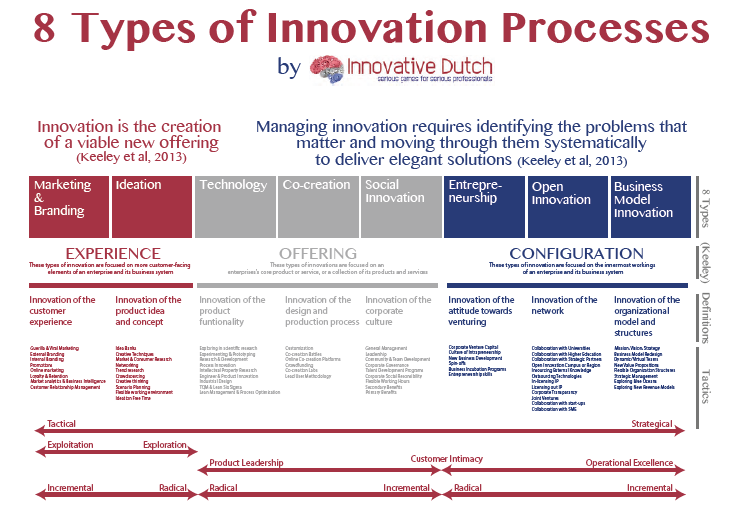
Complex Trusting: Decentralization requires conferring power to local agents. For decentralization to work effectively, leaders have to trust that the agents will, in the aggregate, work toward advancing the organization. The cost of managing top-down is far more than the benefits that a trust-based decentralized system would work in a dynamic environment resplendent with the novelty of chaos and complexity.
Complex Being: This is the ability of the leaser to favor and encourage communication across the organization rapidly. The leader needs to encourage relationships and inter-functional dialogue.
The role of complex leaders is to design adaptive systems that are able to cope with challenging and novel environments by establishing a few rules and encouraging agents to self-organize autonomously at local levels to solve challenges. The leader’s main role in this exercise is to set the strategic directions and the guidelines and let the organizations run.
Chaos as a system: New Framework
Chaos is not an unordered phenomenon. There is a certain homeostatic mechanism at play that forces a system that might have inherent characteristics of a “chaotic” process to converge to some sort of stability with respect to predictability and parallelism. Our understanding of order which is deemed to be opposite of chaos is the fact that there is a shared consensus that the system will behave in an expected manner. Hence, we often allude to systems as being “balanced” or “stable” or “in order” to spotlight these systems. However, it is also becoming common knowledge in the science of chaos that slight changes in initial conditions in a system can emit variability in the final output that might not be predictable. So how does one straddle order and chaos in an observed system, and what implications does this process have on ongoing study of such systems?

Chaotic systems can be considered to have a highly complex order. It might require the tools of pure mathematics and extreme computational power to understand such systems. These tools have invariably provided some insights into chaotic systems by visually representing outputs as re-occurrences of a distribution of outputs related to a given set of inputs. Another interesting tie up in this model is the existence of entropy, that variable that taxes a system and diminishes the impact on expected outputs. Any system acts like a living organism: it requires oodles of resources to survive and a well-established set of rules to govern its internal mechanism driving the vector of its movement. Suddenly, what emerges is the fact that chaotic systems display some order while subject to an inherent mechanism that softens its impact over time. Most approaches to studying complex and chaotic systems involve understanding graphical plots of fractal nature, and bifurcation diagrams. These models illustrate very complex re occurrences of outputs directly related to inputs. Hence, complex order occurs from chaotic systems.
A case in point would be the relation of a population parameter in the context to its immediate environment. It is argued that a population in an environment will maintain a certain number and there would be some external forces that will actively work to ensure that the population will maintain at that standard number. It is a very Malthusian analytic, but what is interesting is that there could be some new and meaningful influences on the number that might increase the scale. In our current meaning, a change in technology or ingenuity could significantly alter the natural homeostatic number. The fact remains that forces are always at work on a system. Some systems are autonomic – it self-organizes and corrects itself toward some stable convergence. Other systems are not autonomic and once can only resort to the laws of probability to get some insight into the possible outputs – but never to a point where there is a certainty in predictive prowess.
Organizations have a lot of interacting variables at play at any given moment. In order to influence the organization behavior or/and direction, policies might be formulated to bring about the desirable results. However, these nudges toward setting off the organization in the right direction might also lead to unexpected results. The aim is to foresee some of these unexpected results and mollify the adverse consequences while, in parallel, encourage the system to maximize the benefits. So how does one effect such changes?
It all starts with building out an operating framework. There needs to be a clarity around goals and what the ultimate purpose of the system is. Thus there are few objectives that bind the framework.
- Clarity around goals and the timing around achieving these goals. If there is no established time parameter, then the system might jump across various states over time and it would be difficult to establish an outcome.
- Evaluate all of the internal and external factors that might operate in the framework that would impact the success of organizational mandates and direction. Identify stasis or potential for stasis early since that mental model could stem the progress toward a desirable impact.
- Apply toll gates strategically to evaluate if the system is proceeding along the lines of expectation, and any early aberrations are evaluated and the rules are tweaked to get the system to track on a desirable trajectory.
- Develop islands of learning across the path and engage the right talent and other parameters to force adaptive learning and therefore a more autonomic direction to the system.
- Bind the agents and actors in the organization to a shared sense of purpose within the parameter of time.
- Introduce diversity into the framework early in the process. The engagement of diversity allows the system to modulate around a harmonic mean.
- Finally, maintain a well document knowledge base such that the accretive learning that results due to changes in the organization become springboard for new initiatives that reduces the costs of potential failures or latency in execution.
- Encouraging the leadership to ensure that the vector is pointed toward the right direction at any given time.
Once a framework and the engagement rules are drawn out, it is necessary to rely on the natural velocity and self-organization of purposeful agents to move the agenda forward, hopefully with little or no intervention. A mechanism of feedback loops along the way would guide the efficacy of the direction of the system. The implications is that the strategy and the operations must be aligned and reevaluated and positive behavior is encouraged to ensure that the systems meets its objective.

However, as noted above, entropy is a dynamic that often threatens to derail the system objective. There will be external or internal forces constantly at work to undermine system velocity. The operating framework needs to anticipate that real possibility and pre-empt that with rules or introduction of specific capital to dematerialize these occurrences. Stasis is an active agent that can work against the system dynamic. Stasis is the inclination of agents or behaviors that anchors the system to some status quo – we have to be mindful that change might not be embraced and if there are resistors to that change, the dynamic of organizational change can be invariably impacted. It will take a lot more to get something done than otherwise needed. Identifying stasis and agents of stasis is a foundational element
While the above is one example of how to manage organizations in the shadows of the properties of how chaotic systems behave, another example would be the formulation of strategy of the organization in responses to external forces. How do we apply our learnings in chaos to deal with the challenges of competitive markets by aligning the internal organization to external factors? One of the key insights that chaos surfaces is that it is nigh impossible for one to fully anticipate all of the external variables, and leaving the system to dynamically adapt organically to external dynamics would allow the organization to thrive. To thrive in this environment is to provide the organization to rapidly change outside of the traditional hierarchical expectations: when organizations are unable to make those rapid changes or make strategic bets in response to the external systems, then the execution value of the organization diminishes.
Margaret Wheatley in her book Leadership and the New Science: Discovering Order in a Chaotic World Revised says, “Organizations lack this kind of faith, faith that they can accomplish their purposes in various ways and that they do best when they focus on direction and vision, letting transient forms emerge and disappear. We seem fixated on structures…and organizations, or we who create them, survive only because we build crafty and smart—smart enough to defend ourselves from the natural forces of destruction. Karl Weick, an organizational theorist, believes that “business strategies should be “just in time…supported by more investment in general knowledge, a large skill repertoire, the ability to do a quick study, trust in intuitions, and sophistication in cutting losses.”
We can expand the notion of a chaos in a system to embrace the bigger challenges associated with environment, globalization, and the advent of disruptive technologies.
One of the key challenges to globalization is how policy makers would balance that out against potential social disintegration. As policies emerge to acknowledge the benefits and the necessity to integrate with a new and dynamic global order, the corresponding impact to local institutions can vary and might even lead to some deleterious impact on those institutions. Policies have to encourage flexibility in local institutional capability and that might mean increased investments in infrastructure, creating a diverse knowledge base, establishing rules that govern free but fair trading practices, and encouraging the mobility of capital across borders. The grand challenges of globalization is weighed upon by government and private entities that scurry to create that continual balance to ensure that the local systems survive and flourish within the context of the larger framework. The boundaries of the system are larger and incorporates many more agents which effectively leads to the real possibility of systems that are difficult to be controlled via a hierarchical or centralized body politic Decision making is thus pushed out to the agents and actors but these work under a larger set of rules. Rigidity in rules and governance can amplify failures in this process.

Related to the realities of globalization is the advent of the growth in exponential technologies. Technologies with extreme computational power is integrating and create robust communication networks within and outside of the system: the system herein could represent nation-states or companies or industrialization initiatives. Will the exponential technologies diffuse across larger scales quickly and will the corresponding increase in adoption of new technologies change the future of the human condition? There are fears that new technologies would displace large groups of economic participants who are not immediately equipped to incorporate and feed those technologies into the future: that might be on account of disparity in education and wealth, institutional policies, and the availability of opportunities. Since technologies are exponential, we get a performance curve that is difficult for us to understand. In general, we tend to think linearly and this frailty in our thinking removes us from the path to the future sooner than later. What makes this difficult is that the exponential impact is occurring across various sciences and no one body can effectively fathom the impact and the direction. Bill Gates says it well “We always overestimate the change that will occur in the next two years and underestimate the change that will occur in the next ten. Don’t let yourself be lulled into inaction.” Does chaos theory and complexity science arm us with a differentiated tool set than the traditional toolset of strategy roadmaps and product maps? If society is being carried by the intractable and power of the exponent in advances in technology, than a linear map might not serve to provide the right framework to develop strategies for success in the long-term. Rather, a more collaborative and transparent roadmap to encourage the integration of thoughts and models among the actors who are adapting and adjusting dynamically by the sheer force of will would perhaps be an alternative and practical approach in the new era.

Lately there has been a lot of discussion around climate change. It has been argued, with good reason and empirical evidence, that environment can be adversely impacted on account of mass industrialization, increase in population, resource availability issues, the inability of the market system to incorporate the cost of spillover effects, the adverse impact of moral hazard and the theory of the commons, etc. While there are demurrers who contest the long-term climate change issues, the train seems to have already left the station! The facts do clearly reflect that the climate will be impacted. Skeptics might argue that science has not yet developed a precise predictive model of the weather system two weeks out, and it is foolhardy to conclude a dystopian future on climate fifty years out. However, the alternative argument is that our inability to exercise to explain the near-term effects of weather changes and turbulence does not negate the existence of climate change due to the accretion of greenhouse impact. Boiling a pot of water will not necessarily gives us an understanding of all of the convection currents involved among the water molecules, but it certainly does not shy away from the fact that the water will heat up.
History of Chaos
| Chaos is inherent in all compounded things. Strive on with diligence! –Buddha |
Scientific theories are characterized by the fact that they are open to refutation. To create a scientific model, there are three successive steps that one follows: observe the phenomenon, translate that into equations, and then solve the equations.

One of the early philosophers of science, Karl Popper (1902-1994) discussed this at great length in his book – The Logic of Scientific Discovery. He distinguishes scientific theories from metaphysical or mythological assertions. His main theses is that a scientific theory must be open to falsification: it has to be reproducible separately and yet one can gather data points that might refute the fundamental elements of theory. Developing a scientific theory in a manner that can be falsified by observations would result in new and more stable theories over time. Theories can be rejected in favor of a rival theory or a calibration of the theory in keeping with the new set of observations and outcomes that the theories posit. Until Popper’s time and even after, social sciences have tried to work on a framework that would allow the construction of models that would formulate some predictive laws that govern social dynamics. In his book, Poverty of Historicism, Popper maintained that such an endeavor is not fruitful since it does not take into consideration the myriad of minor elements that interact closely with one another in a meaningful way. Hence, he has touched indirectly on the concept of chaos and complexity and how it touches the scientific method. We will now journey into the past and through the present to understand the genesis of the theory and how it has been channelized by leading scientists and philosophers to decipher a framework for study society and nature.

As we have already discussed, one of the main pillars of Science is determinism: the probability of prediction. It holds that every event is determined by natural laws. Nothing can happen without an unbroken chain of causes that can be traced all the way back to an initial condition. The deterministic nature of science goes all the way back to Aristotelian times. Interestingly, Aristotle argued that there is some degree of indeterminism and he relegated this to chance or accidents. Chance is a character that makes its presence felt in every plot in the human and natural condition. Aristotle wrote that “we do not have knowledge of a thing until we have grasped its why, that is to say, its cause.” He goes on to illustrate his idea in greater detail – namely, that the final outcome that we see in a system is on account of four kinds of influencers: Matter, Form, Agent and Purpose.

Matter is what constitutes the outcome. For a chair it might be wood. For a statue, it might be marble. The outcome is determined by what constitutes the outcome.
Form refers to the shape of the outcome. Thus, a carpenter or a sculptor would have a pre-conceived notion of the shape of the outcome and they would design toward that artifact.
Agent refers to the efficient cause or the act of producing the outcome. Carpentry or masonry skills would be important to shape the final outcome.
Finally, the outcome itself must serve a purpose on its own. For a chair, it might be something to sit on, for a statue it might be something to be marveled at.
However, Aristotle also admits that luck and chance can play an important role that do not fit the causal framework in its own right. Some things do happen by chance or luck. Chance is a rare event, it is a random event and it is typically brought out by some purposeful action or by nature.

We had briefly discussed the Laplace demon and he summarized this wonderfully: “We ought then to consider the resent state of the universe as the effect of its previous state and as the cause of that which is to follow. An intelligence that, at a given instant, could comprehend all the forces by which nature is animated and the respective situation of the beings that make it up if moreover it were vast enough to submit these data to analysis, would encompass in the same formula the movements of the greatest bodies of the universe and those of the lightest atoms. For such an intelligence nothing would be uncertain, and the future, like the past, would be open to its eyes.” He thus admits to the fact that we lack the vast intelligence and we are forced to use probabilities in order to get a sense of understanding of dynamical systems.

It was Maxwell in his pivotal book “Matter and Motion” published in 1876 lay the groundwork of chaos theory.
“There is a maxim which is often quoted, that “the same causes will always produce the same effects.’ To make this maxim intelligible we must define what we mean by the same causes and the same effects, since it is manifest that no event ever happens more than once, so that the causes and effects cannot be the same in all respects. There is another maxim which must not be confounded with that quoted at the beginning of this article, which asserts “That like causes produce like effects.” This is only true when small variations in the initial circumstances produce only small variations in the final state of the system. In a great many physical phenomena this condition is satisfied: but there are other cases in which a small initial variation may produce a great change in the final state of the system, as when the displacement of the points cause a railway train to run into another instead of keeping its proper course.” What is interesting however in the above quote is that Maxwell seems to go with the notion that in a great many cases there is no sensitivity to initial conditions.

In the 1890’s Henri Poincare was the first exponent of chaos theory. He says “it may happen that small differences in the initial conditions produce very great ones in the final phenomena. A small error in the former will produce an enormous error in the latter. Prediction becomes impossible.” This was a far cry from the Newtonian world which sought order on how the solar system worked. Newton’s model was posted on the basis of the interaction between just two bodies. What would then happen if three bodies or N bodies were introduced into the model. This led to the rise of the Three Body Problem which led to Poincare embracing the notion that this problem could not be solved and can be tackled by approximate numerical techniques. Solving this resulted in solutions that were so tangled that is was difficult to not only draw them, it was near impossible to derive equations to fit the results. In addition, Poincare also discovered that if the three bodies started from slightly different initial positions, the orbits would trace out different paths. This led to Poincare forever being designated as the Father of Chaos Theory since he laid the groundwork on the most important element in chaos theory which is the sensitivity to initial dependence.

In the early 1960’s, the first true experimenter in chaos was a meteorologist named Edward Lorenz. He was working on a problem in weather prediction and he set up a system with twelve equations to model the weather. He set the initial conditions and the computer was left to predict what the weather might be. Upon revisiting this sequence later on, he inadvertently and by sheer accident, decided to run the sequence again in the middle and he noticed that the outcome was significantly different. The imminent question that followed was why the outcome was so different than the original. He traced this back to the initial condition wherein he noted that the initial input was different with respect to the decimal places. The system incorporated the all of the decimal places rather than the first three. (He had originally input the number .506 and he had concatenated the number from .506127). He would have expected that this thin variation in input would have created a sequence close to the original sequence but that was not to be: it was distinctly and hugely different. This effect became known as the Butterfly effect which is often substituted for Chaos Theory. Ian Stewart in his book, Does God Play Dice? The Mathematics of Chaos, describes this visually as follows:

“The flapping of a single butterfly’s wing today produces a tiny change in the state of the atmosphere. Over a period of time, what the atmosphere actually does diverges from what it would have done. So, in a month’s time, a tornado that would have devastated the Indonesian cost doesn’t happen. Or maybe one that wasn’t going to happen, does.”
Lorenz thus argued that it would be impossible to predict the weather accurately. However, he reduced his experiment to fewer set of equations and took upon observations of how small change in initial conditions affect predictability of smaller systems. He found a parallel – namely, that changes in initial conditions tends to render the final outcome of a system to be inaccurate. As he looked at alternative systems, he found a strange pattern that emerged – namely, that the system always represented a double spiral – the system never settled down to a single point but they never repeated its trajectory. It was a path breaking discovery that led to further advancement in the science of chaos in later years.
Years later, Robert May investigated how this impacts population. He established an equation that reflected a population growth and initialized the equation with a parameter for growth rate value. (The growth rate was initialized to 2.7). May found that as he increased the parameter value, the population grew which was expected. However, once he passed the 3.0 growth value, he noticed that equation would not settle down to a single population but branch out to two different values over time. If he raised the initial value more, the bifurcation or branching of the population would be twice as much or four different values. If he continued to increase the parameter, the lines continue to double until chaos appeared and it became hard to make point predictions.
There was another innate discovery that occurred through the experiment. When one visually looks at the bifurcation, one tends to see similarity between the small and large branches. This self-similarity became an important part of the development of chaos theory.
Benoit Mandelbrot started to study this self-similarity pattern in chaos. He was an economist and he applied mathematical equations to predict fluctuations in cotton prices. He noted that particular price changes were not predictable but there were certain patterns that were repeated and the degree of variation in prices had remained largely constant. This is suggestive of the fact that one might, upon preliminary reading of chaos, arrive at the notion that if weather cannot be predictable, then how can we predict climate many years out. On the contrary, Mandelbrot’s experiments seem to suggest that short time horizons are difficult to predict that long time horizon impact since systems tend to settle into some patterns that is reflecting of smaller patterns across periods. This led to the development of the concept of fractal dimensions, namely that sub-systems develop a symmetry to a larger system.
Feigenbaum was a scientist who became interested in how quickly bifurcations occur. He discovered that regardless of the scale of the system, the came at a constant rate of 4.669. If you reduce or enlarge the scale by that constant, you would see the mechanics at work which would lead to an equivalence in self-similarity. He applied this to a number of models and the same scaling constant took effect. Feigenbaum had established, for the first time, a universal constant around chaos theory. This was important because finding a constant in the realm of chaos theory was suggestive of the fact that chaos was an ordered process, not a random one.
Sir James Lighthill gave a lecture and in that he made an astute observation –
“We are all deeply conscious today that the enthusiasm of our forebears for the marvelous achievements of Newtonian mechanics led them to make generalizations in this area of predictability which, indeed, we may have generally tended to believe before 1960, but which we now recognize were false. We collectively wish to apologize for having misled the general educated public by spreading ideas about determinism of systems satisfying Newton’s laws of motion that, after 1960, were to be proved incorrect.”

Distribution Economics
Distribution is a method to get products and services to the maximum number of customers efficiently.
Complexity science is the study of complex systems and the problems that are multi-dimensional, dynamic and unpredictable. It constitutes a set of interconnected relationships that are not always abiding to the laws of cause and effect, but rather the modality of non-linearity. Thomas Kuhn in his pivotal essay: The Structure of Scientific Revolutions posits that anomalies that arise in scientific method rise to the level where it can no longer be put on hold or simmer on a back-burner: rather, those anomalies become the front line for new methods and inquiries such that a new paradigm necessarily must emerge to supplant the old conversations. It is this that lays the foundation of scientific revolution – an emergence that occurs in an ocean of seeming paradoxes and competing theories. Contrary to a simple scientific method that seeks to surface regularities in natural phenomenon, complexity science studies the effects that rules have on agents. Rules do not drive systems toward a predictable outcome: rather it sets into motion a high density of interactions among agents such that the system coalesces around a purpose: that being necessarily that of survival in context of its immediate environment. In addition, the learnings that follow to arrive at the outcome is then replicated over periods to ensure that the systems mutate to changes in the external environment. In theory, the generative rules leads to emergent behavior that displays patterns of parallelism to earlier known structures.
For any system to survive and flourish, distribution of information, noise and signals in and outside of a CPS or CAS is critical. We have touched at length that the system comprises actors and agents that work cohesively together to fulfill a special purpose. Specialization and scale matter! How is a system enabled to fulfill their purpose and arrive at a scale that ensures long-term sustenance? Hence the discussion on distribution and scale which is a salient factor in emergence of complex systems that provide the inherent moat of “defensibility” against internal and external agents working against it.
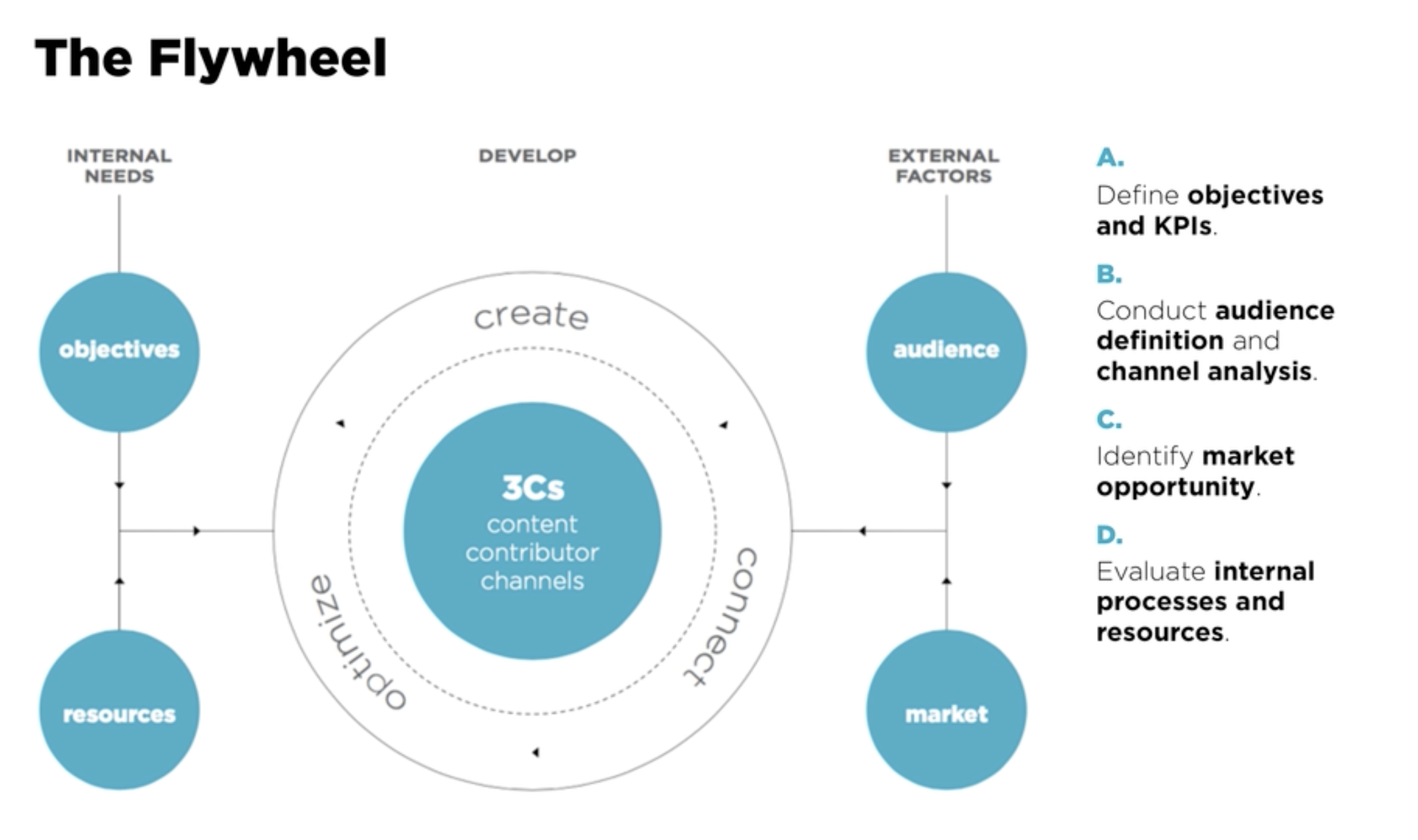
Distribution, in this context, refers to the quality and speed of information processing in the system. It is either created by a set of rules that govern the tie-ups between the constituent elements in the system or it emerges based on a spontaneous evolution of communication protocols that are established in response to internal and external stimuli. It takes into account the available resources in the system or it sets up the demands on resource requirements. Distribution capabilities have to be effective and depending upon the dynamics of external systems, these capabilities might have to be modified effectively. Some distribution systems have to be optimized or organized around efficiency: namely, the ability of the system to distribute information efficiently. On the other hand, some environments might call for less efficiency as the key parameter, but rather focus on establishing a scale – an escape velocity in size and interaction such that the system can dominate the influence of external environments. The choice between efficiency and size is framed by the long-term purpose of the system while also accounting for the exigencies of ebbs and flows of external agents that might threaten the system’s existence.

Since all systems are subject to the laws of entropy and the impact of unintended consequences, strategies have to be orchestrated accordingly. While it is always naïve to assume exactitude in the ultimate impact of rules and behavior, one would surmise that such systems have to be built around the fault lines of multiple roles for agents or group of agents to ensure that the system is being nudged, more than less, toward the desired outcome. Hence, distribution strategy is the aggregate impact of several types of channels of information that are actively working toward a common goal. The idea is to establish multiple channels that invoke different strategies while not cannibalizing or sabotaging an existing set of channels. These mutual exclusive channels have inherent properties that are distinguished by the capacity and length of the channels, the corresponding resources that the channels use and the sheer ability to chaperone the system toward the overall purpose.
The complexity of the purpose and the external environment determines the strategies deployed and whether scale or efficiency are the key barometers for success. If a complex system must survive and hopefully replicate from strength to greater strength over time, size becomes more paramount than efficiency. Size makes up for the increased entropy which is the default tax on the system, and it also increases the possibility of the system to reach the escape velocity. To that end, managing for scale by compromising efficiency is a perfectly acceptable means since one is looking at the system with a long-term lens with built-in regeneration capabilities. However, not all systems might fall in this category because some environments are so dynamic that planning toward a long-term stability is not practical, and thus one has to quickly optimize for increased efficiency. It is thus obvious that scale versus efficiency involves risky bets around how the external environment will evolve. We have looked at how the systems interact with external environments: yet, it is just as important to understand how the actors work internally in a system that is pressed toward scale than efficiency, or vice versa. If the objective is to work toward efficiency, then capabilities can be ephemeral: one builds out agents and actors with capabilities that are mission-specific. On the contrary, scale driven systems demand capabilities that involve increased multi-tasking abilities, the ability to develop and learn from feedback loops, and to prime the constraints with additional resources. Scaling demand acceleration and speed: if a complex system can be devised to distribute information and learning at an accelerating pace, there is a greater likelihood that this system would dominate the environment.
Scaling systems can be approached by adding more agents with varying capabilities. However, increased number of participants exponentially increase the permutations and combinations of channels and that can make the system sluggish. Thus, in establishing the purpose and the subsequent design of the system, it is far more important to establish the rules of engagement. Further, the rules might have some centralized authority that will directionally provide the goal while other rules might be framed in a manner to encourage a pure decentralization of authority such that participants act quickly in groups and clusters to enable execution toward a common purpose.
In business we are surrounded by uncertainty and opportunities. It is how we calibrate around this that ultimately reflects success. The ideal framework at work would be as follows:
- What are the opportunities and what are the corresponding uncertainties associated with the opportunities? An honest evaluation is in order since this is what sets the tone for the strategic framework and direction of the organization.
- Should we be opportunistic and establish rules that allow the system to gear toward quick wins: this would be more inclined toward efficiencies. Or should we pursue dominance by evaluating our internal capability and the probability of winning and displacing other systems that are repositioning in advance or in response to our efforts? At which point, speed and scale become the dominant metric and the resources and capabilities and the set of governing rules have to be aligned accordingly.
- How do we craft multiple channels within and outside of the system? In business lingo, that could translate into sales channels. These channels are selling products and services and can be adding additional value along the way to the existing set of outcomes that the system is engineered for. The more the channels that are mutually exclusive and clearly differentiated by their value propositions, the stronger the system and the greater the ability to scale quickly. These antennas, if you will, also serve to be receptors for new information which will feed data into the organization which can subsequently process and reposition, if the situation so warrants. Having as many differentiated antennas comprise what constitutes the distribution strategy of the organization.
- The final cut is to enable a multi-dimensional loop between external and internal system such that the system expands at an accelerating pace without much intervention or proportionate changes in rules. In other words, system expands autonomously – this is commonly known as the platform effect. Scale does not lead to platform effect although the platform effect most definitely could result in scale. However, scale can be an important contributor to platform effect, and if the latter gets root, then the overall system achieves efficiency and scale in the long run.
Network Theory and Network Effects
Complexity theory needs to be coupled with network theory to get a more comprehensive grasp of the underlying paradigms that govern the outcomes and morphology of emergent systems. In order for us to understand the concept of network effects which is commonly used to understand platform economics or ecosystem value due to positive network externalities, we would like to take a few steps back and appreciate the fundamental theory of networks. This understanding will not only help us to understand complexity and its emergent properties at a low level but also inform us of the impact of this knowledge on how network effects can be shaped to impact outcomes in an intentional manner.

There are first-order conditions that must be met to gauge whether the subject of the observation is a network. Firstly, networks are all about connectivity within and between systems. Understanding the components that bind the system would be helpful. However, do keep in mind that complexity systems (CPS and CAS) might have emergent properties due to the association and connectivity of the network that might not be fully explained by network theory. All the same, understanding networking theory is a building block to understanding emergent systems and the outcome of its structure on addressing niche and macro challenges in society.
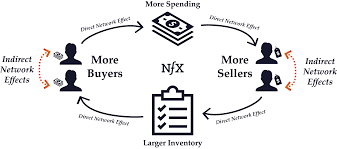
Networks operates spatially in a different space and that has been intentionally done to allow some simplification and subsequent generalization of principles. The geometry of network is called network topology. It is a 2D perspective of connectivity.
Networks are subject to constraints (physical resources, governance constraint, temporal constraints, channel capacity, absorption and diffusion of information, distribution constraint) that might be internal (originated by the system) or external (originated in the environment that the network operates in).

Finally, there is an inherent non-linearity impact in networks. As nodes increase linearly, connections will increase exponentially but might be subject to constraints. The constraints might define how the network structure might morph and how information and signals might be processed differently.
Graph theory is the most widely used tool to study networks. It consists of four parts: vertices which represent an element in the network, edges refer to relationship between nodes which we call links, directionality which refers to how the information is passed ( is it random and bi-directional or follows specific rules and unidirectional), channels that refer to bandwidth that carry information, and finally the boundary which establishes specificity around network operations. A graph can be weighted – namely, a number can be assigned to each length to reflect the degree of interaction or the strength of resources or the proximity of the nodes or the ordering of discernible clusters.
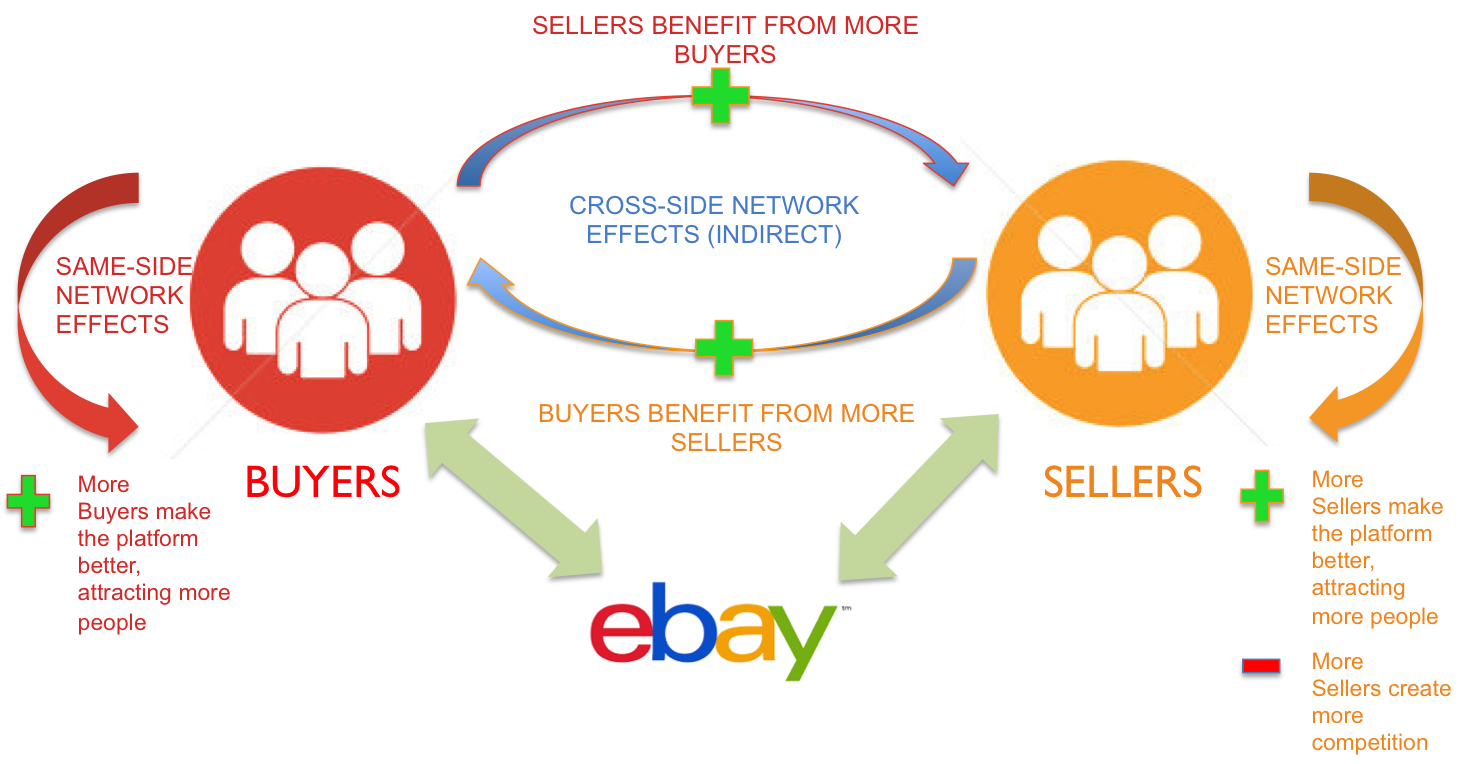
The central concept of network theory thus revolves around connectivity between nodes and how non-linear emergence occurs. A node can have multiple connections with other node/nodes and we can weight the node accordingly. In addition, the purpose of networks is to pass information in the most efficient manner possible which relays into the concept of a geodesic which is either the shortest path between two nodes that must work together to achieve a purpose or the least number of leaps through links that information must negotiate between the nodes in the network.
Technically, you look for the longest path in the network and that constitutes the diameter while you calculate the average path length by examining the shortest path between nodes, adding all of those paths up and then dividing by the number of pairs. Significance of understanding the geodesic allows an understanding of the size of the network and throughput power that the network is capable of.
Nodes are the atomic elements in the network. It is presumed that its degree of significance is related to greater number of connections. There are other factors that are important considerations: how adjacent or close are the nodes to one another, does some nodes have authority or remarkable influence on others, are nodes positioned to be a connector between other nodes, and how capable are the nodes in absorbing, processing and diffusing the information across the links or channels. How difficult is it for the agents or nodes in the network to make connections? It is presumed that if the density of the network is increased, then we create a propensity in the overall network system to increase the potential for increased connectivity.

As discussed previously, our understanding of the network is deeper once we understand the elements well. The structure or network topology is represented by the graph and then we must understand size of network and the patterns that are manifested in the visual depiction of the network. Patterns, for our purposes, might refer to clusters of nodes that are tribal or share geographical proximity that self-organize and thus influence the structure of the network. We will introduce a new term homophily where agents connect with those like themselves. This attribute presumably allows less resources needed to process information and diffuse outcomes within the cluster. Most networks have a cluster bias: in other words, there are areas where there is increased activity or increased homogeneity in attributes or some form of metric that enshrines a group of agents under one specific set of values or activities. Understanding the distribution of cluster and the cluster bias makes it easier to influence how to propagate or even dismantle the network. This leads to an interesting question: Can a network that emerges spontaneously from the informal connectedness between agents be subjected to some high dominance coefficient – namely, could there be nodes or links that might exercise significant weight on the network?
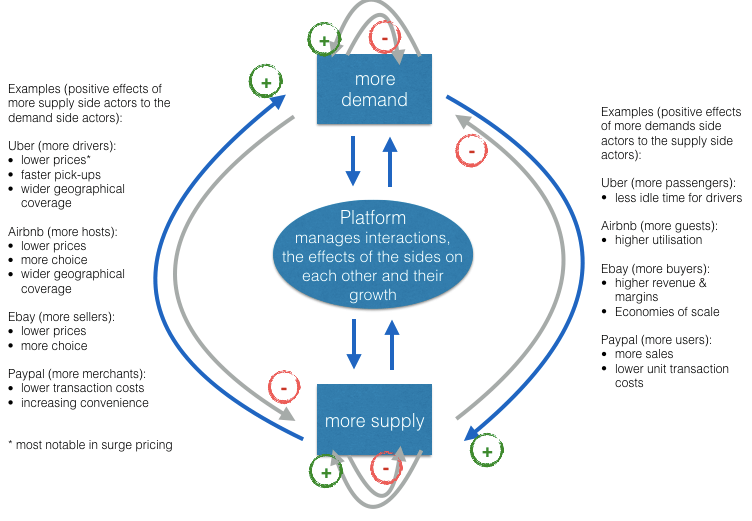
The network has to align to its environment. The environment can place constraints on the network. In some instances, the agents have to figure out how to overcome or optimize their purpose in the context of the presence of the environmental constraints. There is literature that suggests the existence of random networks which might be an initial state, but it is widely agreed that these random networks self-organize around their purpose and their interaction with its environment. Network theory assigns a number to the degree of distribution which means that all or most nodes have an equivalent degree of connectivity and there is no skewed influence being weighed on the network by a node or a cluster. Low numbers assigned to the degree of distribution suggest a network that is very democratic versus high number that suggests centralization. To get a more practical sense, a mid-range number assigned to a network constitutes a decentralized network which has close affinities and not fully random. We have heard of the six degrees of separation and that linkage or affinity is most closely tied to a mid-number assignment to the network.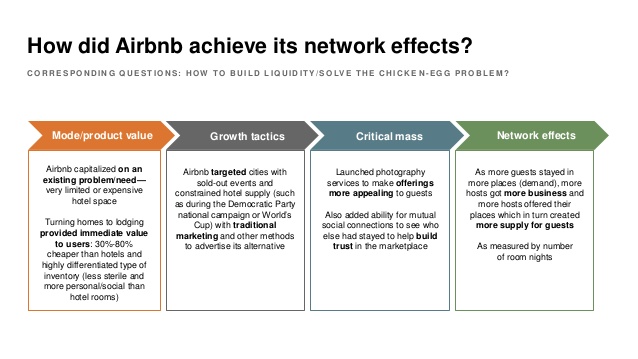
We are now getting into discussions on scale and binding this with network theory. Metcalfe’s law states that the value of a network grows as a square of the number of the nodes in the network. More people join the network, the more valuable the network. Essentially, there is a feedback loop that is created, and this feedback loop can kindle a network to grow exponentially. There are two other topics – Contagion and Resilience. Contagion refers to the ability of the agents to diffuse information. This information can grow the network or dismantle it. Resilience refers to how the network is organized to preserve its structure. As you can imagine, they have huge implications that we see. How do certain ideas proliferate over others, how does it cluster and create sub-networks which might grow to become large independent networks and how it creates natural defense mechanisms against self-immolation and destruction?
Network effect is commonly known as externalities in economics. It is an effect that is external to the transaction but influences the transaction. It is the incremental benefit gained by an existing user for each new user that joins the network. There are two types of network effects: Direct network effects and Indirect network effect. Direct network effects are same side effects. The value of a service goes up as the number of users goes up. For example, if more people have phones, it is useful for you to have a phone. The entire value proposition is one-sided. Indirect networks effects are multi-sided. It lends itself to our current thinking around platforms and why smart platforms can exponentially increase the network. The value of the service increases for one user group when a new user group joins the network. Take for example the relationship between credit card banks, merchants and consumers. There are three user groups, and each gather different value from the network of agents that have different roles. If more consumers use credit cards to buy, more merchants will sign up for the credit cards, and as more merchants sign up – more consumers will sign up with the bank to get more credit cards. This would be an example of a multi-sided platform that inherently has multi-sided network effects. The platform inherently gains significant power such that it becomes more valuable for participants in the system to join the network despite the incremental costs associated with joining the network. Platforms that are built upon effective multi-sided network effects grow quickly and are generally sustainable. Having said that, it could be just as easy that a few dominant bad actors in the network can dismantle and unravel the network completely. We often hear of the tipping point: namely, that once the platform reaches a critical mass of users, it would be difficult to dismantle it. That would certainly be true if the agents and services are, in the aggregate, distributed fairly across the network: but it is also possible that new networks creating even more multi-sided network effects could displace an entrenched network. Hence, it is critical that platform owners manage the quality of content and users and continue to look for more opportunities to introduce more user groups to entrench and yet exponentially grow the network.

