Blog Archives
Precision at Scale: How to Grow Without Drowning in Complexity
In business, as in life, scale is seductive. It promises more of the good things—revenue, reach, relevance. But it also invites something less welcome: complexity. And the thing about complexity is that it doesn’t ask for permission before showing up. It simply arrives, unannounced, and tends to stay longer than you’d like.
As we pursue scale, whether by growing teams, expanding into new markets, or launching adjacent product lines, we must ask a question that seems deceptively simple: how do we know we’re scaling the right way? That question is not just philosophical—it’s deeply economic. The right kind of scale brings leverage. The wrong kind brings entropy.

Now, if I’ve learned anything from years of allocating capital, it is this: returns come not just from growth, but from managing the cost and coordination required to sustain that growth. In fact, the most successful enterprises I’ve seen are not the ones that scaled fastest. They’re the ones that scaled precisely. So, let’s get into how one can scale thoughtfully, without overinvesting in capacity, and how to tell when the system you’ve built is either flourishing or faltering.
To begin, one must understand that scale and complexity do not rise in parallel; complexity has a nasty habit of accelerating. A company with two teams might have a handful of communication lines. Add a third team, and you don’t just add more conversations—you add relationships between every new and existing piece. In engineering terms, it’s a combinatorial explosion. In business terms, it’s meetings, misalignment, and missed expectations.
Cities provide a useful analogy. When they grow in population, certain efficiencies appear. Infrastructure per person often decreases, creating cost advantages. But cities also face nonlinear rises in crime, traffic, and disease—all manifestations of unmanaged complexity. The same is true in organizations. The system pays a tax for every additional node, whether that’s a service, a process, or a person. That tax is complexity, and it compounds.
Knowing this, we must invest in capacity like we would invest in capital markets—with restraint and foresight. Most failures in capacity planning stem from either a lack of preparation or an excess of confidence. The goal is to invest not when systems are already breaking, but just before the cracks form. And crucially, to invest no more than necessary to avoid those cracks.
Now, how do we avoid overshooting? I’ve found that the best approach is to treat capacity like runway. You want enough of it to support takeoff, but not so much that you’ve spent your fuel on unused pavement. We achieve this by investing in increments, triggered by observable thresholds. These thresholds should be quantitative and predictive—not merely anecdotal. If your servers are running at 85 percent utilization across sustained peak windows, that might justify additional infrastructure. If your engineering lead time starts rising despite team growth, it suggests friction has entered the system. Either way, what you’re watching for is not growth alone, but whether the system continues to behave elegantly under that growth.
Elegance matters. Systems that age well are modular, not monolithic. In software, this might mean microservices that scale independently. In operations, it might mean regional pods that carry their own load, instead of relying on a centralized command. Modular systems permit what I call “selective scaling”—adding capacity where needed, without inflating everything else. It’s like building a house where you can add another bedroom without having to reinforce the foundation. That kind of flexibility is worth gold.
Of course, any good decision needs a reliable forecast behind it. But forecasting is not about nailing the future to a decimal point. It is about bounding uncertainty. When evaluating whether to scale, I prefer forecasts that offer a range—base, best, and worst-case scenarios—and then tie investment decisions to the 75th percentile of demand. This ensures you’re covering plausible upside without betting on the moon.
Let’s not forget, however, that systems are only as good as the signals they emit. I’m wary of organizations that rely solely on lagging indicators like revenue or margin. These are important, but they are often the last to move. Leading indicators—cycle time, error rates, customer friction, engineer throughput—tell you much sooner whether your system is straining. In fact, I would argue that latency, broadly defined, is one of the clearest signs of stress. Latency in delivery. Latency in decisions. Latency in feedback. These are the early whispers before systems start to crack.
To measure whether we’re making good decisions, we need to ask not just if outcomes are improving, but if the effort to achieve them is becoming more predictable. Systems with high variability are harder to scale because they demand constant oversight. That’s a recipe for executive burnout and organizational drift. On the other hand, systems that produce consistent results with declining variance signal that the business is not just growing—it’s maturing.
Still, even the best forecasts and the finest metrics won’t help if you lack the discipline to say no. I’ve often told my teams that the most underrated skill in growth is the ability to stop. Stopping doesn’t mean failure; it means the wisdom to avoid doubling down when the signals aren’t there. This is where board oversight matters. Just as we wouldn’t pour more capital into an underperforming asset without a turn-around plan, we shouldn’t scale systems that aren’t showing clear returns.
So when do we stop? There are a few flags I look for. The first is what I call capacity waste—resources allocated but underused, like a datacenter running at 20 percent utilization, or a support team waiting for tickets that never come. That’s not readiness. That’s idle cost. The second flag is declining quality. If error rates, customer complaints, or rework spike following a scale-up, then your complexity is outpacing your coordination. Third, I pay attention to cognitive load. When decision-making becomes a game of email chains and meeting marathons, it’s time to question whether you’ve created a machine that’s too complicated to steer.
There’s also the budget creep test. If your capacity spending increases by more than 10 percent quarter over quarter without corresponding growth in throughput, you’re not scaling—you’re inflating. And in inflation, as in business, value gets diluted.
One way to guard against this is by treating architectural reserves like financial ones. You wouldn’t deploy your full cash reserve just because an opportunity looks interesting. You’d wait for evidence. Similarly, system buffers should be sized relative to forecast volatility, not organizational ambition. A modest buffer is prudent. An oversized one is expensive insurance.
Some companies fall into the trap of building for the market they hope to serve, not the one they actually have. They build as if the future were guaranteed. But the future rarely offers such certainty. A better strategy is to let the market pull capacity from you. When customers stretch your systems, then you invest. Not because it’s a bet, but because it’s a reaction to real demand.
There’s a final point worth making here. Scaling decisions are not one-time events. They are sequences of bets, each informed by updated evidence. You must remain agile enough to revise the plan. Quarterly evaluations, architectural reviews, and scenario testing are the boardroom equivalent of course correction. Just as pilots adjust mid-flight, companies must recalibrate as assumptions evolve.
To bring this down to earth, let me share a brief story. A fintech platform I advised once found itself growing at 80 percent quarter over quarter. Flush with success, they expanded their server infrastructure by 200 percent in a single quarter. For a while, it worked. But then something odd happened. Performance didn’t improve. Latency rose. Error rates jumped. Why? Because they hadn’t scaled the right parts. The orchestration layer, not the compute layer, was the bottleneck. Their added capacity actually increased system complexity without solving the real issue. It took a re-architecture, and six months of disciplined rework, to get things back on track. The lesson: scaling the wrong node is worse than not scaling at all.
In conclusion, scale is not the enemy. But ungoverned scale is. The real challenge is not growth, but precision. Knowing when to add, where to reinforce, and—perhaps most crucially—when to stop. If we build systems with care, monitor them with discipline, and remain intellectually honest about what’s working, we give ourselves the best chance to grow not just bigger, but better.
And that, to borrow a phrase from capital markets, is how you compound wisely.
Internal versus External Scale
This article discusses internal and external complexity before we tee up a more detailed discussion on internal versus external scale. This chapter acknowledges that complex adaptive systems have inherent internal and external complexities which are not additive. The impact of these complexities is exponential. Hence, we have to sift through our understanding and perhaps even review the salient aspects of complexity science which have already been covered in relatively more detail in earlier chapter. However, revisiting complexity science is important, and we will often revisit this across other blog posts to really hit home the fundamental concepts and its practical implications as it relates to management and solving challenges at a business or even a grander social scale.

A complex system is a part of a larger environment. It is a safe to say that the larger environment is more complex than the system itself. But for the complex system to work, it needs to depend upon a certain level of predictability and regularity between the impact of initial state and the events associated with it or the interaction of the variables in the system itself. Note that I am covering both – complex physical systems and complex adaptive systems in this discussion. A system within an environment has an important attribute: it serves as a receptor to signals of external variables of the environment that impact the system. The system will either process that signal or discard the signal which is largely based on what the system is trying to achieve. We will dedicate an entire article on system engineering and thinking later, but the uber point is that a system exists to serve a definite purpose. All systems are dependent on resources and exhibits a certain capacity to process information. Hence, a system will try to extract as many regularities as possible to enable a predictable dynamic in an efficient manner to fulfill its higher-level purpose.
Let us understand external complexities. We can interchangeably use the word environmental complexity as well. External complexity represents physical, cultural, social, and technological elements that are intertwined. These environments beleaguered with its own grades of complexity acts as a mold to affect operating systems that are mere artifacts. If operating systems can fit well within the mold, then there is a measure of fitness or harmony that arises between an internal complexity and external complexity. This is the root of dynamic adaptation. When external environments are very complex, that means that there are a lot of variables at play and thus, an internal system has to process more information in order to survive. So how the internal system will react to external systems is important and they key bridge between those two systems is in learning. Does the system learn and improve outcomes on account of continuous learning and does it continually modify its existing form and functional objectives as it learns from external complexity? How is the feedback loop monitored and managed when one deals with internal and external complexities? The environment generates random problems and challenges and the internal system has to accept or discard these problems and then establish a process to distribute the problems among its agents to efficiently solve those problems that it hopes to solve for. There is always a mechanism at work which tries to align the internal complexity with external complexity since it is widely believed that the ability to efficiently align the systems is the key to maintaining a relatively competitive edge or intentionally making progress in solving a set of important challenges.
Internal complexity are sub-elements that interact and are constituents of a system that resides within the larger context of an external complex system or the environment. Internal complexity arises based on the number of variables in the system, the hierarchical complexity of the variables, the internal capabilities of information pass-through between the levels and the variables, and finally how it learns from the external environment. There are five dimensions of complexity: interdependence, diversity of system elements, unpredictability and ambiguity, the rate of dynamic mobility and adaptability, and the capability of the agents to process information and their individual channel capacities.

If we are discussing scale management, we need to ask a fundamental question. What is scale in the context of complex systems? Why do we manage for scale? How does management for scale advance us toward a meaningful outcome? How does scale compute in internal and external complex systems? What do we expect to see if we have managed for scale well? What does the future bode for us if we assume that we have optimized for scale and that is the key objective function that we have to pursue?
Scaling Considerations in Complex Systems and Organizations: Implications
Scale represents size. In a two-dimensional world, it is a linear measurement that presents a nominal ordering of numbers. In other words, 4 is two times two and 6 would be 3 times two. In other words, the difference between 4 and 6 represents an increase in scale by two. We will discuss various aspects of scale and the learnings that we can draw from it. However, before we go down this path, we would like to touch on resource consumption.

As living organisms, we consume resources. An average human being requires 2000 calories of food per day to sustain themselves. An average human being, by the way, is largely defined in terms of size. So it would be better put if we say that a 200lb person would require 2000 calories. However, if we were to regard a specimen that is 10X the size or 2000 lbs., would it require 10X the calories to sustain itself? Conversely, if the specimen was 1/100th the size of the average human being, then would it require 1/100th the calories to sustain itself. Thus, will we consume resources linearly to our size? Are we operating in a simple linear world? And if not, what are the ramifications for science, physics, biology, organizations, cities, climate, etc.?
Let us digress a little bit from the above questions and lay out a few interesting facts. Almost half of the population in the world today live in cities. This is compared to less than 15% of the world population that lived in cities a hundred years ago. It is anticipated that almost 75% of the world population will be living in cities by 2050. The number of cities will increase and so will the size. But for cities to increase in size and numbers, it requires vast amount of resources. In fact, the resource requirements in cities are far more extensive than in agrarian societies. If there is a limit to the resources from a natural standpoint – in other words, if the world is operating on a budget of natural resources – then would this mean that the growth of the cities will be naturally reined in? Will cities collapse because of lack of resources to support its mass?
What about companies? Can companies grow infinitely? Is there a natural point where companies might hit their limit beyond which growth would not be possible? Could a company collapse because the amount of resources that is required to sustain the size would be compromised? Are there other factors aside from resource consumption that play into what might cap the growth and hence the size of the company? Are there overriding factors that come into play that would superimpose the size-resource usage equation such that our worries could be safely kept aside? Are cities and companies governed by some sort of metabolic rate that governs the sustenance of life?

Geoffrey West, a theoretical physicist, has touched on a lot of the questions in his book: Scale: The Universal Laws of Growth, Innovation, Sustainability, and the Pace of Life in Organisms, Cities, Economies, and Companies. He says that a person requires about 90W (watts) of energy to survive. That is a light bulb burning in your living room in one day. That is our metabolic rate. However, just like man does not live by bread alone, an average man has to depend on a number of other artifacts that have agglomerated in bits and pieces to provide a quality of life to maximize sustenance. The person has to have laws, electricity, fuel, automobile, plumbing and water, markets, banks, clothes, phones and engage with other folks in a complex social network to collaborate and compete to achieve their goals. Geoffrey West says that the average person requires almost 11000W or the equivalent of almost 125 90W light bulbs. To put things in greater perspective, the social metabolic rate of 11,000W is almost equivalent to a dozen elephants. (An elephant requires 10X more energy than humans even though they might be 60X the size of the physical human being). Thus, a major portion of our energy is diverted to maintain the social and physical network that closely interplay to maintain our sustenance. And while we consume massive amounts of energy, we also create a massive amount of waste – and that is an inevitable outcome. This is called the entropy impact and we will touch on this in greater detail in later articles. Hence, our growth is not only constrained by our metabolic rate: it is further dampened by entropy that exists as the Second Law of Thermodynamics. And as a system ages, the impact of entropy increases manifold. Yes, it is true: once we get old, we are racing toward our death at a faster pace than when we were young. Our bodies are exhibiting fatigue faster than normal.
Scaling refers to how a system responds when its size changes. As mentioned earlier, does scaling follow a linear model? Do we need to consume 2X resources if we increase the size by 2X? How does scaling impact a Complex Physical System versus a Complex Adaptive System? Will a 2X impact on the initial state create perturbations in a CPS model which is equivalent to 2X? How would this work on a CAS model where the complexity is far from defined and understood because these systems are continuously evolving? Does half as big requires half as much or conversely twice as big requires twice as much? Once again, I have liberally dipped into this fantastic work by Geoffrey West to summarize, as best as possible, the definitions and implications. He proves that we cannot linearly extrapolate energy consumption and size: the world is smattered with evidence that undermines the linear extrapolation model. In fact, as you grow, you become more efficient with respect to energy consumption. The savings of energy due to growth in size is commonly called the economy of scale. His research also suggests two interesting results. When cities or social systems grow, they require an infrastructure to help with the growth. He discovered that it takes 85% resource consumption to grow the systems by 100%. Thus, there is a savings of 15% which is slightly lower than what has been studied on the biological front wherein organisms save 25% as they grow. He calls this sub linear scaling. In contrast, he also introduces the concept of super linear scaling wherein there is a 15% increasing returns to scale when the city or a social system grows. In other words, if the system grows by 100%, the positive returns with respect to such elements like patents, innovation, etc. will grow by 115%. In addition, the negative elements also grow in an equivalent manner – crime, disease, social unrest, etc. Thus, the growth in cities are supported by an efficient infrastructure that generates increasing returns of good and bad elements.
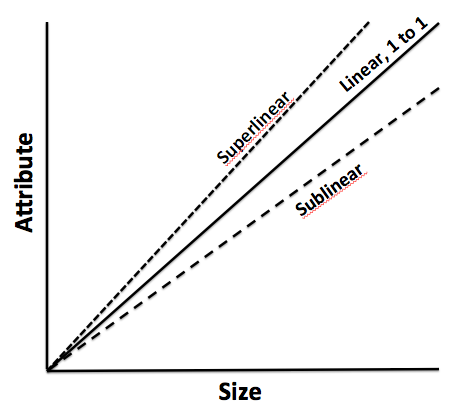
Max Kleiber, a Swiss chemist, in the 1930’s proposed the Kleiber’s law which sheds a lot of light on metabolic rates as energy consumption per unit of time. As mass increases so does the overall metabolic rate but it is not a linear relation – it obeys the power law. It stays that a living organism’s metabolic rate scales to the ¾ power of its mass. If the cat has a mass 100 times that of a mouse, the cat will metabolize about 100 ¾ = 31.63 times more energy per day rather than 100 times more energy per day. Kleiber’s law has led to the metabolic theory of energy and posits that the metabolic rate of organisms is the fundamental biological rate that governs most observed patters in our immediate ecology. There is some ongoing debate on the mechanism that allows metabolic rate to differ based on size. One mechanism is that smaller organisms have higher surface area to volume and thus needs relatively higher energy versus large organisms that have lower surface area to volume. This assumes that energy consumption occurs across surface areas. However, there is another mechanism that argues that energy consumption happens when energy needs are distributed through a transport network that delivers and synthesizes energy. Thus, smaller organisms do not have as a rich a network as large organisms and thus there is greater energy efficiency usage among smaller organisms than larger organisms. Either way, the implications are that body size and temperature (which is a result of internal activity) provide fundamental and natural constraints by which our ecological processes are governed. This leads to another concept called finite time singularity which predicts that unbounded growth cannot be sustained because it would need infinite resources or some K factor that would allow it to increase. The K factor could be innovation, a structural shift in how humans and objects cooperate, or even a matter of jumping on a spaceship and relocating to Mars.
We are getting bigger faster. That is real. The specter of a dystopian future hangs upon us like the sword of Damocles. The thinking is that this rate of growth and scale is not sustainable since it is impossible to marshal the resources to feed the beast in an adequate and timely manner. But interestingly, if we were to dig deeper into history – these thoughts prevailed in earlier times as well but perhaps at different scale. In 1798 Thomas Robert Malthus famously predicted that short-term gains in living standards would inevitably be undermined as human population growth outstripped food production, and thereby drive living standards back toward subsistence. Humanity thus was checkmated into an inevitable conclusion: a veritable collapse spurred by the tendency of population to grow geometrically while food production would increase only arithmetically. Almost two hundred years later, a group of scientists contributed to the 1972 book called Limits to Growth which had similar refrains like Malthus: the population is growing and there are not enough resources to support the growth and that would lead to the collapse of our civilization. However, humanity has negotiated those dark thoughts and we continue to prosper. If indeed, we are governed by this finite time singularity, we are aware that human ingenuity has largely won the day. Technology advancements, policy and institutional changes, new ways of collaboration, etc. have emerged to further delay this “inevitable collapse” that could be result of more mouths to feed than possible. What is true is that the need for new innovative models and new ways of doing things to solve the global challenges wrought by increased population and their correspondent demands will continue to increase at a quicker pace. Once could thus argue that the increased pace of life would not be sustainable. However, that is not a plausible hypothesis based on our assessment of where we are and where we have been.
Let us turn our attention to a business. We want the business to grow or do we want the business to scale? What is the difference? To grow means that your company is adding resources or infrastructure to handle increased demand, at a cost which is equivalent to the level of increased revenue coming in. Scaling occurs when the business is growing faster than the resources that are being consumed. We have already explored that outlier when you grow so big that you are crushed by your weight. It is that fact which limits the growth of organism regardless of issues related to scale. Similarly, one could conceivably argue that there are limits to growth of a company and might even turn to history and show that a lot of large companies of yesteryears have collapsed. However, it is also safe to say that large organizations today are by several factors larger than the largest organizations in the past, and that is largely on account of accumulated knowledge and new forms of innovation and collaboration that have allowed that to happen. In other words, the future bodes well for even larger organizations and if those organizations indeed reach those gargantuan size, it is also safe to draw the conclusion that they will be consuming far less resources relative to current organizations, thus saving more energy and distributing more wealth to the consumers.
Thus, scaling laws limit growth when it assumes that everything else is constant. However, if there is innovation that leads to structural changes of a system, then the limits to growth becomes variable. So how do we effect structural changes? What is the basis? What is the starting point? We look at modeling as a means to arrive at new structures that might allow the systems to be shaped in a manner such that the growth in the systems are not limited by its own constraints of size and motion and temperature (in physics parlance). Thus, a system is modeled at a presumably small scale but with the understanding that as the system is increases in size, the inner workings of emergent complexity could be a problem. Hence, it would be prudent to not linearly extrapolate the model of a small system to that of a large one but rather to exponential extrapolate the complexity of the new system that would emerge. We will discuss this in later articles, but it would be wise to keep this as a mental note as we forge ahead and refine our understanding of scale and its practical implications for our daily consumption.
