Category Archives: growth
Navigating Startup Growth: Adapting Your Operating Model Every Year
If a startup’s journey can be likened to an expedition up Everest, then its operating model is the climbing gear—vital, adaptable, and often revised. In the early stages, founders rely on grit and flexibility. But as companies ascend and attempt to scale, they face a stark and simple truth: yesterday’s systems are rarely fit for tomorrow’s challenges. The premise of this memo is equally stark: your operating model must evolve—consciously and structurally—every 12 months if your company is to scale, thrive, and remain relevant.
This is not a speculative opinion. It is a necessity borne out by economic theory, pattern recognition, operational reality, and the statistical arc of business mortality. According to a 2023 McKinsey report, only 1 in 200 startups make it to $100M in revenue, and even fewer become sustainably profitable. The cliff isn’t due to product failure alone—it’s largely an operational failure to adapt at the right moment. Let’s explore why.
1. The Law of Exponential Complexity
Startups begin with a high signal-to-noise ratio. A few people, one product, and a common purpose. Communication is fluid, decision-making is swift, and adjustments are frequent. But as the team grows from 10 to 50 to 200, each node adds complexity. If you consider the formula for potential communication paths in a group—n(n-1)/2—you’ll find that at 10 employees, there are 45 unique interactions. At 50? That number explodes to 1,225.
This isn’t just theory. Each of those paths represents a potential decision delay, misalignment, or redundancy. Without an intentional redesign of how information flows, how priorities are set, and how accountability is structured, the weight of complexity crushes velocity. An operating model that worked flawlessly in Year 1 becomes a liability in Year 3.
Lesson: The operating model must evolve to actively simplify while the organization expands.
2. The 4 Seasons of Growth
Companies grow in phases, each requiring different operating assumptions. Think of them as seasons:
| Stage | Key Focus | Operating Model Needs |
|---|---|---|
| Start-up | Product-Market Fit | Agile, informal, founder-centric |
| Early Growth | Customer Traction | Lean teams, tight loops, scalable GTM |
| Scale-up | Repeatability | Functional specialization, metrics |
| Expansion | Market Leadership | Cross-functional governance, systems |
At each transition, the company must answer: What must we centralize vs. decentralize? What metrics now matter? Who owns what? A model that optimizes for speed in Year 1 may require guardrails in Year 2. And in Year 3, you may need hierarchy—yes, that dreaded word among startups—to maintain coherence.
Attempting to scale without rethinking the model is akin to flying a Cessna into a hurricane. Many try. Most crash.
3. From Hustle to System: Institutionalizing What Works
Founders often resist operating models because they evoke bureaucracy. But bureaucracy isn’t the issue—entropy is. As the organization grows, systems prevent chaos. A well-crafted operating model does three things:
- Defines governance – who decides what, when, and how.
- Aligns incentives – linking strategy, execution, and rewards.
- Enables measurement – providing real-time feedback on what matters.
Let’s take a practical example. In the early days, a product manager might report directly to the CEO and also collaborate closely with sales. But once you have multiple product lines and a sales org with regional P&Ls, that old model breaks. Now you need Product Ops. You need roadmap arbitration based on capacity planning, not charisma.
Translation: Institutionalize what worked ad hoc by architecting it into systems.
4. Why Every 12 Months? The Velocity Argument
Why not every 24 months? Or every 6? The 12-month cadence is grounded in several interlocking reasons:
- Business cycles: Most companies operate on annual planning rhythms. You set targets, budget resources, and align compensation yearly. The operating model must match that cadence or risk misalignment.
- Cultural absorption: People need time to digest one operating shift before another is introduced. Twelve months is the Goldilocks zone—enough to evaluate results but not too long to become obsolete.
- Market feedback: Every year brings fresh feedback from the market, investors, customers, and competitors. If your operating model doesn’t evolve in step, you’ll lose your edge—like a boxer refusing to switch stances mid-fight.
And then there’s compounding. Like interest on capital, small changes in systems—when made annually—compound dramatically. Optimize decision velocity by 10% annually, and in 5 years, you’ve doubled it. Delay, and you’re crushed by organizational debt.
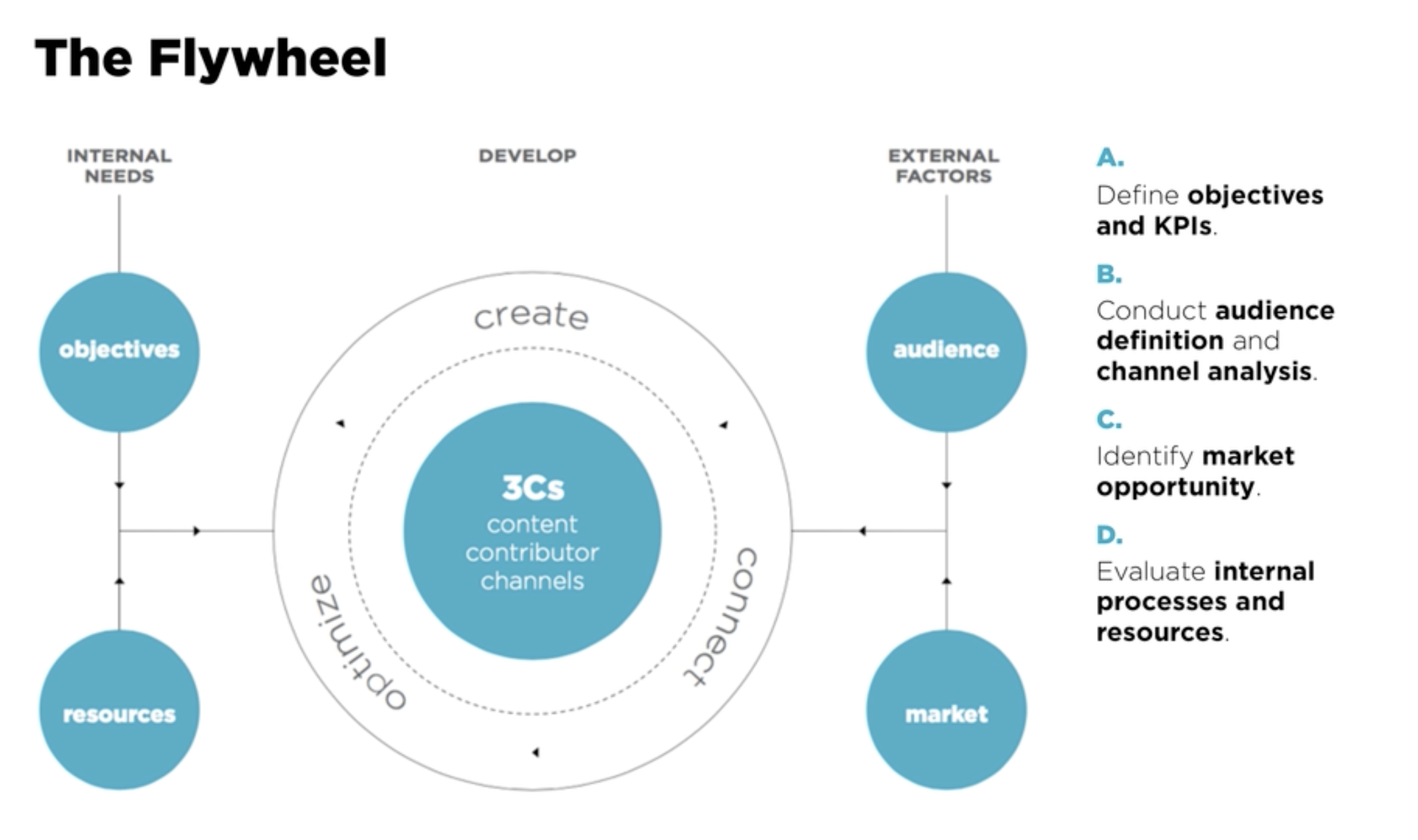
5. The Operating Model Canvas
To guide this evolution, we recommend using a simplified Operating Model Canvas—a strategic tool that captures the six dimensions that must evolve together:
| Dimension | Key Questions |
|---|---|
| Structure | How are teams organized? What’s centralized? |
| Governance | Who decides what? What’s the escalation path? |
| Process | What are the key workflows? How do they scale? |
| People | Do roles align to strategy? How do we manage talent? |
| Technology | What systems support this stage? Where are the gaps? |
| Metrics | Are we measuring what matters now vs. before? |
Reviewing and recalibrating these dimensions annually ensures that the foundation evolves with the building. The alternative is often misalignment, where strategy runs ahead of execution—or worse, vice versa.
6. Case Studies in Motion: Lessons from the Trenches
a. Slack (Pre-acquisition)
In Year 1, Slack’s operating model emphasized velocity of product feedback. Engineers spoke to users directly, releases shipped weekly, and product decisions were founder-led. But by Year 3, with enterprise adoption rising, the model shifted: compliance, enterprise account teams, and customer success became core to the GTM motion. Without adjusting the operating model to support longer sales cycles and regulated customer needs, Slack could not have grown to a $1B+ revenue engine.
b. Airbnb
Initially, Airbnb’s operating rhythm centered on peer-to-peer UX. But as global regulatory scrutiny mounted, they created entirely new policy, legal, and trust & safety functions—none of which were needed in Year 1. Each year, Airbnb re-evaluated what capabilities were now “core” vs. “context.” That discipline allowed them to survive major downturns (like COVID) and rebound.
c. Stripe
Stripe invested heavily in internal tooling as they scaled. Recognizing that developer experience was not only for customers but also internal teams, they revised their internal operating platforms annually—often before they were broken. The result: a company that scaled to serve millions of businesses without succumbing to the chaos that often plagues hypergrowth.
7. The Cost of Inertia
Aging operating models extract a hidden tax. They confuse new hires, slow decisions, demoralize high performers, and inflate costs. Worse, they signal stagnation. In a landscape where capital efficiency is paramount (as underscored in post-2022 venture dynamics), bloated operating models are a death knell.
Consider this: According to Bessemer Venture Partners, top quartile SaaS companies show Rule of 40 compliance with fewer than 300 employees per $100M of ARR. Those that don’t? Often have twice the headcount with half the profitability—trapped in models that no longer fit their stage.
8. How to Operationalize the 12-Month Reset
For practical implementation, I suggest a 12-month Operating Model Review Cycle:
| Month | Focus Area |
|---|---|
| Jan | Strategic planning finalization |
| Feb | Gap analysis of current model |
| Mar | Cross-functional feedback loop |
| Apr | Draft new operating model vNext |
| May | Review with Exec Team |
| Jun | Pilot model changes |
| Jul | Refine and communicate broadly |
| Aug | Train managers on new structures |
| Sep | Integrate into budget planning |
| Oct | Lock model into FY plan |
| Nov | Run simulations/test governance |
| Dec | Prepare for January launch |
This cycle ensures that your org model does not lag behind your strategic ambition. It also sends a powerful cultural signal: we evolve intentionally, not reactively.
Conclusion: Be the Architect, Not the Archaeologist
Every successful company is, at some level, a systems company. Apple is as much about its supply chain as its design. Amazon is a masterclass in operating cadence. And Salesforce didn’t win by having a better CRM—it won by continuously evolving its go-to-market and operating structure.
To scale, you must be the architect of your company’s operating future—not an archaeologist digging up decisions made when the world was simpler.
So I leave you with this conviction: operating models are not carved in stone—they are coded in cycles. And the companies that win are those that rewrite that code every 12 months—with courage, with clarity, and with conviction.
Precision at Scale: How to Grow Without Drowning in Complexity
In business, as in life, scale is seductive. It promises more of the good things—revenue, reach, relevance. But it also invites something less welcome: complexity. And the thing about complexity is that it doesn’t ask for permission before showing up. It simply arrives, unannounced, and tends to stay longer than you’d like.
As we pursue scale, whether by growing teams, expanding into new markets, or launching adjacent product lines, we must ask a question that seems deceptively simple: how do we know we’re scaling the right way? That question is not just philosophical—it’s deeply economic. The right kind of scale brings leverage. The wrong kind brings entropy.

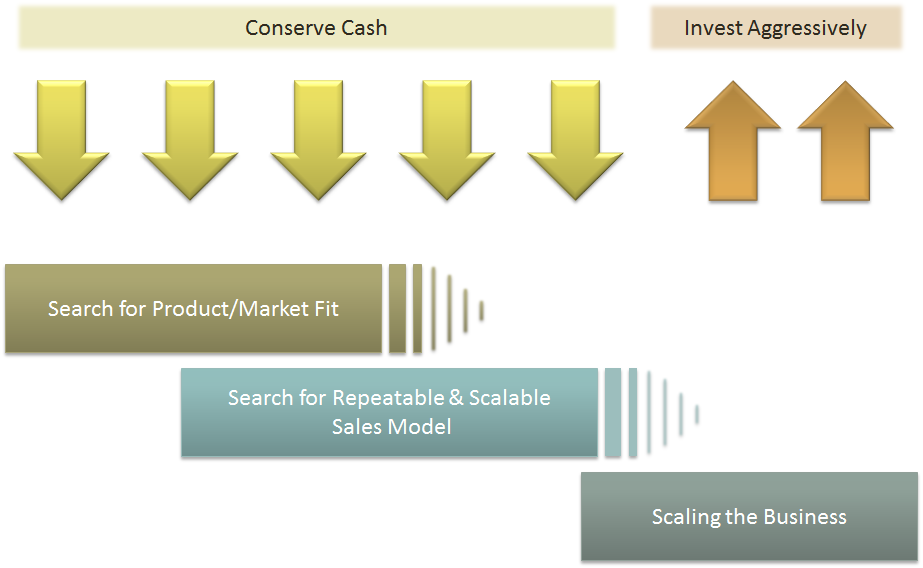
Now, if I’ve learned anything from years of allocating capital, it is this: returns come not just from growth, but from managing the cost and coordination required to sustain that growth. In fact, the most successful enterprises I’ve seen are not the ones that scaled fastest. They’re the ones that scaled precisely. So, let’s get into how one can scale thoughtfully, without overinvesting in capacity, and how to tell when the system you’ve built is either flourishing or faltering.
To begin, one must understand that scale and complexity do not rise in parallel; complexity has a nasty habit of accelerating. A company with two teams might have a handful of communication lines. Add a third team, and you don’t just add more conversations—you add relationships between every new and existing piece. In engineering terms, it’s a combinatorial explosion. In business terms, it’s meetings, misalignment, and missed expectations.
Cities provide a useful analogy. When they grow in population, certain efficiencies appear. Infrastructure per person often decreases, creating cost advantages. But cities also face nonlinear rises in crime, traffic, and disease—all manifestations of unmanaged complexity. The same is true in organizations. The system pays a tax for every additional node, whether that’s a service, a process, or a person. That tax is complexity, and it compounds.
Knowing this, we must invest in capacity like we would invest in capital markets—with restraint and foresight. Most failures in capacity planning stem from either a lack of preparation or an excess of confidence. The goal is to invest not when systems are already breaking, but just before the cracks form. And crucially, to invest no more than necessary to avoid those cracks.
Now, how do we avoid overshooting? I’ve found that the best approach is to treat capacity like runway. You want enough of it to support takeoff, but not so much that you’ve spent your fuel on unused pavement. We achieve this by investing in increments, triggered by observable thresholds. These thresholds should be quantitative and predictive—not merely anecdotal. If your servers are running at 85 percent utilization across sustained peak windows, that might justify additional infrastructure. If your engineering lead time starts rising despite team growth, it suggests friction has entered the system. Either way, what you’re watching for is not growth alone, but whether the system continues to behave elegantly under that growth.
Elegance matters. Systems that age well are modular, not monolithic. In software, this might mean microservices that scale independently. In operations, it might mean regional pods that carry their own load, instead of relying on a centralized command. Modular systems permit what I call “selective scaling”—adding capacity where needed, without inflating everything else. It’s like building a house where you can add another bedroom without having to reinforce the foundation. That kind of flexibility is worth gold.
Of course, any good decision needs a reliable forecast behind it. But forecasting is not about nailing the future to a decimal point. It is about bounding uncertainty. When evaluating whether to scale, I prefer forecasts that offer a range—base, best, and worst-case scenarios—and then tie investment decisions to the 75th percentile of demand. This ensures you’re covering plausible upside without betting on the moon.
Let’s not forget, however, that systems are only as good as the signals they emit. I’m wary of organizations that rely solely on lagging indicators like revenue or margin. These are important, but they are often the last to move. Leading indicators—cycle time, error rates, customer friction, engineer throughput—tell you much sooner whether your system is straining. In fact, I would argue that latency, broadly defined, is one of the clearest signs of stress. Latency in delivery. Latency in decisions. Latency in feedback. These are the early whispers before systems start to crack.
To measure whether we’re making good decisions, we need to ask not just if outcomes are improving, but if the effort to achieve them is becoming more predictable. Systems with high variability are harder to scale because they demand constant oversight. That’s a recipe for executive burnout and organizational drift. On the other hand, systems that produce consistent results with declining variance signal that the business is not just growing—it’s maturing.
Still, even the best forecasts and the finest metrics won’t help if you lack the discipline to say no. I’ve often told my teams that the most underrated skill in growth is the ability to stop. Stopping doesn’t mean failure; it means the wisdom to avoid doubling down when the signals aren’t there. This is where board oversight matters. Just as we wouldn’t pour more capital into an underperforming asset without a turn-around plan, we shouldn’t scale systems that aren’t showing clear returns.
So when do we stop? There are a few flags I look for. The first is what I call capacity waste—resources allocated but underused, like a datacenter running at 20 percent utilization, or a support team waiting for tickets that never come. That’s not readiness. That’s idle cost. The second flag is declining quality. If error rates, customer complaints, or rework spike following a scale-up, then your complexity is outpacing your coordination. Third, I pay attention to cognitive load. When decision-making becomes a game of email chains and meeting marathons, it’s time to question whether you’ve created a machine that’s too complicated to steer.
There’s also the budget creep test. If your capacity spending increases by more than 10 percent quarter over quarter without corresponding growth in throughput, you’re not scaling—you’re inflating. And in inflation, as in business, value gets diluted.
One way to guard against this is by treating architectural reserves like financial ones. You wouldn’t deploy your full cash reserve just because an opportunity looks interesting. You’d wait for evidence. Similarly, system buffers should be sized relative to forecast volatility, not organizational ambition. A modest buffer is prudent. An oversized one is expensive insurance.
Some companies fall into the trap of building for the market they hope to serve, not the one they actually have. They build as if the future were guaranteed. But the future rarely offers such certainty. A better strategy is to let the market pull capacity from you. When customers stretch your systems, then you invest. Not because it’s a bet, but because it’s a reaction to real demand.
There’s a final point worth making here. Scaling decisions are not one-time events. They are sequences of bets, each informed by updated evidence. You must remain agile enough to revise the plan. Quarterly evaluations, architectural reviews, and scenario testing are the boardroom equivalent of course correction. Just as pilots adjust mid-flight, companies must recalibrate as assumptions evolve.
To bring this down to earth, let me share a brief story. A fintech platform I advised once found itself growing at 80 percent quarter over quarter. Flush with success, they expanded their server infrastructure by 200 percent in a single quarter. For a while, it worked. But then something odd happened. Performance didn’t improve. Latency rose. Error rates jumped. Why? Because they hadn’t scaled the right parts. The orchestration layer, not the compute layer, was the bottleneck. Their added capacity actually increased system complexity without solving the real issue. It took a re-architecture, and six months of disciplined rework, to get things back on track. The lesson: scaling the wrong node is worse than not scaling at all.
In conclusion, scale is not the enemy. But ungoverned scale is. The real challenge is not growth, but precision. Knowing when to add, where to reinforce, and—perhaps most crucially—when to stop. If we build systems with care, monitor them with discipline, and remain intellectually honest about what’s working, we give ourselves the best chance to grow not just bigger, but better.
And that, to borrow a phrase from capital markets, is how you compound wisely.
Chaos as a system: New Framework
Chaos is not an unordered phenomenon. There is a certain homeostatic mechanism at play that forces a system that might have inherent characteristics of a “chaotic” process to converge to some sort of stability with respect to predictability and parallelism. Our understanding of order which is deemed to be opposite of chaos is the fact that there is a shared consensus that the system will behave in an expected manner. Hence, we often allude to systems as being “balanced” or “stable” or “in order” to spotlight these systems. However, it is also becoming common knowledge in the science of chaos that slight changes in initial conditions in a system can emit variability in the final output that might not be predictable. So how does one straddle order and chaos in an observed system, and what implications does this process have on ongoing study of such systems?

Chaotic systems can be considered to have a highly complex order. It might require the tools of pure mathematics and extreme computational power to understand such systems. These tools have invariably provided some insights into chaotic systems by visually representing outputs as re-occurrences of a distribution of outputs related to a given set of inputs. Another interesting tie up in this model is the existence of entropy, that variable that taxes a system and diminishes the impact on expected outputs. Any system acts like a living organism: it requires oodles of resources to survive and a well-established set of rules to govern its internal mechanism driving the vector of its movement. Suddenly, what emerges is the fact that chaotic systems display some order while subject to an inherent mechanism that softens its impact over time. Most approaches to studying complex and chaotic systems involve understanding graphical plots of fractal nature, and bifurcation diagrams. These models illustrate very complex re occurrences of outputs directly related to inputs. Hence, complex order occurs from chaotic systems.
A case in point would be the relation of a population parameter in the context to its immediate environment. It is argued that a population in an environment will maintain a certain number and there would be some external forces that will actively work to ensure that the population will maintain at that standard number. It is a very Malthusian analytic, but what is interesting is that there could be some new and meaningful influences on the number that might increase the scale. In our current meaning, a change in technology or ingenuity could significantly alter the natural homeostatic number. The fact remains that forces are always at work on a system. Some systems are autonomic – it self-organizes and corrects itself toward some stable convergence. Other systems are not autonomic and once can only resort to the laws of probability to get some insight into the possible outputs – but never to a point where there is a certainty in predictive prowess.
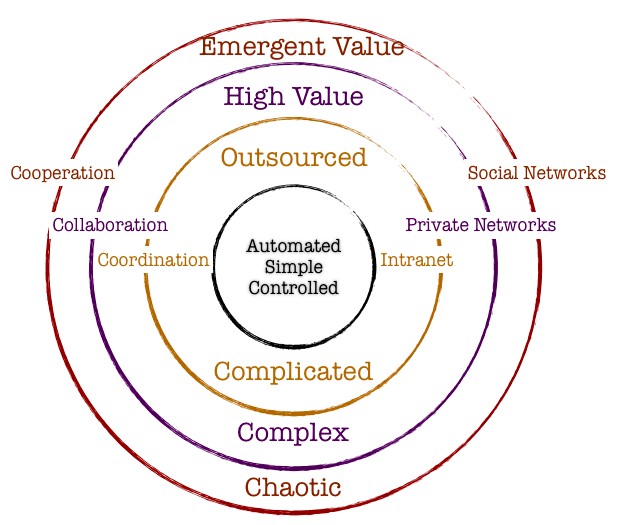
Organizations have a lot of interacting variables at play at any given moment. In order to influence the organization behavior or/and direction, policies might be formulated to bring about the desirable results. However, these nudges toward setting off the organization in the right direction might also lead to unexpected results. The aim is to foresee some of these unexpected results and mollify the adverse consequences while, in parallel, encourage the system to maximize the benefits. So how does one effect such changes?
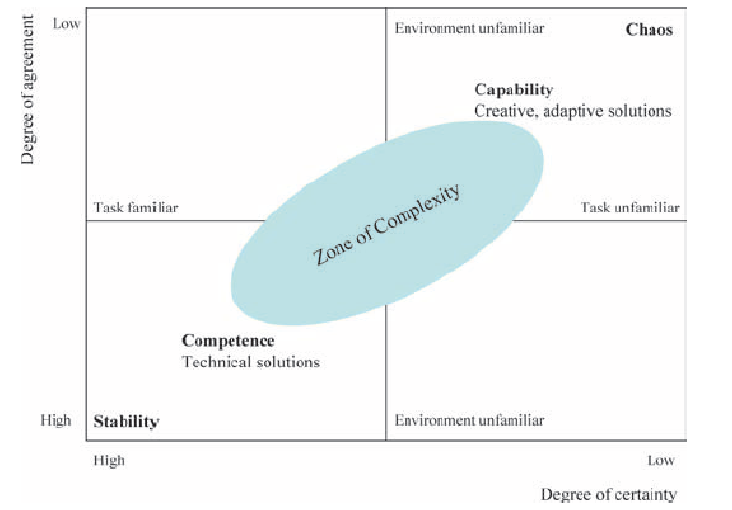
It all starts with building out an operating framework. There needs to be a clarity around goals and what the ultimate purpose of the system is. Thus there are few objectives that bind the framework.
- Clarity around goals and the timing around achieving these goals. If there is no established time parameter, then the system might jump across various states over time and it would be difficult to establish an outcome.
- Evaluate all of the internal and external factors that might operate in the framework that would impact the success of organizational mandates and direction. Identify stasis or potential for stasis early since that mental model could stem the progress toward a desirable impact.
- Apply toll gates strategically to evaluate if the system is proceeding along the lines of expectation, and any early aberrations are evaluated and the rules are tweaked to get the system to track on a desirable trajectory.
- Develop islands of learning across the path and engage the right talent and other parameters to force adaptive learning and therefore a more autonomic direction to the system.
- Bind the agents and actors in the organization to a shared sense of purpose within the parameter of time.
- Introduce diversity into the framework early in the process. The engagement of diversity allows the system to modulate around a harmonic mean.
- Finally, maintain a well document knowledge base such that the accretive learning that results due to changes in the organization become springboard for new initiatives that reduces the costs of potential failures or latency in execution.
- Encouraging the leadership to ensure that the vector is pointed toward the right direction at any given time.
Once a framework and the engagement rules are drawn out, it is necessary to rely on the natural velocity and self-organization of purposeful agents to move the agenda forward, hopefully with little or no intervention. A mechanism of feedback loops along the way would guide the efficacy of the direction of the system. The implications is that the strategy and the operations must be aligned and reevaluated and positive behavior is encouraged to ensure that the systems meets its objective.

However, as noted above, entropy is a dynamic that often threatens to derail the system objective. There will be external or internal forces constantly at work to undermine system velocity. The operating framework needs to anticipate that real possibility and pre-empt that with rules or introduction of specific capital to dematerialize these occurrences. Stasis is an active agent that can work against the system dynamic. Stasis is the inclination of agents or behaviors that anchors the system to some status quo – we have to be mindful that change might not be embraced and if there are resistors to that change, the dynamic of organizational change can be invariably impacted. It will take a lot more to get something done than otherwise needed. Identifying stasis and agents of stasis is a foundational element
While the above is one example of how to manage organizations in the shadows of the properties of how chaotic systems behave, another example would be the formulation of strategy of the organization in responses to external forces. How do we apply our learnings in chaos to deal with the challenges of competitive markets by aligning the internal organization to external factors? One of the key insights that chaos surfaces is that it is nigh impossible for one to fully anticipate all of the external variables, and leaving the system to dynamically adapt organically to external dynamics would allow the organization to thrive. To thrive in this environment is to provide the organization to rapidly change outside of the traditional hierarchical expectations: when organizations are unable to make those rapid changes or make strategic bets in response to the external systems, then the execution value of the organization diminishes.
Margaret Wheatley in her book Leadership and the New Science: Discovering Order in a Chaotic World Revised says, “Organizations lack this kind of faith, faith that they can accomplish their purposes in various ways and that they do best when they focus on direction and vision, letting transient forms emerge and disappear. We seem fixated on structures…and organizations, or we who create them, survive only because we build crafty and smart—smart enough to defend ourselves from the natural forces of destruction. Karl Weick, an organizational theorist, believes that “business strategies should be “just in time…supported by more investment in general knowledge, a large skill repertoire, the ability to do a quick study, trust in intuitions, and sophistication in cutting losses.”
We can expand the notion of a chaos in a system to embrace the bigger challenges associated with environment, globalization, and the advent of disruptive technologies.
One of the key challenges to globalization is how policy makers would balance that out against potential social disintegration. As policies emerge to acknowledge the benefits and the necessity to integrate with a new and dynamic global order, the corresponding impact to local institutions can vary and might even lead to some deleterious impact on those institutions. Policies have to encourage flexibility in local institutional capability and that might mean increased investments in infrastructure, creating a diverse knowledge base, establishing rules that govern free but fair trading practices, and encouraging the mobility of capital across borders. The grand challenges of globalization is weighed upon by government and private entities that scurry to create that continual balance to ensure that the local systems survive and flourish within the context of the larger framework. The boundaries of the system are larger and incorporates many more agents which effectively leads to the real possibility of systems that are difficult to be controlled via a hierarchical or centralized body politic Decision making is thus pushed out to the agents and actors but these work under a larger set of rules. Rigidity in rules and governance can amplify failures in this process.

Related to the realities of globalization is the advent of the growth in exponential technologies. Technologies with extreme computational power is integrating and create robust communication networks within and outside of the system: the system herein could represent nation-states or companies or industrialization initiatives. Will the exponential technologies diffuse across larger scales quickly and will the corresponding increase in adoption of new technologies change the future of the human condition? There are fears that new technologies would displace large groups of economic participants who are not immediately equipped to incorporate and feed those technologies into the future: that might be on account of disparity in education and wealth, institutional policies, and the availability of opportunities. Since technologies are exponential, we get a performance curve that is difficult for us to understand. In general, we tend to think linearly and this frailty in our thinking removes us from the path to the future sooner than later. What makes this difficult is that the exponential impact is occurring across various sciences and no one body can effectively fathom the impact and the direction. Bill Gates says it well “We always overestimate the change that will occur in the next two years and underestimate the change that will occur in the next ten. Don’t let yourself be lulled into inaction.” Does chaos theory and complexity science arm us with a differentiated tool set than the traditional toolset of strategy roadmaps and product maps? If society is being carried by the intractable and power of the exponent in advances in technology, than a linear map might not serve to provide the right framework to develop strategies for success in the long-term. Rather, a more collaborative and transparent roadmap to encourage the integration of thoughts and models among the actors who are adapting and adjusting dynamically by the sheer force of will would perhaps be an alternative and practical approach in the new era.

Lately there has been a lot of discussion around climate change. It has been argued, with good reason and empirical evidence, that environment can be adversely impacted on account of mass industrialization, increase in population, resource availability issues, the inability of the market system to incorporate the cost of spillover effects, the adverse impact of moral hazard and the theory of the commons, etc. While there are demurrers who contest the long-term climate change issues, the train seems to have already left the station! The facts do clearly reflect that the climate will be impacted. Skeptics might argue that science has not yet developed a precise predictive model of the weather system two weeks out, and it is foolhardy to conclude a dystopian future on climate fifty years out. However, the alternative argument is that our inability to exercise to explain the near-term effects of weather changes and turbulence does not negate the existence of climate change due to the accretion of greenhouse impact. Boiling a pot of water will not necessarily gives us an understanding of all of the convection currents involved among the water molecules, but it certainly does not shy away from the fact that the water will heat up.
Distribution Economics
Distribution is a method to get products and services to the maximum number of customers efficiently.
Complexity science is the study of complex systems and the problems that are multi-dimensional, dynamic and unpredictable. It constitutes a set of interconnected relationships that are not always abiding to the laws of cause and effect, but rather the modality of non-linearity. Thomas Kuhn in his pivotal essay: The Structure of Scientific Revolutions posits that anomalies that arise in scientific method rise to the level where it can no longer be put on hold or simmer on a back-burner: rather, those anomalies become the front line for new methods and inquiries such that a new paradigm necessarily must emerge to supplant the old conversations. It is this that lays the foundation of scientific revolution – an emergence that occurs in an ocean of seeming paradoxes and competing theories. Contrary to a simple scientific method that seeks to surface regularities in natural phenomenon, complexity science studies the effects that rules have on agents. Rules do not drive systems toward a predictable outcome: rather it sets into motion a high density of interactions among agents such that the system coalesces around a purpose: that being necessarily that of survival in context of its immediate environment. In addition, the learnings that follow to arrive at the outcome is then replicated over periods to ensure that the systems mutate to changes in the external environment. In theory, the generative rules leads to emergent behavior that displays patterns of parallelism to earlier known structures.
For any system to survive and flourish, distribution of information, noise and signals in and outside of a CPS or CAS is critical. We have touched at length that the system comprises actors and agents that work cohesively together to fulfill a special purpose. Specialization and scale matter! How is a system enabled to fulfill their purpose and arrive at a scale that ensures long-term sustenance? Hence the discussion on distribution and scale which is a salient factor in emergence of complex systems that provide the inherent moat of “defensibility” against internal and external agents working against it.
Distribution, in this context, refers to the quality and speed of information processing in the system. It is either created by a set of rules that govern the tie-ups between the constituent elements in the system or it emerges based on a spontaneous evolution of communication protocols that are established in response to internal and external stimuli. It takes into account the available resources in the system or it sets up the demands on resource requirements. Distribution capabilities have to be effective and depending upon the dynamics of external systems, these capabilities might have to be modified effectively. Some distribution systems have to be optimized or organized around efficiency: namely, the ability of the system to distribute information efficiently. On the other hand, some environments might call for less efficiency as the key parameter, but rather focus on establishing a scale – an escape velocity in size and interaction such that the system can dominate the influence of external environments. The choice between efficiency and size is framed by the long-term purpose of the system while also accounting for the exigencies of ebbs and flows of external agents that might threaten the system’s existence.

Since all systems are subject to the laws of entropy and the impact of unintended consequences, strategies have to be orchestrated accordingly. While it is always naïve to assume exactitude in the ultimate impact of rules and behavior, one would surmise that such systems have to be built around the fault lines of multiple roles for agents or group of agents to ensure that the system is being nudged, more than less, toward the desired outcome. Hence, distribution strategy is the aggregate impact of several types of channels of information that are actively working toward a common goal. The idea is to establish multiple channels that invoke different strategies while not cannibalizing or sabotaging an existing set of channels. These mutual exclusive channels have inherent properties that are distinguished by the capacity and length of the channels, the corresponding resources that the channels use and the sheer ability to chaperone the system toward the overall purpose.
The complexity of the purpose and the external environment determines the strategies deployed and whether scale or efficiency are the key barometers for success. If a complex system must survive and hopefully replicate from strength to greater strength over time, size becomes more paramount than efficiency. Size makes up for the increased entropy which is the default tax on the system, and it also increases the possibility of the system to reach the escape velocity. To that end, managing for scale by compromising efficiency is a perfectly acceptable means since one is looking at the system with a long-term lens with built-in regeneration capabilities. However, not all systems might fall in this category because some environments are so dynamic that planning toward a long-term stability is not practical, and thus one has to quickly optimize for increased efficiency. It is thus obvious that scale versus efficiency involves risky bets around how the external environment will evolve. We have looked at how the systems interact with external environments: yet, it is just as important to understand how the actors work internally in a system that is pressed toward scale than efficiency, or vice versa. If the objective is to work toward efficiency, then capabilities can be ephemeral: one builds out agents and actors with capabilities that are mission-specific. On the contrary, scale driven systems demand capabilities that involve increased multi-tasking abilities, the ability to develop and learn from feedback loops, and to prime the constraints with additional resources. Scaling demand acceleration and speed: if a complex system can be devised to distribute information and learning at an accelerating pace, there is a greater likelihood that this system would dominate the environment.
Scaling systems can be approached by adding more agents with varying capabilities. However, increased number of participants exponentially increase the permutations and combinations of channels and that can make the system sluggish. Thus, in establishing the purpose and the subsequent design of the system, it is far more important to establish the rules of engagement. Further, the rules might have some centralized authority that will directionally provide the goal while other rules might be framed in a manner to encourage a pure decentralization of authority such that participants act quickly in groups and clusters to enable execution toward a common purpose.
In business we are surrounded by uncertainty and opportunities. It is how we calibrate around this that ultimately reflects success. The ideal framework at work would be as follows:
- What are the opportunities and what are the corresponding uncertainties associated with the opportunities? An honest evaluation is in order since this is what sets the tone for the strategic framework and direction of the organization.
- Should we be opportunistic and establish rules that allow the system to gear toward quick wins: this would be more inclined toward efficiencies. Or should we pursue dominance by evaluating our internal capability and the probability of winning and displacing other systems that are repositioning in advance or in response to our efforts? At which point, speed and scale become the dominant metric and the resources and capabilities and the set of governing rules have to be aligned accordingly.
- How do we craft multiple channels within and outside of the system? In business lingo, that could translate into sales channels. These channels are selling products and services and can be adding additional value along the way to the existing set of outcomes that the system is engineered for. The more the channels that are mutually exclusive and clearly differentiated by their value propositions, the stronger the system and the greater the ability to scale quickly. These antennas, if you will, also serve to be receptors for new information which will feed data into the organization which can subsequently process and reposition, if the situation so warrants. Having as many differentiated antennas comprise what constitutes the distribution strategy of the organization.
- The final cut is to enable a multi-dimensional loop between external and internal system such that the system expands at an accelerating pace without much intervention or proportionate changes in rules. In other words, system expands autonomously – this is commonly known as the platform effect. Scale does not lead to platform effect although the platform effect most definitely could result in scale. However, scale can be an important contributor to platform effect, and if the latter gets root, then the overall system achieves efficiency and scale in the long run.
Network Theory and Network Effects
Complexity theory needs to be coupled with network theory to get a more comprehensive grasp of the underlying paradigms that govern the outcomes and morphology of emergent systems. In order for us to understand the concept of network effects which is commonly used to understand platform economics or ecosystem value due to positive network externalities, we would like to take a few steps back and appreciate the fundamental theory of networks. This understanding will not only help us to understand complexity and its emergent properties at a low level but also inform us of the impact of this knowledge on how network effects can be shaped to impact outcomes in an intentional manner.

There are first-order conditions that must be met to gauge whether the subject of the observation is a network. Firstly, networks are all about connectivity within and between systems. Understanding the components that bind the system would be helpful. However, do keep in mind that complexity systems (CPS and CAS) might have emergent properties due to the association and connectivity of the network that might not be fully explained by network theory. All the same, understanding networking theory is a building block to understanding emergent systems and the outcome of its structure on addressing niche and macro challenges in society.
Networks operates spatially in a different space and that has been intentionally done to allow some simplification and subsequent generalization of principles. The geometry of network is called network topology. It is a 2D perspective of connectivity.
Networks are subject to constraints (physical resources, governance constraint, temporal constraints, channel capacity, absorption and diffusion of information, distribution constraint) that might be internal (originated by the system) or external (originated in the environment that the network operates in).

Finally, there is an inherent non-linearity impact in networks. As nodes increase linearly, connections will increase exponentially but might be subject to constraints. The constraints might define how the network structure might morph and how information and signals might be processed differently.
Graph theory is the most widely used tool to study networks. It consists of four parts: vertices which represent an element in the network, edges refer to relationship between nodes which we call links, directionality which refers to how the information is passed ( is it random and bi-directional or follows specific rules and unidirectional), channels that refer to bandwidth that carry information, and finally the boundary which establishes specificity around network operations. A graph can be weighted – namely, a number can be assigned to each length to reflect the degree of interaction or the strength of resources or the proximity of the nodes or the ordering of discernible clusters.
The central concept of network theory thus revolves around connectivity between nodes and how non-linear emergence occurs. A node can have multiple connections with other node/nodes and we can weight the node accordingly. In addition, the purpose of networks is to pass information in the most efficient manner possible which relays into the concept of a geodesic which is either the shortest path between two nodes that must work together to achieve a purpose or the least number of leaps through links that information must negotiate between the nodes in the network.
Technically, you look for the longest path in the network and that constitutes the diameter while you calculate the average path length by examining the shortest path between nodes, adding all of those paths up and then dividing by the number of pairs. Significance of understanding the geodesic allows an understanding of the size of the network and throughput power that the network is capable of.
Nodes are the atomic elements in the network. It is presumed that its degree of significance is related to greater number of connections. There are other factors that are important considerations: how adjacent or close are the nodes to one another, does some nodes have authority or remarkable influence on others, are nodes positioned to be a connector between other nodes, and how capable are the nodes in absorbing, processing and diffusing the information across the links or channels. How difficult is it for the agents or nodes in the network to make connections? It is presumed that if the density of the network is increased, then we create a propensity in the overall network system to increase the potential for increased connectivity.

As discussed previously, our understanding of the network is deeper once we understand the elements well. The structure or network topology is represented by the graph and then we must understand size of network and the patterns that are manifested in the visual depiction of the network. Patterns, for our purposes, might refer to clusters of nodes that are tribal or share geographical proximity that self-organize and thus influence the structure of the network. We will introduce a new term homophily where agents connect with those like themselves. This attribute presumably allows less resources needed to process information and diffuse outcomes within the cluster. Most networks have a cluster bias: in other words, there are areas where there is increased activity or increased homogeneity in attributes or some form of metric that enshrines a group of agents under one specific set of values or activities. Understanding the distribution of cluster and the cluster bias makes it easier to influence how to propagate or even dismantle the network. This leads to an interesting question: Can a network that emerges spontaneously from the informal connectedness between agents be subjected to some high dominance coefficient – namely, could there be nodes or links that might exercise significant weight on the network?
The network has to align to its environment. The environment can place constraints on the network. In some instances, the agents have to figure out how to overcome or optimize their purpose in the context of the presence of the environmental constraints. There is literature that suggests the existence of random networks which might be an initial state, but it is widely agreed that these random networks self-organize around their purpose and their interaction with its environment. Network theory assigns a number to the degree of distribution which means that all or most nodes have an equivalent degree of connectivity and there is no skewed influence being weighed on the network by a node or a cluster. Low numbers assigned to the degree of distribution suggest a network that is very democratic versus high number that suggests centralization. To get a more practical sense, a mid-range number assigned to a network constitutes a decentralized network which has close affinities and not fully random. We have heard of the six degrees of separation and that linkage or affinity is most closely tied to a mid-number assignment to the network.
We are now getting into discussions on scale and binding this with network theory. Metcalfe’s law states that the value of a network grows as a square of the number of the nodes in the network. More people join the network, the more valuable the network. Essentially, there is a feedback loop that is created, and this feedback loop can kindle a network to grow exponentially. There are two other topics – Contagion and Resilience. Contagion refers to the ability of the agents to diffuse information. This information can grow the network or dismantle it. Resilience refers to how the network is organized to preserve its structure. As you can imagine, they have huge implications that we see. How do certain ideas proliferate over others, how does it cluster and create sub-networks which might grow to become large independent networks and how it creates natural defense mechanisms against self-immolation and destruction?
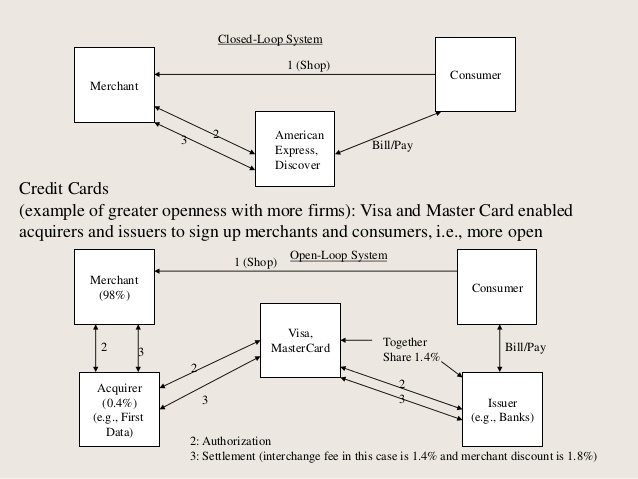
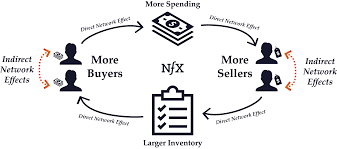
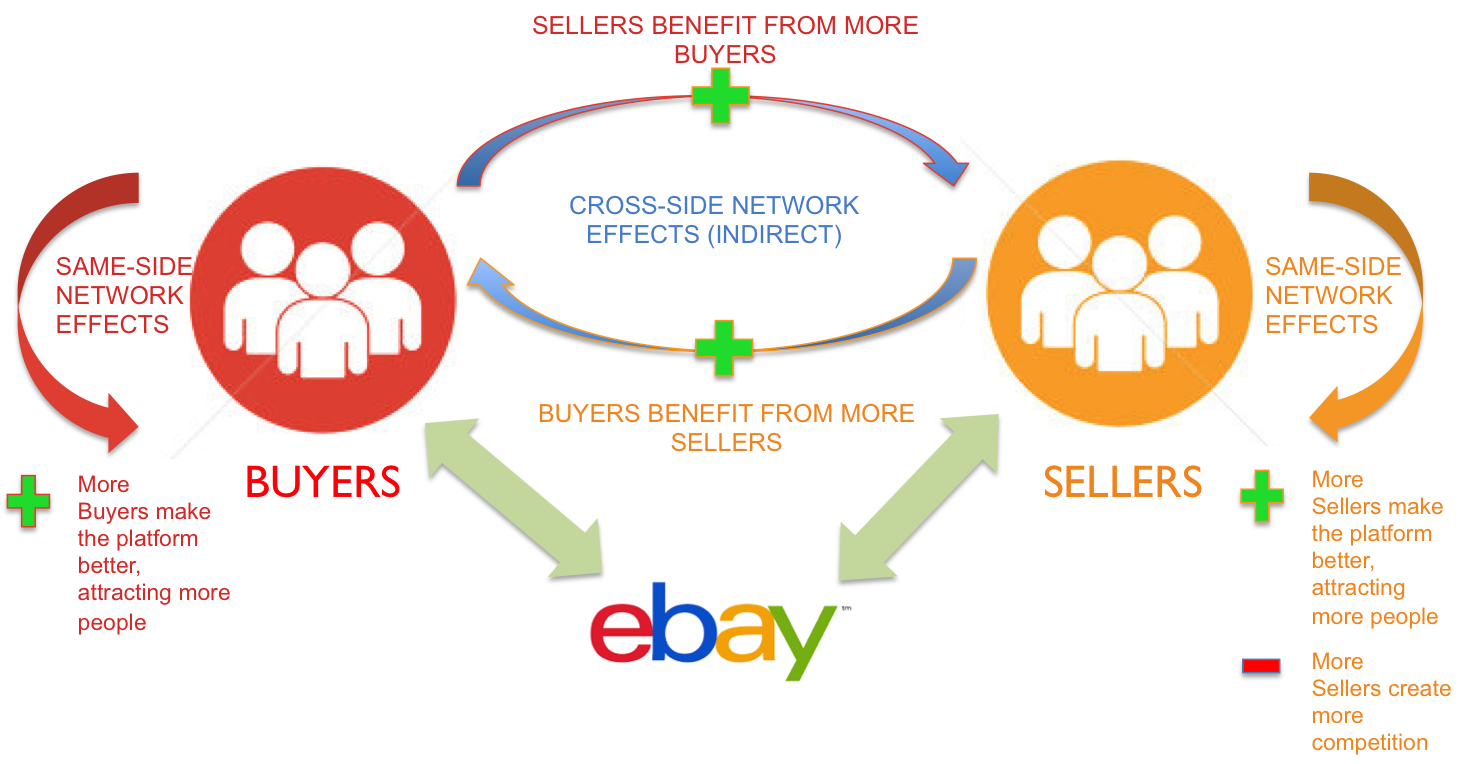
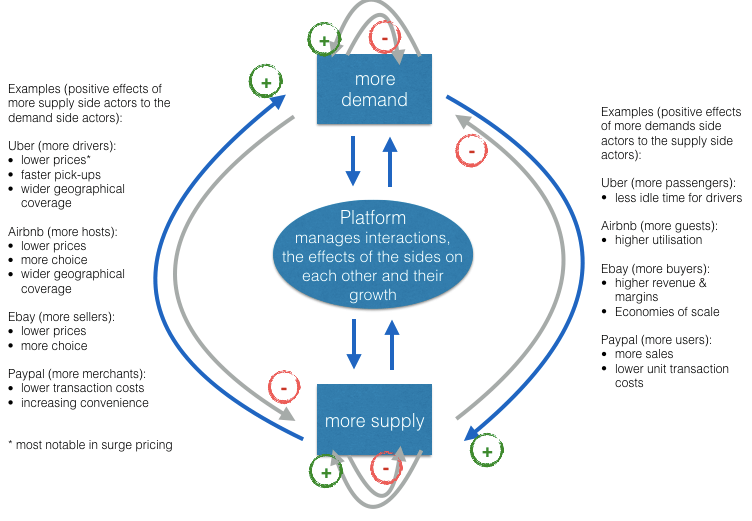
Network effect is commonly known as externalities in economics. It is an effect that is external to the transaction but influences the transaction. It is the incremental benefit gained by an existing user for each new user that joins the network. There are two types of network effects: Direct network effects and Indirect network effect. Direct network effects are same side effects. The value of a service goes up as the number of users goes up. For example, if more people have phones, it is useful for you to have a phone. The entire value proposition is one-sided. Indirect networks effects are multi-sided. It lends itself to our current thinking around platforms and why smart platforms can exponentially increase the network. The value of the service increases for one user group when a new user group joins the network. Take for example the relationship between credit card banks, merchants and consumers. There are three user groups, and each gather different value from the network of agents that have different roles. If more consumers use credit cards to buy, more merchants will sign up for the credit cards, and as more merchants sign up – more consumers will sign up with the bank to get more credit cards. This would be an example of a multi-sided platform that inherently has multi-sided network effects. The platform inherently gains significant power such that it becomes more valuable for participants in the system to join the network despite the incremental costs associated with joining the network. Platforms that are built upon effective multi-sided network effects grow quickly and are generally sustainable. Having said that, it could be just as easy that a few dominant bad actors in the network can dismantle and unravel the network completely. We often hear of the tipping point: namely, that once the platform reaches a critical mass of users, it would be difficult to dismantle it. That would certainly be true if the agents and services are, in the aggregate, distributed fairly across the network: but it is also possible that new networks creating even more multi-sided network effects could displace an entrenched network. Hence, it is critical that platform owners manage the quality of content and users and continue to look for more opportunities to introduce more user groups to entrench and yet exponentially grow the network.

Managing Scale
| I think the most difficult thing had been scaling the infrastructure. Trying to support the response we had received from our users and the number of people that were interested in using the software. – Shawn Fanning |
Froude’s number? It is defined as the square of the ship’s velocity divided by its length and multiplied by the acceleration caused by gravity. So why are we introducing ships in this chapter? As I have done before, I am liberally standing on the shoulder of the giant, Geoffrey West, and borrowing from his account on the importance of the Froude’s number and the practical implications. Since ships are subject to turbulence, using a small model that works in a simulated turbulent environment might not work when we manufacture a large ship that is facing the ebbs and troughs of a finicky ocean. The workings and impact of turbulence is very complex, and at scale it becomes even more complex. Froude’s key contribution was to figure out a mathematical pathway of how to efficiently and effectively scale from a small model to a practical object. He did that by using a ratio as the common denominator. Mr. West provides an example that hits home: How fast does a 10-foot-long ship have to move to mimic the motion of a 700-foot-long ship moving at 20 knots. If they are to have the same Froude number (that is, the same value of the square of their velocity divided by their length), then the velocity has to scale as the square root of their lengths. The ratio of the square root of their lengths is the the square of 700 feet of the ship/10 feet of the model ship which turns out to be the square of 70. For the 10-foot model to mimic the motion of a large ship, it must move at the speed of 20 knots/ square of 70 or 2.5 knots. The Froude number is still widely used across many fields today to bridge small scale and large-scale thinking. Although this number applies to physical systems, the notion that adaptive systems can be similarly bridged through appropriate mathematical equations. Unfortunately, because of the increased number of variables impacting adaptive systems and all of these variables working and learning from one another, the task of establishing a Froude number becomes diminishingly small.

The other concept that has gained wide attention is the science of allometry. Allometry essentially states that as size increases, then the form of the object would change. Allometric scaling governs all complex physical and adaptive systems. So the question is whether there are some universal laws or mathematics that can be used to enable us to better understand or predict scale impacts. Let us extend this thinking a bit further. If sizes influence form and form constitute all sub-physical elements, then it would stand to reason that a universal law or a set of equations can provide deep explanatory powers on scale and systems. One needs to bear in mind that even what one might consider a universal law might be true within finite observations and boundaries. In other words, if there are observations that fall outside of those boundaries, one is forced into resetting our belief in the universal law or to frame a new paradigm to cover these exigencies. I mention this because as we seek to understand business and global grand challenges considering the existence of complexity, scale, chaos and seeming disorder – we might also want to embrace multiple laws or formulations working at different hierarchies and different data sets to arrive at satisficing solutions to the problems that we want to wrestle with.
Physics and mathematics allow a qualitatively high degree of predictability. One can craft models across different scales to make a sensible approach on how to design for scale. If you were to design a prototype using a 3D printer and decide to scale that prototype a 100X, there are mathematical scalar components that are factored into the mechanics to allow for some sort of equivalence which would ultimately lead to the final product fulfilling its functional purpose in a complex physical system. But how does one manage scale in light of those complex adaptive systems that emerge due to human interactions, evolution of organization, uncertainty of the future, and dynamic rules that could rapidly impact the direction of a company?
Is scale a single measure? Or is it a continuum? In our activities, we intentionally or unintentionally invoke scale concepts. What is the most efficient scale to measure an outcome, so we can make good policy decisions, how do we apply our learning from one scale to a system that operates on another scale and how do we assess how sets of phenomena operate at different scales, spatially and temporally, and how they impact one another? Now the most interesting question: Is scale polymorphous? Does the word scale have different meanings in different contexts? When we talk about microbiology, we are operating at micro-scales. When we talk at a very macro level, our scales are huge. In business, we regard scale with respect to how efficiently we grow. In one way, it is a measure but for the following discussion, we will interpret scale as non-linear growth expending fewer and fewer resources to support that growth as a ratio.

As we had discussed previously, complex adaptive systems self-organize over time. They arrive at some steady state outcome without active intervention. In fact, the active intervention might lead to unintended consequences that might even spell doom for the system that is being influenced. So as an organization scales, it is important to keep this notion of rapid self-organization in mind which will inform us to make or not make certain decisions from a central or top-down perspective. In other words, part of managing scale successfully is to not manage it at a coarse-grained level.
The second element of successfully managing scale is to understand the constraints that prevent scale. There is an entire chapter dedicated to the theory of constraints which sheds light on why this is a fundamental process management technique that increases the pace of the system. But for our purposes in this section, we will summarize as follows: every system as it grows have constraints. It is important to understand the constraints because these constraints slow the system: the bottlenecks have to be removed. And once one constraint is removed, then one comes across another constraint. The system is a chain of events and it is imperative that all of these events are identified. The weakest links harangue the systems and these weakest links have to be either cleared or resourced to enable the system to scale. It is a continuous process of observation and tweaking the results with the established knowledge that the demons of uncertainty and variability can reset the entire process and one might have to start again. Despite that fact, constraint management is an effective method to negotiate and manage scale.

The third element is devising the appropriate organization architecture. As one projects into the future, management might be inclined toward developing and investing in the architecture early to accommodate the scale. Overinvestment in the architecture might not be efficient. As mentioned, cities and social systems that grow 100% require 85% investment in infrastructure: in other words, systems grow on a sublinear scale from an infrastructure perspective. How does management of scale arrive at the 85%? It is nigh impossible, but it is important to reserve that concept since it informs management to architect the infrastructure cautiously. Large investments upfront could be a waste or could slow the system down: alternative, investments that are postponed a little too late can also impact the system adversely.
The fourth element of managing scale is to focus your lens of opportunity. In macroecology, we can arrive at certain conclusions when we regard the system from a distance versus very closely. We can subsume our understanding into one big bucket called climate change and then we figure out different ways to manage the complexity that causes the climate change by invoking certain policies and incentives at a macro level. However, if we go closer, we might decide to target a very specific contributor to climate change – namely, fossil fuels. The theory follows that to manage the dynamic complexity and scale of climate impact – it would be best to address a major factor which, in this case, would be fossil fuels. The equivalence of this in a natural business setting would be to establish and focus the strategy for scale in a niche vertical or a relatively narrower set of opportunities. Even though we are working in the web of complex adaptive systems, we might devise strategies to directionally manage the business within the framework of complex physical systems where we have an understanding of the slight variations of initial state and the realization that the final outcome might be broad but yet bounded for intentional management.

The final element is the management of initial states. Complex physical systems are governed by variation in initial states. Perturbation of these initial states can lead to a wide divergence of outcomes, albeit bounded within a certain frame of reference. It is difficult perhaps to gauge all the interactions that might occur from a starting point to the outcome, although we agree that a few adjustments like decentralization of decision making, constraint management, optimal organization structure and narrowing the playing field would be helpful.
Internal versus External Scale
This article discusses internal and external complexity before we tee up a more detailed discussion on internal versus external scale. This chapter acknowledges that complex adaptive systems have inherent internal and external complexities which are not additive. The impact of these complexities is exponential. Hence, we have to sift through our understanding and perhaps even review the salient aspects of complexity science which have already been covered in relatively more detail in earlier chapter. However, revisiting complexity science is important, and we will often revisit this across other blog posts to really hit home the fundamental concepts and its practical implications as it relates to management and solving challenges at a business or even a grander social scale.

A complex system is a part of a larger environment. It is a safe to say that the larger environment is more complex than the system itself. But for the complex system to work, it needs to depend upon a certain level of predictability and regularity between the impact of initial state and the events associated with it or the interaction of the variables in the system itself. Note that I am covering both – complex physical systems and complex adaptive systems in this discussion. A system within an environment has an important attribute: it serves as a receptor to signals of external variables of the environment that impact the system. The system will either process that signal or discard the signal which is largely based on what the system is trying to achieve. We will dedicate an entire article on system engineering and thinking later, but the uber point is that a system exists to serve a definite purpose. All systems are dependent on resources and exhibits a certain capacity to process information. Hence, a system will try to extract as many regularities as possible to enable a predictable dynamic in an efficient manner to fulfill its higher-level purpose.
Let us understand external complexities. We can interchangeably use the word environmental complexity as well. External complexity represents physical, cultural, social, and technological elements that are intertwined. These environments beleaguered with its own grades of complexity acts as a mold to affect operating systems that are mere artifacts. If operating systems can fit well within the mold, then there is a measure of fitness or harmony that arises between an internal complexity and external complexity. This is the root of dynamic adaptation. When external environments are very complex, that means that there are a lot of variables at play and thus, an internal system has to process more information in order to survive. So how the internal system will react to external systems is important and they key bridge between those two systems is in learning. Does the system learn and improve outcomes on account of continuous learning and does it continually modify its existing form and functional objectives as it learns from external complexity? How is the feedback loop monitored and managed when one deals with internal and external complexities? The environment generates random problems and challenges and the internal system has to accept or discard these problems and then establish a process to distribute the problems among its agents to efficiently solve those problems that it hopes to solve for. There is always a mechanism at work which tries to align the internal complexity with external complexity since it is widely believed that the ability to efficiently align the systems is the key to maintaining a relatively competitive edge or intentionally making progress in solving a set of important challenges.
Internal complexity are sub-elements that interact and are constituents of a system that resides within the larger context of an external complex system or the environment. Internal complexity arises based on the number of variables in the system, the hierarchical complexity of the variables, the internal capabilities of information pass-through between the levels and the variables, and finally how it learns from the external environment. There are five dimensions of complexity: interdependence, diversity of system elements, unpredictability and ambiguity, the rate of dynamic mobility and adaptability, and the capability of the agents to process information and their individual channel capacities.

If we are discussing scale management, we need to ask a fundamental question. What is scale in the context of complex systems? Why do we manage for scale? How does management for scale advance us toward a meaningful outcome? How does scale compute in internal and external complex systems? What do we expect to see if we have managed for scale well? What does the future bode for us if we assume that we have optimized for scale and that is the key objective function that we have to pursue?
Scaling Considerations in Complex Systems and Organizations: Implications
Scale represents size. In a two-dimensional world, it is a linear measurement that presents a nominal ordering of numbers. In other words, 4 is two times two and 6 would be 3 times two. In other words, the difference between 4 and 6 represents an increase in scale by two. We will discuss various aspects of scale and the learnings that we can draw from it. However, before we go down this path, we would like to touch on resource consumption.

As living organisms, we consume resources. An average human being requires 2000 calories of food per day to sustain themselves. An average human being, by the way, is largely defined in terms of size. So it would be better put if we say that a 200lb person would require 2000 calories. However, if we were to regard a specimen that is 10X the size or 2000 lbs., would it require 10X the calories to sustain itself? Conversely, if the specimen was 1/100th the size of the average human being, then would it require 1/100th the calories to sustain itself. Thus, will we consume resources linearly to our size? Are we operating in a simple linear world? And if not, what are the ramifications for science, physics, biology, organizations, cities, climate, etc.?
Let us digress a little bit from the above questions and lay out a few interesting facts. Almost half of the population in the world today live in cities. This is compared to less than 15% of the world population that lived in cities a hundred years ago. It is anticipated that almost 75% of the world population will be living in cities by 2050. The number of cities will increase and so will the size. But for cities to increase in size and numbers, it requires vast amount of resources. In fact, the resource requirements in cities are far more extensive than in agrarian societies. If there is a limit to the resources from a natural standpoint – in other words, if the world is operating on a budget of natural resources – then would this mean that the growth of the cities will be naturally reined in? Will cities collapse because of lack of resources to support its mass?
What about companies? Can companies grow infinitely? Is there a natural point where companies might hit their limit beyond which growth would not be possible? Could a company collapse because the amount of resources that is required to sustain the size would be compromised? Are there other factors aside from resource consumption that play into what might cap the growth and hence the size of the company? Are there overriding factors that come into play that would superimpose the size-resource usage equation such that our worries could be safely kept aside? Are cities and companies governed by some sort of metabolic rate that governs the sustenance of life?

Geoffrey West, a theoretical physicist, has touched on a lot of the questions in his book: Scale: The Universal Laws of Growth, Innovation, Sustainability, and the Pace of Life in Organisms, Cities, Economies, and Companies. He says that a person requires about 90W (watts) of energy to survive. That is a light bulb burning in your living room in one day. That is our metabolic rate. However, just like man does not live by bread alone, an average man has to depend on a number of other artifacts that have agglomerated in bits and pieces to provide a quality of life to maximize sustenance. The person has to have laws, electricity, fuel, automobile, plumbing and water, markets, banks, clothes, phones and engage with other folks in a complex social network to collaborate and compete to achieve their goals. Geoffrey West says that the average person requires almost 11000W or the equivalent of almost 125 90W light bulbs. To put things in greater perspective, the social metabolic rate of 11,000W is almost equivalent to a dozen elephants. (An elephant requires 10X more energy than humans even though they might be 60X the size of the physical human being). Thus, a major portion of our energy is diverted to maintain the social and physical network that closely interplay to maintain our sustenance. And while we consume massive amounts of energy, we also create a massive amount of waste – and that is an inevitable outcome. This is called the entropy impact and we will touch on this in greater detail in later articles. Hence, our growth is not only constrained by our metabolic rate: it is further dampened by entropy that exists as the Second Law of Thermodynamics. And as a system ages, the impact of entropy increases manifold. Yes, it is true: once we get old, we are racing toward our death at a faster pace than when we were young. Our bodies are exhibiting fatigue faster than normal.
Scaling refers to how a system responds when its size changes. As mentioned earlier, does scaling follow a linear model? Do we need to consume 2X resources if we increase the size by 2X? How does scaling impact a Complex Physical System versus a Complex Adaptive System? Will a 2X impact on the initial state create perturbations in a CPS model which is equivalent to 2X? How would this work on a CAS model where the complexity is far from defined and understood because these systems are continuously evolving? Does half as big requires half as much or conversely twice as big requires twice as much? Once again, I have liberally dipped into this fantastic work by Geoffrey West to summarize, as best as possible, the definitions and implications. He proves that we cannot linearly extrapolate energy consumption and size: the world is smattered with evidence that undermines the linear extrapolation model. In fact, as you grow, you become more efficient with respect to energy consumption. The savings of energy due to growth in size is commonly called the economy of scale. His research also suggests two interesting results. When cities or social systems grow, they require an infrastructure to help with the growth. He discovered that it takes 85% resource consumption to grow the systems by 100%. Thus, there is a savings of 15% which is slightly lower than what has been studied on the biological front wherein organisms save 25% as they grow. He calls this sub linear scaling. In contrast, he also introduces the concept of super linear scaling wherein there is a 15% increasing returns to scale when the city or a social system grows. In other words, if the system grows by 100%, the positive returns with respect to such elements like patents, innovation, etc. will grow by 115%. In addition, the negative elements also grow in an equivalent manner – crime, disease, social unrest, etc. Thus, the growth in cities are supported by an efficient infrastructure that generates increasing returns of good and bad elements.
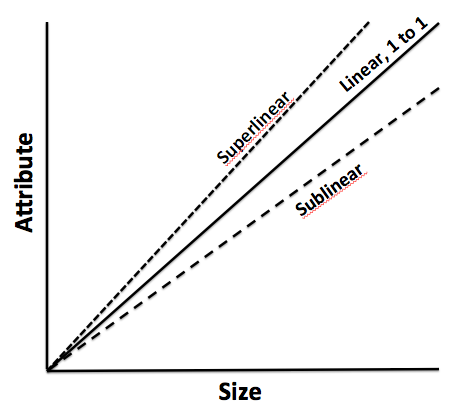
Max Kleiber, a Swiss chemist, in the 1930’s proposed the Kleiber’s law which sheds a lot of light on metabolic rates as energy consumption per unit of time. As mass increases so does the overall metabolic rate but it is not a linear relation – it obeys the power law. It stays that a living organism’s metabolic rate scales to the ¾ power of its mass. If the cat has a mass 100 times that of a mouse, the cat will metabolize about 100 ¾ = 31.63 times more energy per day rather than 100 times more energy per day. Kleiber’s law has led to the metabolic theory of energy and posits that the metabolic rate of organisms is the fundamental biological rate that governs most observed patters in our immediate ecology. There is some ongoing debate on the mechanism that allows metabolic rate to differ based on size. One mechanism is that smaller organisms have higher surface area to volume and thus needs relatively higher energy versus large organisms that have lower surface area to volume. This assumes that energy consumption occurs across surface areas. However, there is another mechanism that argues that energy consumption happens when energy needs are distributed through a transport network that delivers and synthesizes energy. Thus, smaller organisms do not have as a rich a network as large organisms and thus there is greater energy efficiency usage among smaller organisms than larger organisms. Either way, the implications are that body size and temperature (which is a result of internal activity) provide fundamental and natural constraints by which our ecological processes are governed. This leads to another concept called finite time singularity which predicts that unbounded growth cannot be sustained because it would need infinite resources or some K factor that would allow it to increase. The K factor could be innovation, a structural shift in how humans and objects cooperate, or even a matter of jumping on a spaceship and relocating to Mars.
We are getting bigger faster. That is real. The specter of a dystopian future hangs upon us like the sword of Damocles. The thinking is that this rate of growth and scale is not sustainable since it is impossible to marshal the resources to feed the beast in an adequate and timely manner. But interestingly, if we were to dig deeper into history – these thoughts prevailed in earlier times as well but perhaps at different scale. In 1798 Thomas Robert Malthus famously predicted that short-term gains in living standards would inevitably be undermined as human population growth outstripped food production, and thereby drive living standards back toward subsistence. Humanity thus was checkmated into an inevitable conclusion: a veritable collapse spurred by the tendency of population to grow geometrically while food production would increase only arithmetically. Almost two hundred years later, a group of scientists contributed to the 1972 book called Limits to Growth which had similar refrains like Malthus: the population is growing and there are not enough resources to support the growth and that would lead to the collapse of our civilization. However, humanity has negotiated those dark thoughts and we continue to prosper. If indeed, we are governed by this finite time singularity, we are aware that human ingenuity has largely won the day. Technology advancements, policy and institutional changes, new ways of collaboration, etc. have emerged to further delay this “inevitable collapse” that could be result of more mouths to feed than possible. What is true is that the need for new innovative models and new ways of doing things to solve the global challenges wrought by increased population and their correspondent demands will continue to increase at a quicker pace. Once could thus argue that the increased pace of life would not be sustainable. However, that is not a plausible hypothesis based on our assessment of where we are and where we have been.
Let us turn our attention to a business. We want the business to grow or do we want the business to scale? What is the difference? To grow means that your company is adding resources or infrastructure to handle increased demand, at a cost which is equivalent to the level of increased revenue coming in. Scaling occurs when the business is growing faster than the resources that are being consumed. We have already explored that outlier when you grow so big that you are crushed by your weight. It is that fact which limits the growth of organism regardless of issues related to scale. Similarly, one could conceivably argue that there are limits to growth of a company and might even turn to history and show that a lot of large companies of yesteryears have collapsed. However, it is also safe to say that large organizations today are by several factors larger than the largest organizations in the past, and that is largely on account of accumulated knowledge and new forms of innovation and collaboration that have allowed that to happen. In other words, the future bodes well for even larger organizations and if those organizations indeed reach those gargantuan size, it is also safe to draw the conclusion that they will be consuming far less resources relative to current organizations, thus saving more energy and distributing more wealth to the consumers.
Thus, scaling laws limit growth when it assumes that everything else is constant. However, if there is innovation that leads to structural changes of a system, then the limits to growth becomes variable. So how do we effect structural changes? What is the basis? What is the starting point? We look at modeling as a means to arrive at new structures that might allow the systems to be shaped in a manner such that the growth in the systems are not limited by its own constraints of size and motion and temperature (in physics parlance). Thus, a system is modeled at a presumably small scale but with the understanding that as the system is increases in size, the inner workings of emergent complexity could be a problem. Hence, it would be prudent to not linearly extrapolate the model of a small system to that of a large one but rather to exponential extrapolate the complexity of the new system that would emerge. We will discuss this in later articles, but it would be wise to keep this as a mental note as we forge ahead and refine our understanding of scale and its practical implications for our daily consumption.
