Author Archives: Hindol Datta
Zero Trust Framework: Steps for Effective Security Deployment
In the past decade, “Zero Trust” has become the cybersecurity mantra of modern enterprise strategy—oft-invoked, rarely clarified, and even more rarely implemented with conviction. It promises a future where no user, device, or workload is trusted by default. It assures boards and regulators of reduced breach risk, minimized lateral movement, and improved governance in a hybrid, perimeterless world.
But for most Chief Information Officers, the question is not “Why Zero Trust?”—that question is largely settled. The real challenge is how to implement it. Where to start. What to prioritize. How to measure progress. And perhaps most critically, how to embed it into existing business systems without disrupting continuity or creating resistance from teams that are already under pressure.
This essay provides a strategic framework for CIOs seeking to operationalize Zero Trust—not as a buzzword or compliance checklist, but as an enterprise security architecture with tangible outcomes.
I. Zero Trust: The Core Principle
At its heart, Zero Trust is a security model built on the assumption that no user, device, or process should be inherently trusted—whether inside or outside the network. Access is granted only after strict verification and is continuously reassessed based on context, behavior, and risk posture.
That sounds straightforward. But implementing it requires undoing decades of implicit trust architectures built into VPNs, LANs, Active Directory groups, and siloed identity systems.
To be precise, Zero Trust is not a single product, nor a plug-and-play solution. It is an operating model that spans five architectural domains:
- Identity (who are you?)
- Device (what are you using?)
- Network (where are you coming from?)
- Application/Workload (what are you accessing?)
- Data (what are you doing with it?)
Implementing Zero Trust means building controls and telemetry across all five—aligned to least privilege, continuous verification, and assumed breach principles.
II. The CIO’s Playbook: A Phased Approach to Implementation
Zero Trust cannot be implemented all at once. It must be sequenced based on risk, readiness, and business impact. The following phased roadmap outlines how CIOs can guide implementation across a 24–36 month horizon.
Phase 1: Establish Identity as the Control Plane
All Zero Trust efforts begin with identity.
- Unify Identity Systems: Consolidate identity providers (IdPs) across cloud and on-prem. Integrate Single Sign-On (SSO) and Multi-Factor Authentication (MFA) across all business-critical applications.
- Implement Conditional Access Policies: Enforce access based on user role, device health, location, and behavior.
- Inventory Service Accounts and Non-Human Identities: These are frequently exploited in breaches. Apply just-in-time access, eliminate hard-coded credentials, and rotate secrets.
Key Metric: % of enterprise applications under SSO with MFA enforcement.
Phase 2: Device Trust and Endpoint Hardening
Once identity is controlled, the next step is ensuring that only trusted and healthy devices access enterprise resources.
- Deploy Endpoint Detection and Response (EDR) tools across all managed devices.
- Establish Device Compliance Policies: Block access from jailbroken, unpatched, or unmanaged devices.
- Implement Mobile Device Management (MDM) and Desktop Compliance Enforcement.
Key Metric: % of enterprise assets in compliance with baseline security posture.
Phase 3: Network Microsegmentation and Least Privilege
Traditional flat networks with broad trust zones are anathema to Zero Trust.
- Segment Internal Networks: Apply microsegmentation in data centers and cloud environments to limit east-west traffic.
- Replace VPNs with ZTNA (Zero Trust Network Access): Grant application-level access rather than full network access.
- Limit Admin Rights: Adopt least privilege across user roles and IT staff. Rotate and audit all privileged credentials.
Key Metric: % reduction in unnecessary lateral movement paths.
Phase 4: Application and Workload Protection
Modern applications must be explicitly authenticated and authorized—regardless of where they run.
- Apply App-Level Access Control: Use reverse proxies or identity-aware proxies to authenticate access to applications.
- Encrypt Traffic Internally: Ensure mutual TLS between microservices in distributed systems.
- Adopt Runtime Protection and Behavior Monitoring: Especially in containerized or serverless environments.
Key Metric: % of internal apps protected by app-level access policies.
Phase 5: Data-Level Controls and Behavioral Analytics
The final pillar is visibility and control at the data layer.
- Tag and Classify Sensitive Data: Integrate data loss prevention (DLP) tools to enforce policy.
- Enable User and Entity Behavior Analytics (UEBA): Detect anomalous behavior at the user, device, and workload level.
- Establish Insider Threat Programs: Correlate behavior with risk thresholds to trigger investigation or response.
Key Metric: % of sensitive data covered by classification and access controls.
III. Enablers of Success
1. Executive Sponsorship and Change Management
Zero Trust cannot succeed as a technology initiative alone. It must be a strategic imperative owned by senior leadership, including the CIO, CISO, and business leaders.
- Align Zero Trust implementation with enterprise risk appetite.
- Communicate the “why” to business users—security as enabler, not barrier.
- Provide support and training for cultural adoption.
2. Vendor Consolidation and Architecture Simplification
CIOs must resist the temptation to stack tools and platforms without architectural coherence. A fragmented Zero Trust ecosystem leads to visibility gaps, duplication, and friction.
- Favor platforms with integration and automation capabilities.
- Build around a unified identity fabric and a common policy engine.
- Rationalize legacy infrastructure that contradicts Zero Trust principles.
3. Continuous Monitoring and Automation
Zero Trust is not static. Threats evolve. Behaviors change.
- Implement real-time monitoring for drift in posture.
- Automate remediation and access revocation where feasible.
- Adopt a “trust but verify” loop, powered by telemetry and behavioral analytics.
IV. Measuring Progress: Zero Trust Maturity Model
CIOs should adopt a maturity model to assess and communicate progress to stakeholders. Levels may include:
| Level | Description |
|---|---|
| 0 | Implicit trust. Perimeter-centric architecture. |
| 1 | MFA, some app-level access controls. |
| 2 | Unified identity, device compliance, microsegmentation. |
| 3 | Real-time access decisions, UEBA, ZTNA. |
| 4 | Adaptive, continuous trust evaluation at all layers. |
The goal is not perfection, but continuous improvement and risk alignment.
V. Conclusion: Zero Trust as a Strategic Operating Model
Zero Trust is not merely a cybersecurity project. It is a reorientation of the enterprise architecture around verification, visibility, and least privilege. For CIOs, the mission is to move from theory to action—step by step, domain by domain, guided by metrics, anchored in business value.
In an age where perimeters no longer exist, where threats originate from within as much as without, and where data and workloads move across clouds and devices in milliseconds, Zero Trust is not optional—it is essential.
The implementation journey is complex. But the payoff—resilience, agility, confidence—is worth every phase.
AI and the Evolving Role of CFOs
For much of the twentieth century, the role of the Chief Financial Officer was understood in familiar terms. A steward of control. A master of precision. A guardian of the balance sheet. The CFO was expected to be meticulous, cautious, and above all, accountable. Decisions were made through careful deliberation. Assumptions were scrutinized. Numbers did not lie; they merely required interpretation. There was an art to the conservatism and a quiet pride in it. Order, after all, was the currency of good finance.
Then artificial intelligence arrived—not like a polite guest knocking at the door, but more like a storm bursting through the windows, unsettling assumptions, and rewriting the rules of what it means to manage the financial function. Suddenly, the world of structured inputs and predictable outputs became a dynamic theater of probabilities, models, and machine learning loops. The close of the quarter, once a ritual of discipline and human labor, was now something that could be shortened by algorithms. Forecasts, previously the result of sleepless nights and spreadsheets, could now be generated in minutes. And yet, beneath the glow of progress, a quieter question lingered in the minds of financial leaders: Are we still in control?
The paradox is sharp. AI promises greater accuracy, faster insights, and efficiencies that were once unimaginable. But it also introduces new vulnerabilities. Decisions made by machines cannot always be explained by humans. Data patterns shift, and models evolve in ways that are hard to monitor, let alone govern. The very automation that liberates teams from tedious work may also obscure how decisions are being made. For CFOs, whose role rests on the fulcrum of control and transparency, this presents a challenge unlike any other.
To understand what is at stake, one must first appreciate the philosophical shift taking place. Traditional finance systems were built around rules. If a transaction did not match a predefined criterion, it was flagged. If a value exceeded a threshold, it triggered an alert. There was a hierarchy to control. Approvals, audits, reconciliations—all followed a chain of accountability. AI, however, does not follow rules in the conventional sense. It learns patterns. It makes predictions. It adjusts based on what it sees. In place of linear logic, it offers probability. In place of rules, it gives suggestions.
This does not make AI untrustworthy, but it does make it unfamiliar. And unfamiliarity breeds caution. For CFOs who have spent decades refining control environments, AI is not merely a tool. It is a new philosophy of decision-making. And it is one that challenges the muscle memory of the profession.
What, then, does it mean to stay in control in an AI-enhanced finance function? It begins with visibility. CFOs must ensure that the models driving key decisions—forecasts, risk assessments, working capital allocations—are not black boxes. Every algorithm must come with a passport. What data went into it? What assumptions were made? How does it behave when conditions change? These are not technical questions alone. They are governance questions. And they sit at the heart of responsible financial leadership.
Equally critical is the quality of data. An AI model is only as reliable as the information it consumes. Dirty data, incomplete records, or inconsistent definitions can quickly derail the most sophisticated tools. In this environment, the finance function must evolve from being a consumer of data to a custodian of it. The general ledger, once a passive repository of transactions, becomes part of a living data ecosystem. Consistency matters. Lineage matters. And above all, context matters. A forecast that looks brilliant in isolation may collapse under scrutiny if it was trained on flawed assumptions.
But visibility and data are only the beginning. As AI takes on more tasks that were once performed by humans, the traditional architecture of control must be reimagined. Consider the principle of segregation of duties. In the old world, one person entered the invoice, another approved it, and a third reviewed the ledger. These checks and balances were designed to prevent fraud, errors, and concentration of power. But what happens when an AI model is performing all three functions? Who oversees the algorithm? Who reviews the reviewer?
The answer is not to retreat from automation, but to introduce new forms of oversight. CFOs must create protocols for algorithmic accountability. This means establishing thresholds for machine-generated recommendations, building escalation paths for exceptions, and defining moments when human judgement must intervene. It is not about mistrusting the machine. It is about ensuring that the machine is governed with the same discipline once reserved for people.
And then there is the question of resilience. AI introduces new dependencies—on data pipelines, on cloud infrastructures, on model stability. A glitch in a forecasting model could ripple through the entire enterprise plan. A misfire in an expense classifier could disrupt a close. These are not hypothetical risks. They are operational realities. Just as organizations have disaster recovery plans for cyber breaches or system outages, they must now develop contingency plans for AI failures. The models must be monitored. The outputs must be tested. And the humans must be prepared to take over when the automation stumbles.
Beneath all of this, however, lies a deeper cultural transformation. The finance team of the future will not be composed solely of accountants, auditors, and analysts. It will also include data scientists, machine learning specialists, and process architects. The rhythm of work will shift—from data entry and manual reconciliations to interpretation, supervision, and strategic advising. This demands a new kind of fluency. Not necessarily the ability to write code, but the ability to understand how AI works, what it can do, and where its boundaries lie.
This is not a small ask. It requires training, cross-functional collaboration, and a willingness to challenge tradition. But it also opens the door to a more intellectually rich finance function—one where humans and machines collaborate to generate insights that neither could have achieved alone.
If there is a guiding principle in all of this, it is that control does not mean resisting change. It means shaping it. For CFOs, the task is not to retreat into spreadsheets or resist the encroachment of algorithms. It is to lead the integration of intelligence into every corner of the finance operation. To set the standards, define the guardrails, and ensure that the organization embraces automation not as a surrender of responsibility, but as an evolution of it.
Because in the end, the goal is not simply to automate. It is to augment. Not to replace judgement, but to elevate it. Not to remove the human hand from finance, but to position it where it matters most: at the helm, guiding the ship through faster currents, with clearer vision and steadier hands.
Artificial intelligence may never match the emotional weight of human intuition. It may not understand the stakes behind a quarter’s earnings or the subtle implications of a line item in a note to shareholders. But it can free up time. It can provide clarity. It can make the financial function faster, more adaptive, and more resilient.
And if the CFO of the past was a gatekeeper, the CFO of the future will be a choreographer—balancing risk and intelligence, control and creativity, all while ensuring that the numbers, no matter how complex their origin, still tell a story that is grounded in truth.
The machines are here. They are learning. And they are listening. The challenge is not to contain them, but to guide them—thoughtfully, carefully, and with the discipline that has always defined great finance.
Because in this new world, control is not lost. It is simply redefined.

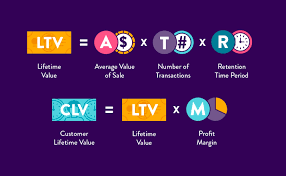
The Power of Customer Lifetime Value in Modern Business
In contemporary business discourse, few metrics carry the strategic weight of Customer Lifetime Value (CLV). CLV and CAC are prime metrics. For modern enterprises navigating an era defined by digital acceleration, subscription economies, and relentless competition, CLV represents a unifying force, uniting finance, marketing, and strategy into a single metric that measures not only transactions but also the value of relationships. Far more than a spreadsheet calculation, CLV crystallizes lifetime revenue, loyalty, referral impact, and long-term financial performance into a quantifiable asset.
This article explores CLV’s origins, its mathematical foundations, its role as a strategic North Star across organizational functions, and the practical systems required to integrate it fully into corporate culture and capital allocation. It also highlights potential pitfalls and ethical implications.
I. CLV as a Cross-Functional Metric
CLV evolved from a simple acknowledgement: not all customers are equally valuable, and many businesses would prosper more by nurturing relationships than chasing clicks. The transition from single-sale tallies to lifetime relationship value gained momentum with the rise of subscription models—telecom plans, SaaS platforms, and membership programs—where the fiscal significance of recurring revenue became unmistakable.
This shift reframed capital deployment and decision-making:
- Marketing no longer seeks volume unquestioningly but targets segments with high long-term value.
- Finance integrates CLV into valuation models and capital allocation frameworks.
- Strategy uses it to guide M&A decisions, pricing stratagems, and product roadmap prioritization.
Because CLV is simultaneously a financial measurement and a customer-centric tool, it builds bridges—translating marketing activation into board-level impact.
II. How to calculate CLV
At its core, CLV employs economic modeling similar to net present value. A basic formula:
CLV = ∑ (t=0 to T) [(Rt – Ct) / (1 + d)^t]
- Rt = revenue generated at time t
- Ct = cost to serve/acquire at time t
- d = discount rate
- T = time horizon
This anchors CLV in well-accepted financial principles: discounted future cash flows, cost allocation, and multi-period forecasting. It satisfies CFO requirements for rigor and measurability.
However, marketing leaders often expand this to capture:
- Referral value (Rt includes not just direct sales, but influenced purchases)
- Emotional or brand-lift dimensions (e.g., window customers who convert later)
- Upselling, cross-selling, and tiered monetization over time
These expansions refine CLV into a dynamic forecast rather than a static average—one that responds to segmentation and behavioral triggers.
III. CLV as a Board-Level Metric
A. Investment and Capital Prioritization
Traditional capital decisions rely on ROI, return on invested capital (ROIC), and earnings multiples. CLV adds nuance: it gauges not only immediate returns but extended client relationships. This enables an expanded view of capital returns.
For example, a company might shift budget from low-CLV acquisition channels to retention-focused strategies—investing more in on-boarding, product experience, or customer success. These initiatives, once considered costs, now become yield-generating assets.
B. Segment-Based Acquisition
CLV enables precision targeting. A segment that delivers a 6:1 lifetime value-to-acquisition-cost (LTV:CAC) ratio is clearly more valuable than one delivering 2:1. Marketing reallocates spend accordingly, optimizing strategic segmentation and media mix, tuning messaging for high-value cohorts.
Because CLV is quantifiable and forward-looking, it naturally aligns marketing decisions with shareholder-driven metrics.
C. Tiered Pricing and Customer Monetization
CLV is also central to monetization strategy. Churn, upgrade rates, renewal behaviors, and pricing power all can be evaluated through the lens of customer value over time. Versioning, premium tiers, loyalty benefits—all become levers to maximize lifetime value. Finance and strategy teams model these scenarios to identify combinations that yield optimal returns.
D. Strategic Partnerships and M&A
CLV informs deeper decisions about partnerships and mergers. In evaluating a potential platform acquisition, projected contribution to overall CLV may be a decisive factor, especially when combined customer pools or cross-sell ecosystems can amplify lifetime revenue. It embeds customer value insights into due diligence and valuation calculations.
IV. Organizational Integration: A Strategic Imperative
Effective CLV deployment requires more than good analytics—it demands structural clarity and cultural alignment across three key functions.
A. Finance as Architect
Finance teams frame the assumptions—discount rates, cost allocation, margin calibration—and embed CLV into broader financial planning and analysis. Their task: convert behavioral data and modeling into company-wide decision frameworks used in investment reviews, budgeting, and forecasting processes.
B. Marketing as Activation Engine
Marketing owns customer acquisition, retention campaigns, referral programs, and product messaging. Their role is to feed the CLV model with real data: conversion rates, churn, promotion impact, and engagement flows. In doing so, campaigns become precision tools tuned to maximize customer yield rather than volume alone.
C. Strategy as Systems Designer
The strategy team weaves CLV outputs into product roadmaps, pricing strategy, partnership design, and geographic expansion. Using CLV foliated by cohort and channel, strategy leaders can sequence investments to align with long-term margin objectives—such as a five-year CLV-driven revenue mix.
V. Embedding CLV Into Corporate Processes
The following five practices have proven effective at embedding CLV into organizational DNA:
- Executive Dashboards
Incorporate LTV:CAC ratios, cohort retention rates, and segment CLV curves into executive reporting cycles. Tie leadership incentives (e.g., bonuses, compensation targets) to long-term value outcomes. - Cross-Functional CLV Cells
Establish CLV analytics teams staffed by finance, marketing insights, and data engineers. They own CLV modeling, simulation, and distribution across functions. - Monthly CLV Reviews
Monthly orchestration meetings integrate metrics updates, marketing feedback on campaigns, pricing evolution, and retention efforts. Simultaneous adjustment across functions allows dynamic resource allocation. - Capital Allocation Gateways
Projects involving customer-facing decisions—from new products to geographic pullbacks—must include CLV impact assessments in gating criteria. These can also feed into product investment requests and ROI thresholds. - Continuous Learning Loops
CLV models must be updated with actual lifecycle data. Regular recalibration fosters learning from retention behaviors, pricing experiments, churn drivers, and renewal rates—fueling confidence in incremental decision-making.
VI. Caveats and Limitations
CLV, though powerful, is not a cure-all. These caveats merit attention:
- Data Quality: Poorly integrated systems, missing customer identifiers, or inconsistent cohort logic can produce misleading CLV metrics.
- Assumption Risk: Discount rates, churn decay, turnaround behavior—all are model assumptions. Unqualified confidence can mislead investment.
- Narrow Focus: High CLV may chronically favor established segments, leaving growth through new markets or products underserved.
- Over-Targeting Risk: Over-optimizing for short-term yield may harm brand reputation or equity with broader audiences.
Therefore, CLV must be treated with humility—an advanced tool requiring discipline in measurement, calibration, and multi-dimensional insight.
VII. The Influence of Digital Ecosystems
Modern digital ecosystems deliver immense granularity. Every interaction—click, open, referral, session length—is measurable. These dark data provide context for CLV testing, segment behavior, and risk triggers.
However, this scale introduces overfitting risk: spurious correlations may override structural signals. Successful organizations maintain a balance—leveraging high-frequency signals for short-cycle interventions, while retaining medium-term cohort logic for capital allocation and strategic initiatives.
VIII. Ethical and Brand Implications
“CLV”, when viewed through a values lens, also becomes a cultural and ethical marker. Decisions informed by CLV raise questions:
- To what extent should a business monetize a cohort? Is excessive monetization ethical?
- When loyalty programs disproportionately reward high-value customers, does brand equity suffer among moderate spenders?
- When referral bonuses attract opportunists rather than advocates, is brand authenticity compromised?
These considerations demand that CLV strategies incorporate brand and ethical governance, not just financial optimization.
IX. Cross-Functionally Harmonized Governance
A robust operating model to sustain CLV alignment should include:
- Structured Metrics Governance: Common cohort definitions, discount rates, margin allocation, and data timelines maintained under joint sponsorship.
- Integrated Information Architecture: Real-time reporting, defined data lineage (acquisition to LTV), and cross-functional access.
- Quarterly Board Oversight: Board-level dashboards that track digital customer performance and CLV trends as fundamental risk and opportunity signals.
- Ethical Oversight Layer: Cross-functional reviews ensuring CLV-driven decisions don’t undermine customer trust or brand perception.
X. CLV as Strategic Doctrine
When deployed with discipline, CLV becomes more than a metric—it becomes a cultural doctrine. The essential tenets are:
- Time horizon focus: orienting decisions toward lifetime impact rather than short-cycle transactions.
- Cross-functional governance: embedding CLV into finance, marketing, and strategy with shared accountability.
- Continuous recalibration: creating feedback loops that update assumptions and reinforce trust in the metric.
- Ethical stewardship: ensuring customer relationships are respected, brand equity maintained, and monetization balanced.
With that foundation, CLV can guide everything from media budgets and pricing plans to acquisition strategy and market expansion.
Conclusion
In an age where customer relationships define both resilience and revenue, Customer Lifetime Value stands out as an indispensable compass. It unites finance’s need for systematic rigor, marketing’s drive for relevance and engagement, and strategy’s mandate for long-term value creation. When properly modeled, governed, and governed ethically, CLV enables teams to shift from transactional quarterly mindsets to lifetime portfolios—transforming customers into true franchise assets.
For any organization aspiring to mature its performance, CLV is the next frontier. Not just a metric on a dashboard—but a strategic mechanism capable of aligning functions, informing capital allocation, shaping product trajectories, elevating brand meaning, and forging relationships that transcend a single transaction.

Strategic Implications of Enterprise-Wide Digital Investments
In times of structural disruption, firms do not win by cutting costs; they win by reallocating capital faster, smarter, and with greater conviction. Over the past decade, enterprise-wide digital investment has shifted from a tactical IT project to a strategic imperative. What began as process automation or e-commerce enablement has evolved into a systemic transformation of how firms operate, compete, and grow.
Today, enterprise-wide digital investments are less about the adoption of technology and more about the redefinition of the business model itself. From cloud-native infrastructure to AI-assisted operations, from digital twin simulations to predictive analytics across the value chain—these initiatives constitute a new type of capital deployment. Unlike traditional capital expenditures that depreciate linearly, digital investments compound in insight, speed, and scale. And herein lies both their promise and their peril.
This briefing explores the strategic implications of digital investments when executed at the enterprise level: how they reshape value chains, organizational structure, competitive advantage, and the economics of scale and scope.
1. Digital Investments Shift the Firm’s Strategic Gravity
Traditionally, scale was a function of assets like plants, people, and capital. In a digitized enterprise, scale becomes a function of intelligence, data, algorithms, and adaptability.
When done right, digital investments create self-improving systems. For instance:
- A retail company with AI-enabled supply chains reduces out-of-stock incidents while optimizing working capital.
- An insurer using machine learning for fraud detection identifies anomalies in real time, not months later.
- A logistics provider leveraging predictive maintenance extends asset life and reduces downtime by 20–30%.
The core strategic implication is this: digital investments change what the firm is optimized to do. It can shift from being product-led to customer-led, from efficiency-driven to insight-driven. That demands an overhaul not just of systems, but of strategic posture.
2. Capital Allocation and Portfolio Strategy Must Evolve
Digital transformation projects were once confined to departmental budgets. Today, they demand board-level capital allocation discipline. These are no longer line-item IT expenses but enterprise-wide investments with enterprise-wide impact.
For example, migrating to a unified cloud ERP might cost $100M over five years, but the real ROI stems from enabling faster M&A integration, real-time working capital visibility, and harmonized reporting. The payback is strategic optionality, not just cost savings.
The CFO’s role here becomes pivotal. Capital budgeting must now include:
- Option value of digital platforms (e.g., ability to plug in AI or partner ecosystems)
- Risk-adjusted returns across a portfolio of transformation bets
- Digital depreciation schedules, where relevance erodes faster than hardware
Strategic capital planning must move toward a model where digital investments are layered, staged, and continuously re-evaluated.
3. Competitive Moats Become Digital and Dynami
Historically, moats were built with physical barriers—distribution networks, regulatory licenses, sunk costs. In the digital era, moats are made of data, software, and ecosystems. But they are also perishable.
Enterprise-wide digital investments can generate new defensible advantages:
- Proprietary customer insights from data lakes and AI models
- Superior operational response due to real-time analytics
- Ecosystem leverage, enabling monetization via APIs and platforms
Yet, because software is replicable and cloud-native tools are accessible to all, these moats must be renewed continuously. The implication is clear: digital advantage is less about what you own and more about how you evolve.
Boards and leadership teams must measure competitive health not only in terms of market share, but also digital adaptability—how quickly the enterprise can sense, decide, and act on new information.
4. Organizational Design Must Match Digital Ambitions
Enterprise-wide digital investment often stumbles not due to bad tech, but due to organizational mismatch. The logic of digital is speed, cross-functionality, and learning. The logic of many firms is hierarchy, silos, and control.
To realize value from digital investments, firms must:
- Shift from project teams to product teams (e.g., digital channels as internal “products”)
- Create fusion teams of domain experts, engineers, and data scientists
- Empower decision-making at the edge with data and tooling
Critically, leadership must develop digital fluency. CIOs, CFOs, COOs, and even CHROs must speak a common digital language—one of APIs, latency, use cases, and user experience—not just compliance and governance.
5. Governance, Risk, and Change Management Need a Digital Upgrade
Digital transformation introduces both strategic upside and systemic risk. AI models may drift. Cloud integrations may leak. Change fatigue may undermine adoption. Cyber risk may metastasize across digital touchpoints.
The board must establish:
- Digital KPIs, distinct from traditional financial metrics (e.g., time-to-insight, model reusability, digital engagement scores)
- Clear accountability for digital value capture (product owners, not just project managers)
- Governance that adapts at digital speed, with quarterly reviews of portfolio progress and real-time escalation paths
Risk management must be proactive, not reactive. It must be focused not only on “failures” but on early signals of friction or value leakage.
6. Exit Multiples and Valuation Are Digitally Sensitive
The final strategic implication concerns the market itself. Increasingly, investors and acquirers reward digital maturity. Companies with robust digital infrastructure, scalable platforms, and advanced analytics capabilities often receive premium valuations.
Research by BCG suggests that companies scoring high on digital maturity enjoy valuation premiums of 10–20% relative to peers. More critically, digital maturity de-risks growth, improving forecast confidence, reducing customer churn, and enabling faster scale.
In M&A contexts, digital readiness has become a due diligence priority. Firms that invest proactively in digital infrastructure can exit at higher multiples, with greater buyer optionality and fewer post-deal surprises.
Conclusion: Digital Investment as Strategic Doctrine
Enterprise-wide digital investment is no longer a side bet. It is the central doctrine of strategic relevance in a world defined by velocity, uncertainty, and intelligence. To treat it as a series of IT upgrades is to miss the point. This is not digitization of existing processes: it is the re-architecture of the firm for the future.
Boards must evaluate digital decisions not merely through the lens of ROI, but through the broader calculus of optionality, resilience, and learning speed. The firms that do will not only operate better, but they will also out-adapt, outlast, and outgrow the competition.
The digital revolution is not coming. It’s already on the balance sheet.

Cybersecurity: A Financial Imperative for Enterprises
In today’s digital enterprise, bits are as valuable as bricks and often, far more vulnerable. Yet, in many companies, cybersecurity is still treated as a technical silo, an IT or risk function that operates parallel to finance, not in partnership with it. That view is not tenable. Twenty years ago, I did not face these issues in the corporate reporting requirements, and this was not a risk that was on our minds. However, cybersecurity is just as relevant to any board topic as is AI. You cannot escape that fact.

The time has come to recognize the obvious: cybersecurity is not only a technical risk, but it is a financial one. Breaches don’t just disrupt operations; they erase enterprise value, destroy trust, invite regulatory wrath, and in extreme cases, threaten solvency. When cyber meets ledger, finance must have a seat at the security table. Why? Because one incident can be very disruptive.
This is not an abstract assertion. It is a strategic imperative, backed by the numbers, shaped by recent events, and made urgent by the economic consequences of cyber failures. The CFO must be involved in procurement or any strategic decision to make significant investments. Other digital officers are responsible for working with the CFO to surface other peripheral matters concerning the security that might call for strategic acquisitions.
1. Cyber Risk = Financial Risk, Quantified
Let’s begin with the fundamentals. Cyber-attacks are no longer rare events; they are statistical certainties. According to IBM’s Cost of a Data Breach 2024 report, the average cost of a breach globally now exceeds $4.45 million, with U.S. enterprises facing upwards of $9.48 million. And those numbers are merely the direct costs like recovery, containment, and legal. The indirect costs are customer churn, lost revenue, brand erosion, and often exceed direct damages by a factor of 3–5x.
In fact, a joint study by McKinsey and WEF suggests that cyberattacks will cost the global economy $10.5 trillion annually by 2025—a GDP-sized line item.
Now let’s put that in a CFO’s language:
| Risk Category | Financial Consequence |
|---|---|
| Ransomware Attack | Working capital disruption; liquidity risk |
| IP Theft | Asset impairment; loss of competitive moat |
| Customer Data Leak | Revenue loss; legal settlements |
| Downtime (IT systems) | Operational margin compression |
| Regulatory Non-Compliance | Fines; increased cost of capital |
In every scenario, the impact is measurable and material. The conclusion is inescapable: cybersecurity is now a line item in enterprise value protection.
2. The CFO as Chief Risk Synthesizer
Traditionally, cybersecurity sat under the CIO or CISO. But cyber risk does not respect functional boundaries. It affects:
- Audit: Internal control over financial reporting (SOX 404)
- Treasury: Business continuity and liquidity risk
- FP&A: Scenario planning for cyber impact
- Investor Relations: Market confidence post-breach
- Legal/Compliance: Exposure under GDPR, CCPA, and SEC rules
The CFO is uniquely positioned to integrate these perspectives: balancing prevention, insurance, investment, and response into a coherent risk-return framework.
Consider the recent SEC rules effective late 2023: Material cybersecurity incidents must be disclosed within four business days. That’s not an IT timeline. It is an earnings call timeline. When cyber events go public, it’s the CFO who faces the market. Finance cannot afford to be reactive; it must be embedded in the response architecture.
3. Cybersecurity as a Capital Allocation Problem
Good security is expensive. Excellent security is a strategic capital allocation.
The modern security stack—zero trust architecture, endpoint detection, penetration testing, encryption protocols, identity access management—is a cost center until it isn’t. The question isn’t whether to spend, but where and when, and with what ROI.
Here’s how finance can transform cybersecurity posture:
- Prioritize investments based on asset value at risk (VAR) and breach cost modeling.
- Stress-test cyber scenarios using probabilistic simulations (Monte Carlo, Black Swan analysis).
- Integrate cyber risk into enterprise risk-adjusted return frameworks.
- Model insurance vs. self-insure trade-offs using expected loss distributions.
Done right, cybersecurity becomes a portfolio optimization problem that the finance function is already equipped to solve.
4. The Hidden Cost of Cyber-Invisibility
When finance is not at the table, the cost is organizational blindness.
- Duplicate controls: Redundant spending between IT, legal, and operations.
- Unmodeled exposures: Gaps between asset valuation and risk coverage.
- Unquantified tail risks: No understanding of a “cyber black swan” event’s P&L or balance sheet impact.
- Non-aligned incentives: Security teams optimizing for tech coverage, not economic protection.
In the absence of financial oversight, security spending can become compliance theater: a shopping list of checklists and firewalls without strategic coherence.
5. The Operating Model for Finance-Security Integration
To remedy this, we recommend a joint operating model where finance and security collaborate through structured governance:
| Element | Integration Action |
|---|---|
| Cyber Risk Register | Maintained with finance input on asset and exposure value |
| CapEx & OpEx Planning | Security budgets reviewed jointly with finance |
| Quarterly Reviews | Cyber risk dashboards embedded in finance reporting |
| Incident Simulation | Tabletop exercises include treasury and IR participation |
| Insurance Strategy | Joint modeling of coverage vs. reserve thresholds |
In many ways, this mirrors the finance–supply chain integration we saw post-COVID: strategic alignment on fragility, cost, and continuity.
6. Case in Point: The SEC, MGM, and the Market Memory
Let us not be theoretical.
In September 2023, MGM Resorts suffered a major ransomware attack. Slots stopped spinning. Hotel doors failed to open. Earnings took a hit. MGM’s stock dropped 18%, wiping out $3 billion in market cap. The real kicker? The breach was traced to a social engineering attack on a single helpdesk employee.
A simple access failure cascaded into an enterprise value event.
Could this have been prevented with finance at the table? Maybe not. But could it have been modeled, provisioned, insured, and disclosed more fluently? Almost certainly.
7. AI, Cyber Risk, and the Finance Imperative
AI introduces an entirely new cyber-attack surface:
- Model theft
- Prompt injection
- Synthetic identity fraud
- Data poisoning
As companies embed AI into everything from financial modeling to customer experience, the intersection of AI risk and cyber risk will demand CFO leadership.
Already, questions like “Can this AI output be trusted in our forecasting model?” or “Could someone exfiltrate financial data via a chatbot?” are no longer science fiction. They are boardroom topics.
Cyber risk will no longer be episodic. It will be continuous, autonomous, and probabilistic, which makes it inherently financial.
Conclusion: Build the Bridge Now, Before the Breach
Finance must no longer be downstream of cybersecurity decisions. We must shape them, model them, and embed them into every financial projection and enterprise risk scenario.
Because in the final analysis, cybersecurity is not just an IT problem, not just a compliance issue, and certainly not just an insurance line item.
It is a capital protection function. A continuity engine. A balance sheet defense mechanism.
And for all those reasons, finance deserves and requires a seat at the security table.
Transforming CFOs: Embracing AI for Financial Success
There was a time when the role of the CFO was defined by stewardship: safeguarding the books, closing the quarter, and forecasting with prudent conservatism. Today, that definition is wholly inadequate. In a world tilting inexorably toward algorithmic intelligence, the CFO is no longer just a fiduciary — we are architects of a financial operating system where data, AI, and decision velocity converge.
This note is a proposition and a prescription: that AI-centric finance is not a technology strategy—it is an operating model, and that model must be designed, led, and owned by the CFO. Anything less cedes the future.
1. AI Is a Platform Shift, Not a Toolkit
Let us be clear: AI is not merely another lever in the CFO’s arsenal, like Excel macros or business intelligence dashboards. It is a platform shift—on par with cloud computing or the internet itself. It alters how decisions are made, who makes them, and how capital is allocated.
This shift demands we move from a “system of record” mindset to a “system of prediction” mindset.
| Legacy Finance | AI-Centric Finance |
|---|---|
| Backward-looking reporting | Forward-looking simulation |
| Human-curated KPIs | Machine-generated signal flows |
| Monthly cadence | Real-time, event-triggered ops |
| Budgeting as ritual | Resource allocation as feedback loop |
| Centralized authority | Distributed, data-informed autonomy |
In essence, we move from a factory model to a flight control tower: sensing, predicting, and guiding.
2. The New Operating Model: From Ledgers to Learning Loops
To build an AI-centric finance function, we must redesign the operating architecture around learning loops rather than linear workflows. The core building blocks include:
a. Data Infrastructure as a Strategic Asset
CFOs must co-own the data strategy. The model is clear:
- Raw data → Feature stores → Model-ready data
- Semantic layers → Finance language models (think: LLMs trained on GL, ERP, CRM, and FP&A)
An AI-powered finance team relies on data infrastructure that is clean, contextualized, and composable. This isn’t IT’s job anymore. It’s ours.
b. Continuous Planning, Not Static Budgeting
Traditional annual budgets are like shipping maps drawn before a hurricane. In contrast, AI enables rolling forecasts, scenario generation, and probabilistic planning. Tools like Anaplan, Pigment, or proprietary GPT-integrated forecasting systems now allow for:
- Real-time reforecasting with changing assumptions
- Automated budget-to-actual variance alerts
- Simulations of strategic levers (pricing, CAC, retention)
The role of FP&A evolves into Financial Strategy Engineering—a fusion of economics, machine learning, and systems design.
c. Decision Intelligence as the New Currency
Finance becomes a recommendation engine for the business. AI can generate not just insights but actions:
- What customers are at risk?
- Which marketing campaigns should we throttle or double down on?
- Where is working capital trapped?
CFOs must build closed-loop systems where insights lead to decisions that feed back into the models.
3. The Organizational Shift: Finance as a Product Team
Operating in an AI-centric model demands a new org design. Instead of siloed roles, we pivot to cross-functional pods, often structured like product teams:
| Role | Equivalent in AI Finance Org |
|---|---|
| FP&A Analyst | Financial Systems Engineer |
| Data Analyst | Finance ML Model Trainer |
| Business Partner | Embedded Finance Product Owner |
| IT Systems Support | Finance Platform Architect |
The finance team must build and iterate on internal tools and products, not just reports. We design experiences: from dashboards that anticipate user needs to bots that answer ad-hoc questions in natural language.
The CFO becomes the CPO (Chief Product Officer) of Financial Intelligence.
4. Governance at Machine Speed
AI doesn’t eliminate the need for controls; it amplifies the need. The pace of autonomous decisions must be matched by machine-readable guardrails.
- Policy-as-code: Embedding compliance logic directly into finance bots and workflows.
- AI Explainability: Every model decision—whether it’s a forecast or anomaly detection—must come with interpretable output and an audit trail.
- Risk thresholds: Systems must flag decisions that cross financial or operational boundaries, triggering human review or automated throttling.
This is a new form of programmable governance, where financial controls are embedded in code, not PDFs.
5. The Cultural Imperative: From Gatekeepers to Guides
As we re-architect the model, we must also rewire the mindset.
Finance traditionally acted as a gatekeeper—approving spend, enforcing discipline, setting limits. In the AI model, our role shifts to enabling empowered decision-making through context and clarity.
We go from saying “no” to asking “why not, and what’s the ROI?”
We no longer build walls; we build rails that allow the business to move faster without falling off track.
And we must become evangelists for this shift—training teams on tools, interpreting model outputs, and building trust in autonomous systems.
6. Capital Allocation in the AI Era
Lastly, the ultimate lever of the CFO—capital allocation—becomes more dynamic and precise in an AI-driven world.
- Dynamic ROI modeling for investments, updated in real-time as new data arrives.
- Predictive cash flow management, with AI forecasting AR/AP cycles by customer cohort behavior.
- Workforce planning using scenario-based modeling of productivity, automation, and compensation structures.
Capital now flows not based on politics or precedent, but based on learning, signal, and impact. That’s the endgame.
The Architect’s Blueprint: What the CFO Must Build
To operationalize the above, the AI-centric CFO must design and oversee:
| Blueprint Layer | Key Responsibilities |
|---|---|
| Data Platform | Own data quality, context, and taxonomy |
| Model Layer | Select, govern, and train financial AI |
| Decision Layer | Build planning and forecasting engines |
| Experience Layer | Create interfaces (dashboards, bots, apps) |
| Governance Layer | Encode compliance, explainability, and audit |
| Talent Layer | Upskill team into AI-native operators |
Every year, each layer must be re-evaluated, stress-tested, and updated—just as an architect revisits a skyscraper’s load-bearing assumptions after an earthquake.
Conclusion: From Number Cruncher to Neural Architect
To thrive in the decade ahead, the CFO must step fully into this new mantle—not as a finance operator, but as a neural architect of the enterprise. We must weave together data, design, governance, and intelligence into an operating model that is fast, flexible, and self-improving.
AI won’t replace finance teams. But finance leaders who fail to build AI-native models will be replaced by those who do.
As Warren Buffett once said, “When the tide goes out, you find out who’s been swimming naked.” In this new AI tide, the question isn’t whether you’re clothed—it’s whether your operating model is waterproof.
Let us build accordingly.
Navigating Startup Growth: Adapting Your Operating Model Every Year
If a startup’s journey can be likened to an expedition up Everest, then its operating model is the climbing gear—vital, adaptable, and often revised. In the early stages, founders rely on grit and flexibility. But as companies ascend and attempt to scale, they face a stark and simple truth: yesterday’s systems are rarely fit for tomorrow’s challenges. The premise of this memo is equally stark: your operating model must evolve—consciously and structurally—every 12 months if your company is to scale, thrive, and remain relevant.
This is not a speculative opinion. It is a necessity borne out by economic theory, pattern recognition, operational reality, and the statistical arc of business mortality. According to a 2023 McKinsey report, only 1 in 200 startups make it to $100M in revenue, and even fewer become sustainably profitable. The cliff isn’t due to product failure alone—it’s largely an operational failure to adapt at the right moment. Let’s explore why.
1. The Law of Exponential Complexity
Startups begin with a high signal-to-noise ratio. A few people, one product, and a common purpose. Communication is fluid, decision-making is swift, and adjustments are frequent. But as the team grows from 10 to 50 to 200, each node adds complexity. If you consider the formula for potential communication paths in a group—n(n-1)/2—you’ll find that at 10 employees, there are 45 unique interactions. At 50? That number explodes to 1,225.
This isn’t just theory. Each of those paths represents a potential decision delay, misalignment, or redundancy. Without an intentional redesign of how information flows, how priorities are set, and how accountability is structured, the weight of complexity crushes velocity. An operating model that worked flawlessly in Year 1 becomes a liability in Year 3.
Lesson: The operating model must evolve to actively simplify while the organization expands.
2. The 4 Seasons of Growth
Companies grow in phases, each requiring different operating assumptions. Think of them as seasons:
| Stage | Key Focus | Operating Model Needs |
|---|---|---|
| Start-up | Product-Market Fit | Agile, informal, founder-centric |
| Early Growth | Customer Traction | Lean teams, tight loops, scalable GTM |
| Scale-up | Repeatability | Functional specialization, metrics |
| Expansion | Market Leadership | Cross-functional governance, systems |
At each transition, the company must answer: What must we centralize vs. decentralize? What metrics now matter? Who owns what? A model that optimizes for speed in Year 1 may require guardrails in Year 2. And in Year 3, you may need hierarchy—yes, that dreaded word among startups—to maintain coherence.
Attempting to scale without rethinking the model is akin to flying a Cessna into a hurricane. Many try. Most crash.
3. From Hustle to System: Institutionalizing What Works
Founders often resist operating models because they evoke bureaucracy. But bureaucracy isn’t the issue—entropy is. As the organization grows, systems prevent chaos. A well-crafted operating model does three things:
- Defines governance – who decides what, when, and how.
- Aligns incentives – linking strategy, execution, and rewards.
- Enables measurement – providing real-time feedback on what matters.
Let’s take a practical example. In the early days, a product manager might report directly to the CEO and also collaborate closely with sales. But once you have multiple product lines and a sales org with regional P&Ls, that old model breaks. Now you need Product Ops. You need roadmap arbitration based on capacity planning, not charisma.
Translation: Institutionalize what worked ad hoc by architecting it into systems.
4. Why Every 12 Months? The Velocity Argument
Why not every 24 months? Or every 6? The 12-month cadence is grounded in several interlocking reasons:
- Business cycles: Most companies operate on annual planning rhythms. You set targets, budget resources, and align compensation yearly. The operating model must match that cadence or risk misalignment.
- Cultural absorption: People need time to digest one operating shift before another is introduced. Twelve months is the Goldilocks zone—enough to evaluate results but not too long to become obsolete.
- Market feedback: Every year brings fresh feedback from the market, investors, customers, and competitors. If your operating model doesn’t evolve in step, you’ll lose your edge—like a boxer refusing to switch stances mid-fight.
And then there’s compounding. Like interest on capital, small changes in systems—when made annually—compound dramatically. Optimize decision velocity by 10% annually, and in 5 years, you’ve doubled it. Delay, and you’re crushed by organizational debt.
5. The Operating Model Canvas
To guide this evolution, we recommend using a simplified Operating Model Canvas—a strategic tool that captures the six dimensions that must evolve together:
| Dimension | Key Questions |
|---|---|
| Structure | How are teams organized? What’s centralized? |
| Governance | Who decides what? What’s the escalation path? |
| Process | What are the key workflows? How do they scale? |
| People | Do roles align to strategy? How do we manage talent? |
| Technology | What systems support this stage? Where are the gaps? |
| Metrics | Are we measuring what matters now vs. before? |
Reviewing and recalibrating these dimensions annually ensures that the foundation evolves with the building. The alternative is often misalignment, where strategy runs ahead of execution—or worse, vice versa.
6. Case Studies in Motion: Lessons from the Trenches
a. Slack (Pre-acquisition)
In Year 1, Slack’s operating model emphasized velocity of product feedback. Engineers spoke to users directly, releases shipped weekly, and product decisions were founder-led. But by Year 3, with enterprise adoption rising, the model shifted: compliance, enterprise account teams, and customer success became core to the GTM motion. Without adjusting the operating model to support longer sales cycles and regulated customer needs, Slack could not have grown to a $1B+ revenue engine.
b. Airbnb
Initially, Airbnb’s operating rhythm centered on peer-to-peer UX. But as global regulatory scrutiny mounted, they created entirely new policy, legal, and trust & safety functions—none of which were needed in Year 1. Each year, Airbnb re-evaluated what capabilities were now “core” vs. “context.” That discipline allowed them to survive major downturns (like COVID) and rebound.
c. Stripe
Stripe invested heavily in internal tooling as they scaled. Recognizing that developer experience was not only for customers but also internal teams, they revised their internal operating platforms annually—often before they were broken. The result: a company that scaled to serve millions of businesses without succumbing to the chaos that often plagues hypergrowth.
7. The Cost of Inertia
Aging operating models extract a hidden tax. They confuse new hires, slow decisions, demoralize high performers, and inflate costs. Worse, they signal stagnation. In a landscape where capital efficiency is paramount (as underscored in post-2022 venture dynamics), bloated operating models are a death knell.
Consider this: According to Bessemer Venture Partners, top quartile SaaS companies show Rule of 40 compliance with fewer than 300 employees per $100M of ARR. Those that don’t? Often have twice the headcount with half the profitability—trapped in models that no longer fit their stage.
8. How to Operationalize the 12-Month Reset
For practical implementation, I suggest a 12-month Operating Model Review Cycle:
| Month | Focus Area |
|---|---|
| Jan | Strategic planning finalization |
| Feb | Gap analysis of current model |
| Mar | Cross-functional feedback loop |
| Apr | Draft new operating model vNext |
| May | Review with Exec Team |
| Jun | Pilot model changes |
| Jul | Refine and communicate broadly |
| Aug | Train managers on new structures |
| Sep | Integrate into budget planning |
| Oct | Lock model into FY plan |
| Nov | Run simulations/test governance |
| Dec | Prepare for January launch |
This cycle ensures that your org model does not lag behind your strategic ambition. It also sends a powerful cultural signal: we evolve intentionally, not reactively.
Conclusion: Be the Architect, Not the Archaeologist
Every successful company is, at some level, a systems company. Apple is as much about its supply chain as its design. Amazon is a masterclass in operating cadence. And Salesforce didn’t win by having a better CRM—it won by continuously evolving its go-to-market and operating structure.
To scale, you must be the architect of your company’s operating future—not an archaeologist digging up decisions made when the world was simpler.
So I leave you with this conviction: operating models are not carved in stone—they are coded in cycles. And the companies that win are those that rewrite that code every 12 months—with courage, with clarity, and with conviction.
Precision at Scale: How to Grow Without Drowning in Complexity
In business, as in life, scale is seductive. It promises more of the good things—revenue, reach, relevance. But it also invites something less welcome: complexity. And the thing about complexity is that it doesn’t ask for permission before showing up. It simply arrives, unannounced, and tends to stay longer than you’d like.
As we pursue scale, whether by growing teams, expanding into new markets, or launching adjacent product lines, we must ask a question that seems deceptively simple: how do we know we’re scaling the right way? That question is not just philosophical—it’s deeply economic. The right kind of scale brings leverage. The wrong kind brings entropy.

Now, if I’ve learned anything from years of allocating capital, it is this: returns come not just from growth, but from managing the cost and coordination required to sustain that growth. In fact, the most successful enterprises I’ve seen are not the ones that scaled fastest. They’re the ones that scaled precisely. So, let’s get into how one can scale thoughtfully, without overinvesting in capacity, and how to tell when the system you’ve built is either flourishing or faltering.
To begin, one must understand that scale and complexity do not rise in parallel; complexity has a nasty habit of accelerating. A company with two teams might have a handful of communication lines. Add a third team, and you don’t just add more conversations—you add relationships between every new and existing piece. In engineering terms, it’s a combinatorial explosion. In business terms, it’s meetings, misalignment, and missed expectations.
Cities provide a useful analogy. When they grow in population, certain efficiencies appear. Infrastructure per person often decreases, creating cost advantages. But cities also face nonlinear rises in crime, traffic, and disease—all manifestations of unmanaged complexity. The same is true in organizations. The system pays a tax for every additional node, whether that’s a service, a process, or a person. That tax is complexity, and it compounds.
Knowing this, we must invest in capacity like we would invest in capital markets—with restraint and foresight. Most failures in capacity planning stem from either a lack of preparation or an excess of confidence. The goal is to invest not when systems are already breaking, but just before the cracks form. And crucially, to invest no more than necessary to avoid those cracks.
Now, how do we avoid overshooting? I’ve found that the best approach is to treat capacity like runway. You want enough of it to support takeoff, but not so much that you’ve spent your fuel on unused pavement. We achieve this by investing in increments, triggered by observable thresholds. These thresholds should be quantitative and predictive—not merely anecdotal. If your servers are running at 85 percent utilization across sustained peak windows, that might justify additional infrastructure. If your engineering lead time starts rising despite team growth, it suggests friction has entered the system. Either way, what you’re watching for is not growth alone, but whether the system continues to behave elegantly under that growth.
Elegance matters. Systems that age well are modular, not monolithic. In software, this might mean microservices that scale independently. In operations, it might mean regional pods that carry their own load, instead of relying on a centralized command. Modular systems permit what I call “selective scaling”—adding capacity where needed, without inflating everything else. It’s like building a house where you can add another bedroom without having to reinforce the foundation. That kind of flexibility is worth gold.
Of course, any good decision needs a reliable forecast behind it. But forecasting is not about nailing the future to a decimal point. It is about bounding uncertainty. When evaluating whether to scale, I prefer forecasts that offer a range—base, best, and worst-case scenarios—and then tie investment decisions to the 75th percentile of demand. This ensures you’re covering plausible upside without betting on the moon.
Let’s not forget, however, that systems are only as good as the signals they emit. I’m wary of organizations that rely solely on lagging indicators like revenue or margin. These are important, but they are often the last to move. Leading indicators—cycle time, error rates, customer friction, engineer throughput—tell you much sooner whether your system is straining. In fact, I would argue that latency, broadly defined, is one of the clearest signs of stress. Latency in delivery. Latency in decisions. Latency in feedback. These are the early whispers before systems start to crack.
To measure whether we’re making good decisions, we need to ask not just if outcomes are improving, but if the effort to achieve them is becoming more predictable. Systems with high variability are harder to scale because they demand constant oversight. That’s a recipe for executive burnout and organizational drift. On the other hand, systems that produce consistent results with declining variance signal that the business is not just growing—it’s maturing.
Still, even the best forecasts and the finest metrics won’t help if you lack the discipline to say no. I’ve often told my teams that the most underrated skill in growth is the ability to stop. Stopping doesn’t mean failure; it means the wisdom to avoid doubling down when the signals aren’t there. This is where board oversight matters. Just as we wouldn’t pour more capital into an underperforming asset without a turn-around plan, we shouldn’t scale systems that aren’t showing clear returns.
So when do we stop? There are a few flags I look for. The first is what I call capacity waste—resources allocated but underused, like a datacenter running at 20 percent utilization, or a support team waiting for tickets that never come. That’s not readiness. That’s idle cost. The second flag is declining quality. If error rates, customer complaints, or rework spike following a scale-up, then your complexity is outpacing your coordination. Third, I pay attention to cognitive load. When decision-making becomes a game of email chains and meeting marathons, it’s time to question whether you’ve created a machine that’s too complicated to steer.
There’s also the budget creep test. If your capacity spending increases by more than 10 percent quarter over quarter without corresponding growth in throughput, you’re not scaling—you’re inflating. And in inflation, as in business, value gets diluted.
One way to guard against this is by treating architectural reserves like financial ones. You wouldn’t deploy your full cash reserve just because an opportunity looks interesting. You’d wait for evidence. Similarly, system buffers should be sized relative to forecast volatility, not organizational ambition. A modest buffer is prudent. An oversized one is expensive insurance.
Some companies fall into the trap of building for the market they hope to serve, not the one they actually have. They build as if the future were guaranteed. But the future rarely offers such certainty. A better strategy is to let the market pull capacity from you. When customers stretch your systems, then you invest. Not because it’s a bet, but because it’s a reaction to real demand.
There’s a final point worth making here. Scaling decisions are not one-time events. They are sequences of bets, each informed by updated evidence. You must remain agile enough to revise the plan. Quarterly evaluations, architectural reviews, and scenario testing are the boardroom equivalent of course correction. Just as pilots adjust mid-flight, companies must recalibrate as assumptions evolve.
To bring this down to earth, let me share a brief story. A fintech platform I advised once found itself growing at 80 percent quarter over quarter. Flush with success, they expanded their server infrastructure by 200 percent in a single quarter. For a while, it worked. But then something odd happened. Performance didn’t improve. Latency rose. Error rates jumped. Why? Because they hadn’t scaled the right parts. The orchestration layer, not the compute layer, was the bottleneck. Their added capacity actually increased system complexity without solving the real issue. It took a re-architecture, and six months of disciplined rework, to get things back on track. The lesson: scaling the wrong node is worse than not scaling at all.
In conclusion, scale is not the enemy. But ungoverned scale is. The real challenge is not growth, but precision. Knowing when to add, where to reinforce, and—perhaps most crucially—when to stop. If we build systems with care, monitor them with discipline, and remain intellectually honest about what’s working, we give ourselves the best chance to grow not just bigger, but better.
And that, to borrow a phrase from capital markets, is how you compound wisely.
Systems Thinking and Complexity Theory: Practical Tools for Complex Business Challenges
In business today, leaders are expected to make decisions faster and with better outcomes, often in environments filled with ambiguity and noise. The difference between companies that merely survive and those that thrive often comes down to the quality of thinking behind those decisions.
Two powerful tools that help elevate decision quality are systems thinking and complexity theory. These approaches are not academic exercises. They are practical ways to better understand the big picture, anticipate unintended consequences, and focus on what truly matters. They help leaders see connections across functions, understand how behavior evolves over time, and adapt more effectively when conditions change.
Let us first understand what each of these ideas means, and then look at how they can be applied to real business problems.
What is Systems Thinking?
Systems thinking is an approach that looks at a problem not in isolation but as part of a larger system of related factors. Rather than solving symptoms, it helps identify root causes. It focuses on how things interact over time, including feedback loops and time delays that may not be immediately obvious.
Imagine you are managing a business and notice that sales conversions are low. A traditional response might be to retrain the sales team or change the pitch deck. A systems thinker would ask broader questions. Are the leads being qualified properly? Has marketing changed its targeting criteria? Is pricing aligned with customer expectations? Are there delays in proposal generation? You begin to realize that what looks like a sales issue could be caused by something upstream in marketing or downstream in operations.
What is Complexity Theory?
Complexity theory applies when a system is made up of many agents or parts that interact and change over time. These parts adapt to one another, and the system as a whole evolves in unpredictable ways. In a complex system, outcomes are not linear. Small inputs can lead to large outcomes, and seemingly stable patterns can suddenly shift.
A good example is employee engagement. You might roll out a well-designed recognition program and expect morale to improve. But in practice, results may vary because employees interpret and respond differently based on team dynamics, trust in leadership, or recent changes in workload. Complexity theory helps leaders approach these systems with humility, awareness, and readiness to adjust based on feedback from the system itself.
Applying These Ideas to Real Business Challenges
Use Case 1: Sales Pipeline Bottleneck
A common challenge in many organizations is a slowdown or bottleneck in the sales pipeline. Traditional metrics may show that qualified leads are entering the top of the funnel, but deals are not progressing. Rather than focusing only on sales performance, a systems thinking approach would involve mapping the full sales cycle.
You might uncover that the product demo process is delayed because of engineering resource constraints. Or perhaps legal review for proposals is taking longer due to new compliance requirements. You may even discover that the leads being passed from marketing do not match the sales team’s target criteria, leading to wasted effort.
Using systems thinking, you start to see that the sales pipeline is not a simple sequence. It is an interconnected system involving marketing, sales, product, legal, and customer success. A change in one part affects the others. Once the feedback loops are visible, solutions become clearer and more effective. This might involve realigning handoff points, adjusting incentive structures, or investing in automation to speed up internal reviews.
In a more complex situation, complexity theory becomes useful. For example, if customer buying behavior has changed due to economic uncertainty, the usual pipeline patterns may no longer apply. You may need to test multiple strategies and watch for how the system responds, such as shortening the sales cycle for certain segments or offering pilot programs. You learn and adjust in real time, rather than assuming a static playbook will work.
Use Case 2: Increase in Voluntary Attrition
Voluntary attrition, especially among high performers, often triggers a reaction from HR to conduct exit interviews or offer retention bonuses. While these steps have some value, they often miss the deeper systemic causes.
A systems thinking approach would examine the broader employee experience. Are new hires receiving proper onboarding? Is workload increasing without changes in staffing? Are team leads trained in people management? Is career development aligned with employee expectations?
You might find that a recent reorganization led to unclear roles, increased stress, and a breakdown in peer collaboration. None of these factors alone might seem critical, but together they form a reinforcing loop that drives disengagement. Once identified, you can target specific leverage points, such as improving communication channels, resetting team norms, or introducing job rotation to restore a sense of progress and purpose.
Now layer in complexity theory. Culture, trust, and morale are not mechanical systems. They evolve based on stories people tell, leadership behavior, and informal networks. The same policy change can be embraced in one part of the organization and resisted in another. Solutions here often involve small interventions and feedback loops. You might launch listening sessions, try lightweight pulse surveys, or pilot flexible work models in select teams. You then monitor the ripple effects. The goal is not full control, but guided adaptation.
Separating Signal from Noise
In both examples above, systems thinking and complexity theory help leaders rise above the noise. Not every metric, complaint, or fluctuation requires action. But when seen in context, some of these patterns reveal early signals of deeper shifts.
The strength of these frameworks is that they encourage patience, curiosity, and structured exploration. You avoid knee-jerk reactions and instead look for root causes and emerging trends. Over time, this leads to better diagnosis, better prioritization, and better outcomes.
Final Thoughts
In a world where data is abundant but insight is rare, systems thinking and complexity theory provide a critical edge. They help organizations become more aware, more adaptive, and more resilient.
Whether you are trying to improve operational efficiency, respond to market changes, or build a healthier culture, these approaches offer practical tools to move from reactive problem-solving to thoughtful system design.
You do not need to be a specialist to apply these principles. You just need to be willing to ask broader questions, look for patterns, and stay open to learning from the system you are trying to improve.
This kind of thinking is not just smart. It is becoming essential for long-term business success.
Bias and Error: Human and Organizational Tradeoff
“I spent a lifetime trying to avoid my own mental biases. A.) I rub my own nose into my own mistakes. B.) I try and keep it simple and fundamental as much as I can. And, I like the engineering concept of a margin of safety. I’m a very blocking and tackling kind of thinker. I just try to avoid being stupid. I have a way of handling a lot of problems — I put them in what I call my ‘too hard pile,’ and just leave them there. I’m not trying to succeed in my ‘too hard pile.’” : Charlie Munger — 2020 CalTech Distinguished Alumni Award interview
Bias is a disproportionate weight in favor of or against an idea or thing, usually in a way that is closed-minded, prejudicial, or unfair. Biases can be innate or learned. People may develop biases for or against an individual, a group, or a belief. In science and engineering, a bias is a systematic error. Statistical bias results from an unfair sampling of a population, or from an estimation process that does not give accurate results on average.
Error refers to a outcome that is different from reality within the context of the objective function that is being pursued.
Thus, I would like to think that the Bias is a process that might lead to an Error. However, that is not always the case. There are instances where a bias might get you to an accurate or close to an accurate result. Is having a biased framework always a bad thing? That is not always the case. From an evolutionary standpoint, humans have progressed along the dimension of making rapid judgements – and much of them stemming from experience and their exposure to elements in society. Rapid judgements are typified under the System 1 judgement (Kahneman, Tversky) which allows bias and heuristic to commingle to effectively arrive at intuitive decision outcomes.

And again, the decision framework constitutes a continually active process in how humans or/and organizations execute upon their goals. It is largely an emotional response but could just as well be an automated response to a certain stimulus. However, there is a danger prevalent in System 1 thinking: it might lead one to comfortably head toward an outcome that is seemingly intuitive, but the actual result might be significantly different and that would lead to an error in the judgement. In math, you often hear the problem of induction which establishes that your understanding of a future outcome relies on the continuity of the past outcomes, and that is an errant way of thinking although it still represents a useful tool for us to advance toward solutions.
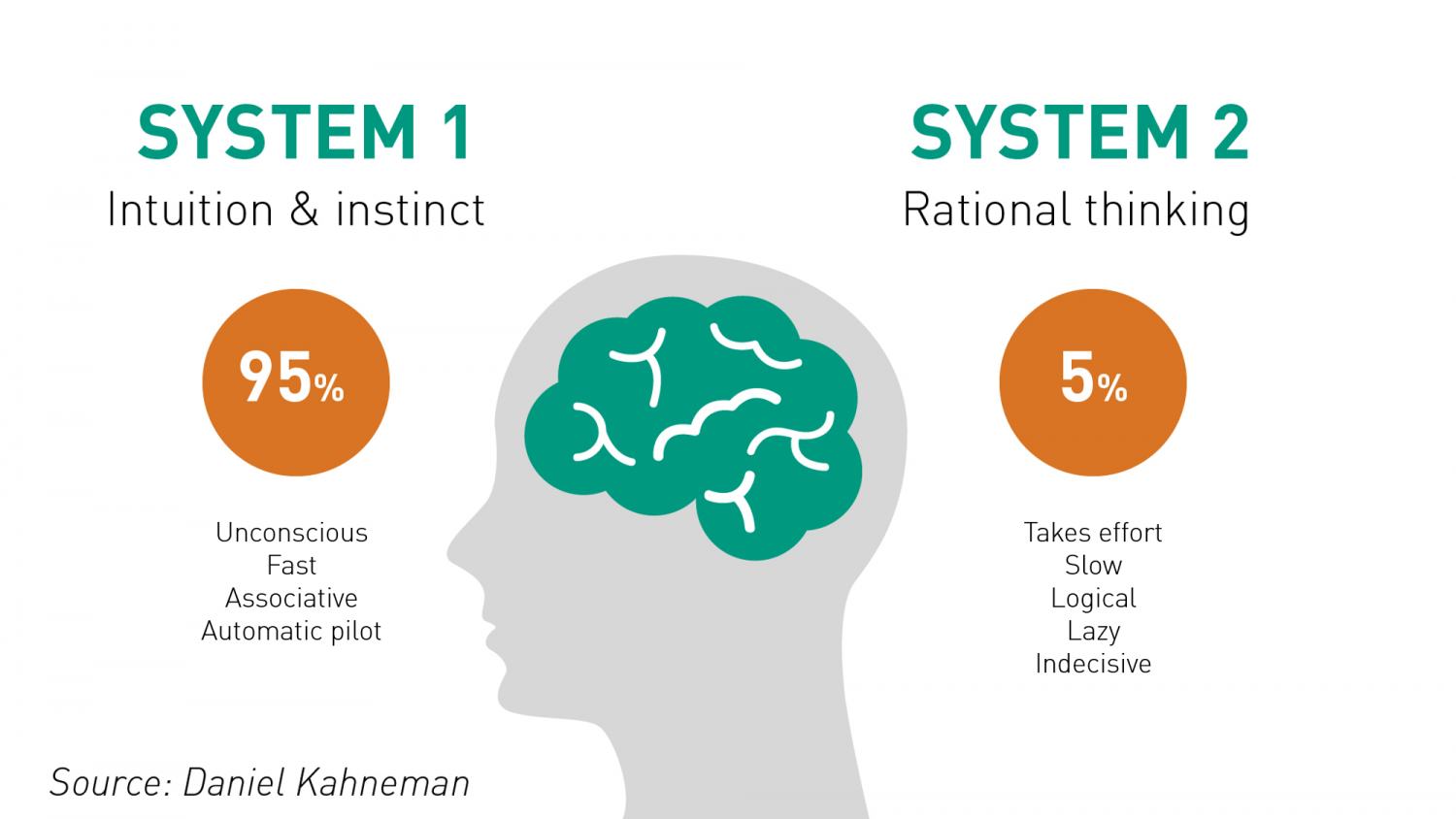
System 2 judgement emerges as another means to temper the more significant variabilities associated with System 1 thinking. System 2 thinking represents a more deliberate approach which leads to a more careful construct of rationale and thought. It is a system that slows down the decision making since it explores the logic, the assumptions, and how the framework tightly fits together to test contexts. There are a more lot more things at work wherein the person or the organization has to invest the time, focus the efforts and amplify the concentration around the problem that has to be wrestled with. This is also the process where you search for biases that might be at play and be able to minimize or remove that altogether. Thus, each of the two Systems judgement represents two different patterns of thinking: rapid, more variable and more error prone outcomes vs. slow, stable and less error prone outcomes.
So let us revisit the Bias vs. Variance tradeoff. The idea is that the more bias you bring to address a problem, there is less variance in the aggregate. That does not mean that you are accurate. It only means that there is less variance in the set of outcomes, even if all of the outcomes are materially wrong. But it limits the variance since the bias enforces a constraint in the hypotheses space leading to a smaller and closely knit set of probabilistic outcomes. If you were to remove the constraints in the hypotheses space – namely, you remove bias in the decision framework – well, you are faced with a significant number of possibilities that would result in a larger spread of outcomes. With that said, the expected value of those outcomes might actually be closer to reality, despite the variance – than a framework decided upon by applying heuristic or operating in a bias mode.
So how do we decide then? Jeff Bezos had mentioned something that I recall: some decisions are one-way street and some are two-way. In other words, there are some decisions that cannot be undone, for good or for bad. It is a wise man who is able to anticipate that early on to decide what system one needs to pursue. An organization makes a few big and important decisions, and a lot of small decisions. Identify the big ones and spend oodles of time and encourage a diverse set of input to work through those decisions at a sufficiently high level of detail. When I personally craft rolling operating models, it serves a strategic purpose that might sit on shifting sands. That is perfectly okay! But it is critical to evaluate those big decisions since the crux of the effectiveness of the strategy and its concomitant quantitative representation rests upon those big decisions. Cutting corners can lead to disaster or an unforgiving result!

I will focus on the big whale decisions now. I will assume, for the sake of expediency, that the series of small decisions, in the aggregate or by itself, will not sufficiently be large enough that it would take us over the precipice. (It is also important however to examine the possibility that a series of small decisions can lead to a more holistic unintended emergent outcome that might have a whale effect: we come across that in complexity theory that I have already touched on in a set of previous articles).

Cognitive Biases are the biggest mea culpas that one needs to worry about. Some of the more common biases are confirmation bias, attribution bias, the halo effect, the rule of anchoring, the framing of the problem, and status quo bias. There are other cognition biases at play, but the ones listed above are common in planning and execution. It is imperative that these biases be forcibly peeled off while formulating a strategy toward problem solving.
But then there are also the statistical biases that one needs to be wary of. How we select data or selection bias plays a big role in validating information. In fact, if there are underlying statistical biases, the validity of the information is questionable. Then there are other strains of statistical biases: the forecast bias which is the natural tendency to be overtly optimistic or pessimistic without any substantive evidence to support one or the other case. Sometimes how the information is presented: visually or in tabular format – can lead to sins of the error of omission and commission leading the organization and judgement down paths that are unwarranted and just plain wrong. Thus, it is important to be aware of how statistical biases come into play to sabotage your decision framework.

One of the finest illustrations of misjudgment has been laid out by Charlie Munger. Here is the excerpt link : https://fs.blog/great-talks/psychology-human-misjudgment/ He lays out a very comprehensive 25 Biases that ail decision making. Once again, stripping biases do not necessarily result in accuracy — it increases the variability of outcomes that might be clustered around a mean that might be closer to accuracy than otherwise.
Variability is Noise. We do not know a priori what the expected mean is. We are close, but not quite. There is noise or a whole set of outcomes around the mean. Viewing things closer to the ground versus higher would still create a likelihood of accepting a false hypothesis or rejecting a true one. Noise is extremely hard to sift through, but how you can sift through the noise to arrive at those signals that are determining factors, is critical to organization success. To get to this territory, we have eliminated the cognitive and statistical biases. Now is the search for the signal. What do we do then? An increase in noise impairs accuracy. To improve accuracy, you either reduce noise or figure out those indicators that signal an accurate measure.
This is where algorithmic thinking comes into play. You start establishing well tested algorithms in specific use cases and cross-validate that across a large set of experiments or scenarios. It has been proved that algorithmic tools are, in the aggregate, superior to human judgement – since it systematically can surface causal and correlative relationships. Furthermore, special tools like principal component analysis and factory analysis can incorporate a large input variable set and establish the patterns that would be impregnable for even System 2 mindset to comprehend. This will bring decision making toward the signal variants and thus fortify decision making.

The final element is to assess the time commitment required to go through all the stages. Given infinite time and resources, there is always a high likelihood of arriving at those signals that are material for sound decision making. Alas, the reality of life does not play well to that assumption! Time and resources are constraints … so one must make do with sub-optimal decision making and establish a cutoff point wherein the benefits outweigh the risks of looking for another alternative. That comes down to the realm of judgements. While George Stigler, a Nobel Laureate in Economics, introduce search optimization in fixed sequential search – a more concrete example has been illustrated in “Algorithms to Live By” by Christian & Griffiths. They suggested an holy grail response: 37% is the accurate answer. In other words, you would reach a suboptimal decision by ensuring that you have explored up to 37% of your estimated maximum effort. While the estimated maximum effort is quite ambiguous and afflicted with all of the elements of bias (cognitive and statistical), the best thinking is to be as honest as possible to assess that effort and then draw your search threshold cutoff.

An important element of leadership is about making calls. Good calls, not necessarily the best calls! Calls weighing all possible circumstances that one can, being aware of the biases, bringing in a diverse set of knowledge and opinions, falling back upon agnostic tools in statistics, and knowing when it is appropriate to have learnt enough to pull the trigger. And it is important to cascade the principles of decision making and the underlying complexity into and across the organization.
